浅谈一下个人基于IRIS后端业务开发框架的理解
现状
由于国内使用基于M语言IRIS平台几乎都在医疗行业。医疗系统又非常的庞大和复杂。前期由于快速占领市场,系统数量越来越多,到了临界点后就产生了质变,所以前期基于功能的线性开发注重效率,所以导致大量的产品业务代码有如下集中情况:
- 系统交互乱如麻,各系统的交互关系变成了网状。
- 系统规模庞大,内部耦合严重,牵一发而动全身,后续修改和扩展困难,开发效率低。
- 关键功能逻辑复杂,容易出现问题,出现问题后很难排查和修复,开发成本高。
- 功能越来越多,导致系统复杂度指数级上升。
- 重复造轮子,相似的功能不断重复开发。
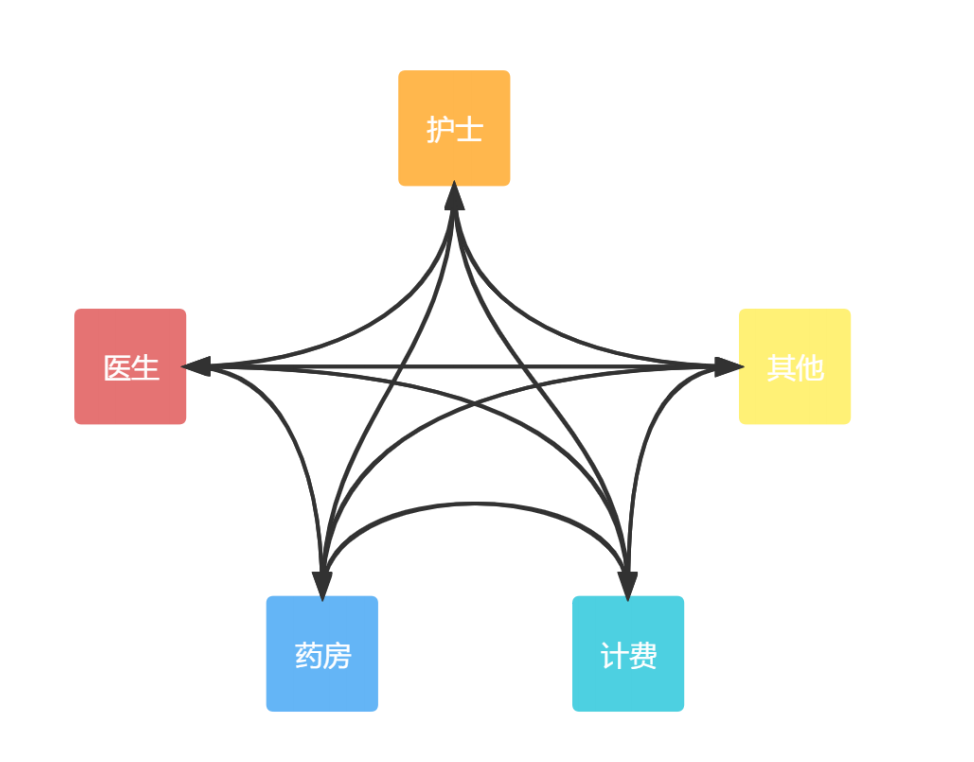
如上图所示,这仅仅是展示了五个模块之前的交互,在此基础上继续增加模块则复杂度成指数级上升,并且如果每个模块之间如果没有做好接口管理,维护起来也是地狱级别。
如何解决这个问题,一般会分为两派:优化派与架构派。
优化派的思想是将现有的系统优化。例如重构某个方法,优化某个SQL。优化派的优势是针对系统改动较小,可以保持系统的稳定性,可以快速实施,缺点是治标不治本,随着需求越来越多,增加的代码量越多,后期还是会撑不住。
架构派的核心思想是调整系统架构,将原来的大系统拆分为多个互相配合的小系统,例如药库系统拆分为,采购模块,订单模块,查询模块,分析模块等。架构派的优势是一次调整可以支撑比较长期的业务发展,缺点是动作较大,耗时较长,稳定性需要项目考验。
所以这是个长痛短痛的问题,相信很多公司在遇到这种情况时,大部分情况下优化派会赢,因为“优化”是最快、最稳定的方式。除非当前架构支撑不了当前业务的阶段,才会考虑重新架构。
复杂性的一个主要原因就是系统越来越庞大,业务越来越多。降低复杂性最好的方式就是“拆”,化整为零,分而治之,将整体复杂性分散到多个子业务或子系统里去。
基于此我们设计一个简单的接口隔离方案,模块之间交互一般都会抽离个接口类,使用中介者模式或门面模式思想设计:
- 门面模式:
每个模块之间,有单独的门面来专门处理接口,有效防止接口散布在模块内部的类中,起到接口隔离作用。
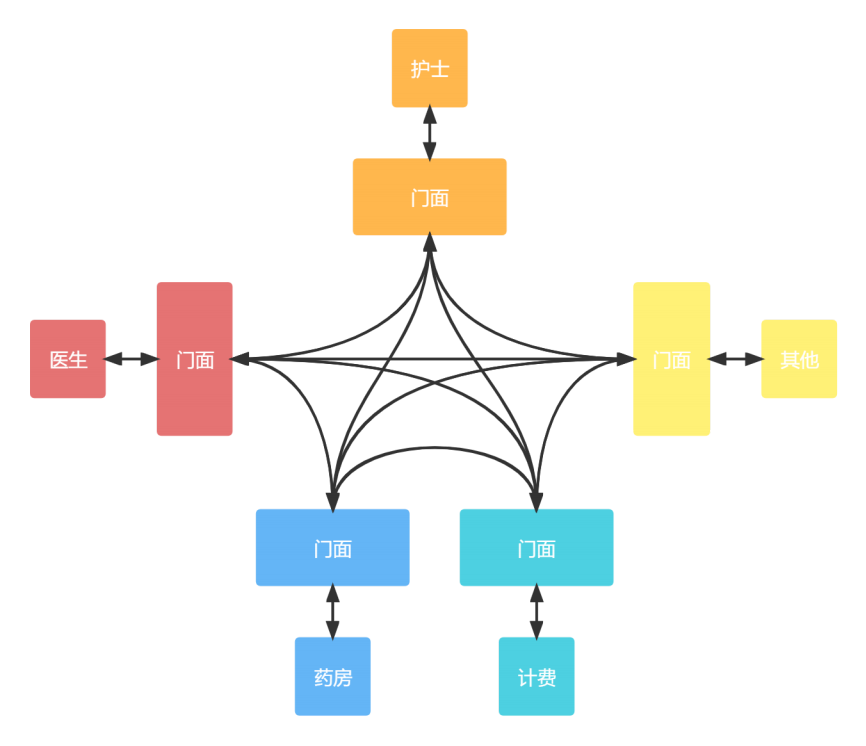
- 中介者模式:
因为模块之间交互频繁,随着模块的增加,接口越来越多,会导致中介者类越来越庞大。好处是可以统一做接口管理。

这里的门面类可以进步一划分为提供接口与调用接口,可以类比为读写分离。

以上是处理多模块之间的常规交互处理方案。
下面我想针对单独模块内部的功能业务进行一些探讨:
在现实环境中,我们不可能一开始就设计出一套完美的架构,都会随着业务的发展,暴露出的问题,在不断的的迭代中,保留优秀的设计,修复有缺陷的设计,逐渐完善。不断进行重构,所以没有一劳永逸的框架。
笔者也曾开发了一些产品,基于此有一些基于M语言IRIS后端的一些框架想法分享给大家。
热门的语言Java,Python等有各种成熟的框架。对比关于IRIS相关的开发框架也比较少。借助相关的框架学习其中的思想,设计出一套适合基于IRIS平台M开发语言的医疗行业系统的开发框架。
尽量把框架做到,适合、简单。
- 结合设计模式思想。
- 根据功能进行模块划分。
- 进行接口隔离,让产品、甚至功能做到高内聚,低耦合,可插拔。
方案
无论何种方案和框架,几乎都是为了一个统一的目标,让业务模块之间的耦合度尽量的低,做到可插拔,相互之间不影响,包括微服务,SOA。或者一些常见的架构MVC、MVP。其思想都是根据职责或业务划分成不同的模块。
我们以药库的,订单,采购,入库的业务功能为例,具体展示一下业务功能的一些划分。

下面我们就针对如上这张图每个模块类来进行讨论。
无论采取何种分层维度,分层架构设计最核心的一点就是需要保证各层之间的差异足够清晰,边界足够明显。否则如果两个层的差异不明显,就会出现程序员A认为某个功能应该放在A层,而程序员B认为同样的功能应该放在B层,这样就导致了分层混乱。如果这样的架构进入实际开发落地,则A层和B层就会乱成一锅粥,也就失去了分层的意义。
按照如上分层就能够较好地完成系统扩展,本质在于:隔离关注点。即每个层中的组件只会处理本层的逻辑。比如说,展示层只需要处理Api相关。业务层只需要处理业务逻辑。数据层只提供数据。SQL层只处理SQL。接口层只处理各种服务。这样我们拓展某层时,其他层是不受影响的,通过这种方式可以支持系统在某曾上的快读扩展。
按照上图功能划分,好处是在于将业务功能强制分层,依赖限定为两两依赖,降低了系统复杂度。但是分层结构的代码特点就是冗余,也就是说,不管这个业务有多么简单,每层都必须要参与处理,有时甚至调用一个接口,要通过类包装函数层层传递。
我们是否应该自由选择绕过分层的约束呢?答案是不建议这样做,因为在传统的代码当中,我们已经见识到当接口方法在各种类中相互调用,时间一长,架构就会变的混乱,牵一发动全身。除此之外,虽然分层架构的实现在某些场景下看起来有些烦琐和冗余,但复杂度却很低。也不会增加太多工作量。无非在类多添加几个引用。
这个方案的另外一个典型缺点就是性能,因为每一次业务功能请求有可能需要穿越多个接口层,多少都会有一些性能的浪费。当然,这里所谓的性能缺点只是理论上的分析,实际上带来的性能损失,可以忽略不计。有时了为了保证方法类接口的单一性,牺牲一些性能也是在所难免的,最常见的例子就是用Gloabl取数据比写SQL要快,但是SQL在语义上比GLoabl要明确一些,实际上0.00001与0.0001性能上的感知几乎没有。但这并也并非说写SQL一定比Global要好。要根据情况而定,例如复杂SQL有多个JOIN,这种性能肯定会很比Global要慢很多。
具体实现
借用MVP架构和微服务的思想,后台将按每个大模块进行划分,考虑数据抽离、可复用性、原子性、安全性等原则,模块内部建立不同类进行区分。
注:一旦遵守框架开发,需要严格执行,否则过不了多久,又会乱成一锅粥。在现实环境中,多人开发确实很难达到一致性。
Base
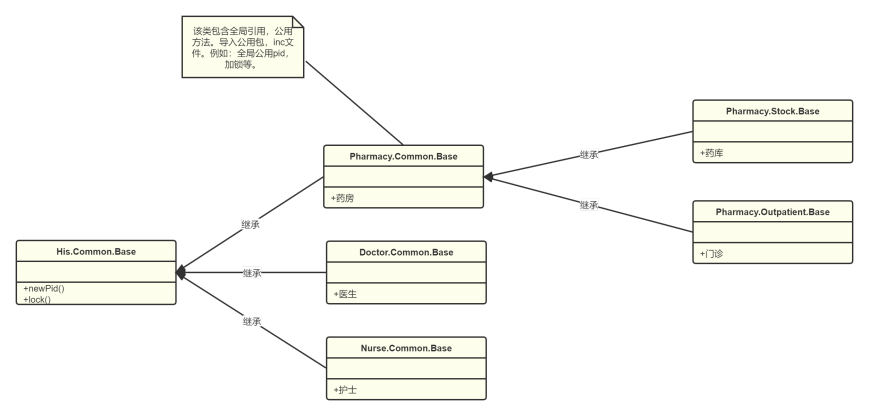
其中:
His.Common.Base- 作为整个医院业务模块最底层包,存放一些所有产品组都可以用的公方法或开关。例如:获取pid,获取院级锁方法,抽象出一写全局方法,编译自动备份方法等。Pharmacy.Common.Base- 其中Pharmacy作为His单独模块的包名,例如医生Doctor、护士Nurse、药房Medicine。该模块可以实现产品组级公共方法,实现His级的抽象方法,例如产品组级的锁。模块级的公共参数,字典变量等。Pharmacy.Stock.Base- 该层为产品组级下的产品线,例如药房包括药库Stock、门诊药房Outpatient等。该层可以实现产品线级的公共方法,实现Pharmacy.Common.Base的抽象方法等。例如产品线级的锁。- 其中所有的
BASE模块都可以包含对应层级的公用方法、公用包、inc文件,属性、参数、常量。每一个模块继承自己的上一级Base类。
注:可以把共有算法抽象到父类,子类写具体的模块的细节、模版方法模式。
代码示例:
His.Common.Base- 导入了通用包。例如:
SQL,Util。 - 全局的参数。例如:当前日期时间等。
- 定义抽象锁方法提子类重写。
- 导入了通用包。例如:
/// 导入公共表与工具类
Import (SQLUser, Util)
/// todo:引入院级inc文件
Include His.Common.Base
Class His.Common.Base Extends %RegisteredObject
{
/// todo:院级公共属性
/// todo:院级公共参数
/// todo:院级公共方法
Parameter sysDate = {+$h};
Parameter sysTime = {$p($h, ",", 2)};
ClassMethod NewPid() As %String
{
q $i(^HisPid)
}
ClassMethod Lock(lockName, lockTime) [ CodeMode = expression ]
{
..AbstractLock(lockName, lockTime)
}
ClassMethod AbstractLock(lockName, lockTime) [ Abstract ]
{
}
ClassMethod Unlock(lockName) [ CodeMode = expression ]
{
..AbstractUnlock(lockName)
}
ClassMethod AbstractUnlock(lockName) [ Abstract ]
{
}
}
Pharmacy.Common.Base- 实现模块级公用方法。此处为药房模块。
Class Pharmacy.Common.Base Extends His.Common.Base
{
/// todo:产品组模块公共属性
/// todo:产品组模块公共参数
/// todo:产品组模块公共方法
ClassMethod AbstractLock(lockName, lockTime)
{
l +^PharmacyLock(lockName):lockTime e q $$$NO
q $$$OK
}
ClassMethod AbstractUnlock(lockName)
{
l -^PharmacyLock(lockName)
q 0
}
}
Pharmacy.Stock.Base- 实现产品级公用方法。药房下药库产品。
Class Pharmacy.Stock.Base Extends Pharmacy.Common.Base
{
/// todo:产品线模块公共属性
/// todo:产品线模块公共参数
/// todo:产品线模块公共方法
ClassMethod AbstractLock(lockName, lockTime)
{
l +^PharmacyStockLock(lockName):lockTime e q $$$NO
q $$$OK
}
ClassMethod AbstractUnlock(lockName)
{
l -^PharmacyStockLock(lockName)
q 0
}
}
His.Common.Base.inc- 全局通用的
inc文件。关于inc文件的使用可以参考百讲宏的使用.
- 全局通用的
#define HIS "HIS"
Biz
传统方式里我们习惯按建立的表类来写业务,这种方式的问题是当有主子表时我们的业务逻辑过于分散,一般主子表的业务操作都是联动的。所以我们可以根据业务的属性来划分到一个Biz里,这样做提高了内聚的属性。
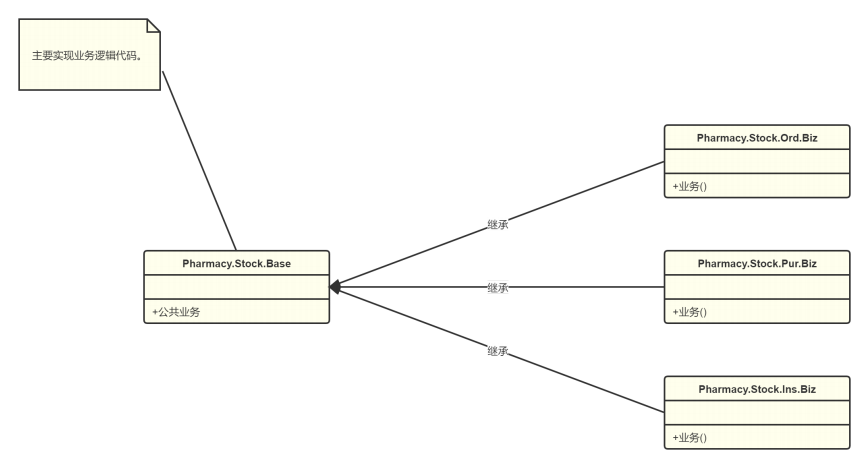
- 实现业务的主要逻辑代码,此类中不应包含具体的
SQL语句、详细的过滤条件、复杂算法等。 Pharmacy.Stock.Ord.Biz- 实现该药库下订单模块的业务逻辑。Biz的方法,应按照六大原则来书写,单独的功能抽离方法,业务方法应该是单一原则的方法嵌套。
Class Pharmacy.Stock.Ord.Biz Extends Pharmacy.Stock.Base
{
/// 保存订单主表业务逻辑
ClassMethod SaveMain(params)
{
//todo:过滤条件
q:(##class(Filter).IsSave()) $$$ERROR($$$GeneralError, "没有保存")
q:(##class(Filter).IsAuit()) $$$ERROR($$$GeneralError, "没有通过审核")
q:(##class(Filter).IsExist()) $$$ERROR($$$GeneralError, "不存在")
//todo: 插入sql
s id = ##class(Sql).SaveMain()
q id
}
/// 保存订单子表业务逻辑
ClassMethod SaveDetail(params)
{
//todo:过滤条件
q ##class(Sql).SaveDetail()
}
/// 返回多条数据
ClassMethod Query(params)
{
}
/// 返回单条数据
ClassMethod QueryById(params)
{
q ##class(Data).GetMainData()
}
}
Pharmacy.Stock.Base- 药库基本都涉及到保存主子表所以可以根据自己产品的需求抽象出一些公用方法,供其他功能模块重写。
Class Pharmacy.Stock.Base Extends Pharmacy.Common.Base
{
/// 公共保存方法
ClassMethod Save(params)
{
// todo:算法,过滤条件
#; 保存主算
s ret = ..SaveMain(params)
// todo:算法,过滤条件
#; 保存明细数据
s ret = ..SaveDetail(params)
q $$$OK
}
/// 抽象保存主表算法
ClassMethod SaveMain(params) [ Abstract ]
{
}
/// 抽象保存子表算法
ClassMethod SaveDetail(params) [ Abstract ]
{
}
}
Data

在传统的书写习惯里可以看到几乎每个索引查询都会单独写一遍取数据。而且取数据的查询方法散布了很多类里。在后期维护时非常费时费力。所以每个业务模块都应有自己的Data类,取数据时都在统一的Data类里去取,目的是提高数据复用性。
- 为
Biz类返回数据,是模块内获取详细数据的唯一类,数据以动态JSON形式传递,抽离取值、提高复用。
注意:动态JSON非常的高效方便。
代码示例:
Pharmacy.Stock.Ord.Data
Class Pharmacy.Stock.Ord.Data Extends %RegisteredObject
{
/// 获取主数据
ClassMethod GetMainData(id)
{
s data = ^OrdD(id)
s ret = {}
s ret.no = $lg(data, 1)
s ret.createUserName = $lg(data, 2)
s ret.finished = "Y"
q ret
}
/// 获取明细数据
ClassMethod GetDetailData(id)
{
s data = ^OrdD(+id, "I", $p(id,"||",2))
s ret = {}
s ret.name = $lg(data, 1)
s ret.code = $lg(data, 2)
s ret.desc = $lg(data, 3)
q ret
}
}
注意:这里一定要区分好哪些是业务模块数据,哪些是公用数据,如果是公用数据不要放到业务模块数据里,要提到产品级的公用数据,依次类推。
例如:取登录人名称,登录人代码,就要去上一级的公共数据取。
Pharmacy.Stock.Ord.Data 的上一级Pharmacy.Stock.Common.Data存放药库级的公用数据。这里不应该放入取登录人方法。应该再次往上找Pharmacy.Common.Data,这里存放药房公用数据。实际上这里也不应该存放登录人方法,但是实际上每个产品组都是互为独立,大多数都把取登录人的方法放到这里。实际上应该放到His.Common.Data。
His.Common.Data
Class His.Common.Data Extends %RegisteredObject
{
/// desc: 获取登录用户ID
ClassMethod GetUserId()
{
q:'$d(%session) ""
q:'$d(%session.Data("login.user.id")) ""
s data = %session.Data("login.user.id")
q data
}
/// desc: 获取登录用户ID
ClassMethod GetUsername()
{
q:'$d(%session) ""
q:'$d(%session.Data("login.user.name")) ""
s data = %session.Data("login.user.name")
q data
}
}
注:取数据类包保持单一原则,做到取desc、code、id等数据时。可以直接取数据,而不是取到id再去根据id取对应Global做转换。
当遇到方法不知道放到哪里时,应该咨询有经验的组里资深程序员。
Filter

在传统的书写代码中,几乎看不到为专门的过滤条件建立的类,每次写业务逻辑时,尤其在循环中过滤条件都会复写一次,在字段过滤中最为明显,每次先查表找到过滤字段的位置,再取过滤字段,然后判断该字段是否满足条件,满足则过滤。
这种方式的问题很明显,每次过滤时查表费时费力,字段位置容易出错,大量的重复判断代码,当数据库字段有变动时,每个地方都需要改。而且一个业务可能会出现多个过滤条件,写新业务时可能会遗漏过滤条件。其他产品需要判断过滤条件时无接口可提供,往往是通过口头的方式告知这个表哪个字段为Y时过滤,他人还得需要再取一次。
为Biz类提供条件过滤,优先考虑返回布尔类型结果。类中方法要保持原子性(不可拆分),只拓展不修改,提高复用,复杂过滤条件通过的单个方法组合的形式实现。注意保持单一原则,相同条件只允许有一个。
Class Pharmacy.Stock.Ord.Filter Extends %RegisteredObject
{
/// desc:判断是否保存
ClassMethod IsSave(ID As %Integer) As %Boolean
{
s compFlag = $p(^OrdD(ID ), "^", 4)
q:(compFlag = "Y") $$$YES
q $$$NO
}
/// desc:判断是否审核
ClassMethod IsAuit(ID As %Integer) As %Boolean
{
s aduitFlag = $p(^OrdD(ID ), "^", 5)
q:(aduitFlag = "Y") $$$YES
q $$$NO
}
/// desc: 判断是否存在
ClassMethod IsExist(ID As %String) As %Boolean
{
s id = $p(^OrdD(ID), "^", 6)
q:(id '= "") $$$YES
q $$$NO
}
/// desc: 是否允许
ClassMethod IsAllow(ingr As %String) As %Boolean
{
q:..IsSave(ingr) $$$YES
q:..IsAuit(ingr) $$$YES
q:..IsExist(ingr) $$$YES
q $$$NO
}
}
通过过滤条件的组合的好处是。为某个业务提供过滤时,我们仅提供组合好的接口即可,例如入库复杂的业务,需要考虑很多条件。这里只需要提供一个组合好的过滤接口,方便高效。
注意:这里一定要区分好哪些过滤条件是功能级别、产品线级别、模块组级别、全院级别。
Sql

传统类中SQL语句,我们可以发现有很多的相同的业务SQL语句散落在各个类中,也可以看到不同的方法有相同的SQL语句,这种碎片化的SQL语句有很多,也非常不好管理。所以可以根据小三层的思想把SQL语句放到专门的SQL类里,这样既增强了SQL语句的复用,也方便管理该业务下的所有相关SQL语句。当有新功能时,可以一览所有已有SQL,避免重复开发。
如果想避免重复的大量的简单SQL,可以参考这篇文章 只需要改造一下实体类,以后再也不用写SQL了
注意:后续对于数据操作都将仅仅存在SQL一种形式,不再使用对象存储。
Class Pharmacy.Stock.Ord.Sql Extends %RegisteredObject
{
ClassMethod SaveMain(params)
{
//todo: sql
}
ClassMethod SaveDetail(params)
{
//todo: sql
}
ClassMethod Delete(params)
{
//todo: sql
}
ClassMethod Update(params)
{
//todo: sql
}
ClassMethod Insert(params)
{
//todo: sql
}
}
Imp、Ref
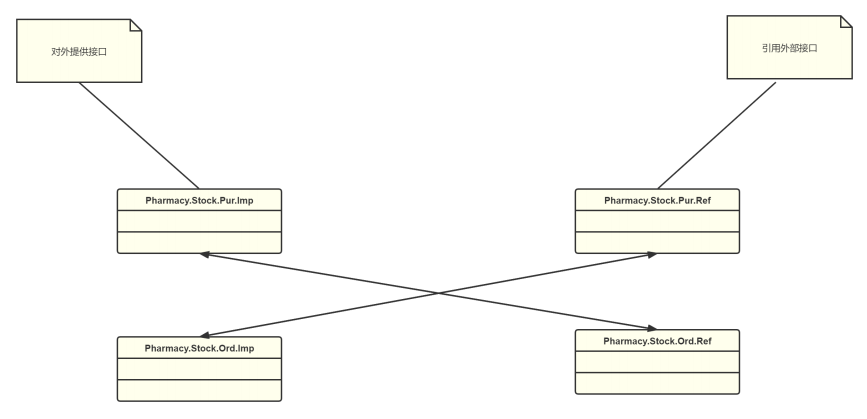
我们这里把接口分为了提供接口Imp与引用接口Ref,顾名思义Imp为对外的的接口,Ref为对内引用的第三方接口。
这样做的好处是隔离了功能模块间的耦合度,也统一了接口管理。接口做到了功能模块级,对于功能模块可以做到单独部署,统一了内外部引用,借用了微服务思想。
否则在传统模式下接口可能会散落在各个类中,接口级的管理顶多做到了产品组级。功能模块内部耦合严重。
模块向其他模块提供访问的接口类,所有业务模块之间的访问都应通过Imp、Ref类访问,模块间应保持独立性,尽可能降低依赖关系,降低业务间耦合度。此类不具备具体业务逻辑。
迪米特法则:如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
Pharmacy.Stock.Ord.Imp- 例如对外提供接口判断订单是否存在。只需要引用
Filter类即可。
- 例如对外提供接口判断订单是否存在。只需要引用
Class Pharmacy.Stock.Ord.Imp Extends %RegisteredObject
{
// todo:对外提供接口
/// desc: 对外提供接口是否存在
ClassMethod IsOrdExist(ID As %String) [ CodeMode = expression ]
{
##class(Pharmacy.Stock.Ord.Filter).IsExist()
}
}
- Pharmacy.Stock.Ord.Ref
- 引用外部接口判断入库是否存在。
Class Pharmacy.Stock.Ord.Ref Extends %RegisteredObject
{
// todo:引用外部接口
/// desc: 引用外部接口,判断入库单是否存在
ClassMethod IsOrdExist(ID As %String) [ CodeMode = expression ]
{
##class(Pharmacy.Stock.Ins.Imp).IsInsExist()
}
}
Api

仅供前端直接访问的接口类,借用设计模式门面的思想。前端不允许访问除Api类之外的任何其他类方法,减少耦合度,针对接口编程。
Api可选择直接调用Biz方法,亦可覆写。对于前台需要的特殊格式的Json,Xml,可以统一做转换。
Class Pharmacy.Stock.Ord.Api Extends Pharmacy.Stock.Ord.Biz
{
/// desc:查询明细
ClassMethod Query() [ CodeMode = expression ]
{
##super()
}
/// desc:根据保存单据
ClassMethod QueryById(params As %String) [ CodeMode = expression ]
{
##super(params)
}
}
注:这里应该当区分Api类与接口Imp、Ref的区别。Api是供前端调用的接口例如给web,android,ios这些前端提供的数据接口。Imp、Ref为模块之间调用的数据接口。
Util

这里把Util类单独拿出来说,是因为防止重复造轮子,例如国密算法,每个组都可能用到,难道每个组都要去自己去实现吗?简单的还好,复杂的无疑增加了时间成本。
这里一定要明确Util类的概念,不包含任何业务逻辑方法,数据,过滤条件。与业务相关的,不能放到Util类里。Uti类更多是针对与编程方面,获取环境变量,公用算法等。
Util类是单独的包,面相所有产品,功能,模块的类,不通过接口来外部引用。这也说明了Util类一旦公布就只允许拓展,不允许修改。
传统的方式是,每个产品组各自为营,个搞个的,或者说压根就没有工具类,用到时在业务里随便复制粘贴个方法做为引用。所以就造成单个类,什么方法都有。
非常重要的一点是,工具类新增方法要定期公示,否则其他开发人员并不知道工具类有什么方法,或者建立索引文档提供查找。
总结
系统重构是大动作,持续是加比较长,而且会占用一定的资源,开发和测试。花费大量的沟通成本。
一旦决定重构,一开始就制定好各种规范,每个人都严格遵守。把解决的问题根据优先级、重要性。实施难度划分、
重构时可以遵循先易后难原则,这也是笔者的的一个重要体会。因为如果先攻克最难的问题,往往都耗时比较长,可能一两个月都没有什么进展和成果,会影响相关人员对项目的评价和看法,更会打击自信心。最后,刚开始的分析并不一定全面,所以一开始对最难的或最关键的是问题的判断可能会出错。
采取先易后难能够比较快速地看到成果,对后续项目的推进与提升士气有很大的好处。随着项目的进行,原来遗漏的点,或者分析和判断错误的点,会逐渐显示出来,到最后最难的问题也许迎刃而解。
以上是针对医疗领域与后端的一些业务开发框架的个人想法,现在回过头来看,感觉是理所当然,但实际上当时做分析和决策时远远没有这么简单。
以上是个人对基于IRIS后端的医疗框架理解,由于个人能力有限,欢迎大家提出意见,共同交流。

 那我们想要定义自己的参数,该如何定义呢?根据面向对象设计原则之一:
那我们想要定义自己的参数,该如何定义呢?根据面向对象设计原则之一:
.png)
.png)