第二章 定义和构建索引(一)
概述
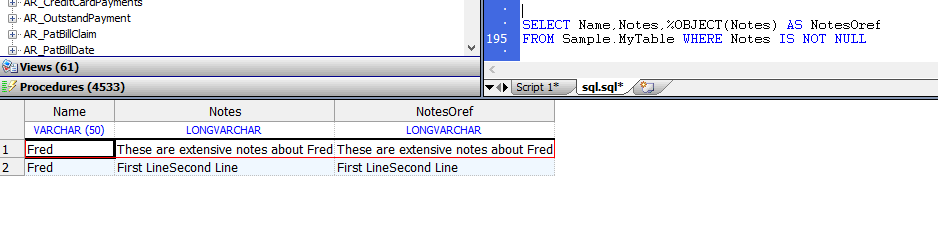
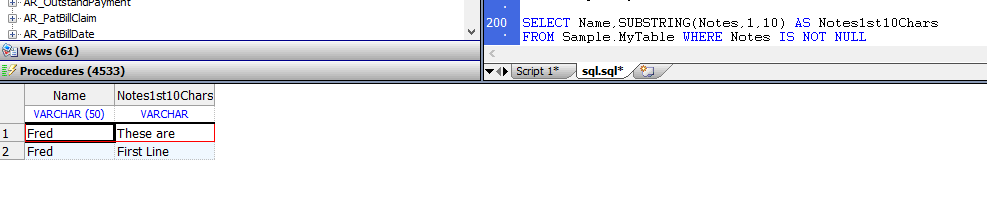
索引是由持久类维护的结构,InterSystems IRIS®数据平台可以使用它来优化查询和其他操作。
可以在表中的字段值或类中的相应属性上定义索引。(还可以在多个字段/属性的组合值上定义索引。)。无论是使用SQL字段和表语法还是类属性语法定义相同的索引,都会创建相同的索引。当定义了某些类型的字段(属性)时,InterSystems IRIS会自动定义索引。可以在存储数据或可以可靠派生数据的任何字段上定义附加索引。InterSystems IRIS提供了几种类型的索引。可以为同一字段(属性)定义多个索引,为不同的目的提供不同类型的索引。
无论是使用SQL字段和表语法,还是使用类属性语法,只要对数据库执行数据插入、更新或删除操作,InterSystems IRIS就会填充和维护索引(默认情况下)。可以覆盖此默认值(通过使用%NOINDEX关键字)来快速更改数据,然后作为单独的操作生成或重新生成相应的索引。可以在用数据填充表之前定义索引。还可以为已经填充了数据的表定义索引,然后作为单独的操作填充(构建)索引。
InterSystems IRIS在准备和执行SQL查询时使用可用的索引。默认情况下,它选择使用哪些索引来优化查询性能。 可以根据需要覆盖此默认值,以防止对特定查询或所有查询使用一个或多个索引。
索引属性
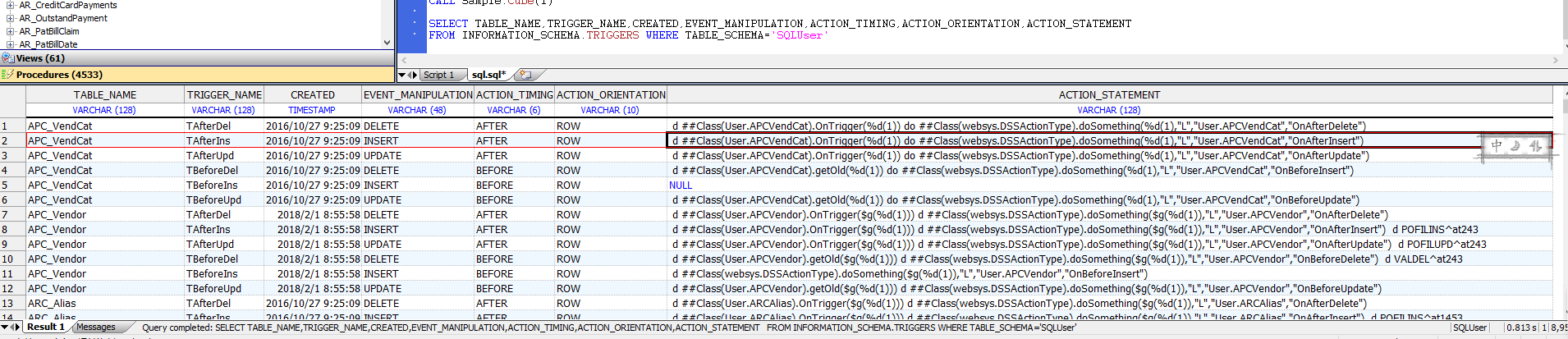
每个索引都有一个唯一的名称。此名称用于数据库管理目的(报告、索引构建、删除索引等)。与其他SQL实体一样,索引同时具有SQL索引名和相应的索引属性名;这些名称在允许的字符、区分大小写和最大长度方面有所不同。如果使用SQL CREATE INDEX命令定义,系统将生成相应的索引属性名称。如果使用持久类定义进行定义,则SqlName关键字允许用户指定不同的SQL索引名(SQL映射名称)。 Management Portal SQL界面的Catalog Details显示每个索引的SQL索引名称(SQL映射名称)和相应的索引属性名称(索引名称)。
索引类型由两个索引类关键字Type和Extent定义。IRIS提供的索引类型包括:
- 标准索引(
Type = index)——一个持久数组,它将索引值与包含该值的行的 RowID相关联。 任何没有明确定义为位图索引、位片索引或区段索引的索引都是标准索引。 - 位图索引(
Type = Bitmap)——一种特殊的索引,使用一系列位字符串来表示与给定索引值对应的RowID值集; InterSystems IRIS包括许多位图索引的性能优化。 - 位片索引(
Type = Bitslice)——一种特殊的索引,能够非常快速地计算某些表达式,例如总和数和范围条件。 某些SQL查询自动使用位片索引。 - 区段索引(
Extent Indices)——一个区段中所有对象的索引。 有关更多信息,请参阅类定义参考中的区段索引关键字页。 - 范围索引-范围中所有对象的索引。
表(类)的最大索引数为400。
存储类型和索引
这里描述的索引功能适用于存储在持久化类中的数据。
InterSystems SQL支持使用InterSystems IRIS默认存储结构存储的数据的索引功能:%Storage.Persistent(%Storage.Persistent映射类)。
InterSystems SQL还支持使用%Storage.SQL(%Storage.SQL映射的类)存储的数据的索引功能。可以使用函数索引类型为%Storage.SQL映射的类定义索引。索引的定义方式与使用默认存储的类中的索引相同,但有以下特殊注意事项:
- 如果
IdKey函数索引不是系统自动分配的,则该类必须定义IdKey函数索引。 - 此功能索引必须定义为索引。
请注意,不应直接调用%Storage.Persistent和%Storage.SQL类方法。相反,应该使用%Persistent类方法和本章中描述的操作调用索引功能。
索引全局名称
使用以下两种策略之一生成用于存储索引数据的下标全局:
%CLASSPARAMETER USEEXTENTSET=0使用全局命名策略创建由用户指定的名称、附加的字母代码和索引名称组成的“传统”全局名称。用户可以理解这些全局名称,但它们可能很长,并且效率低于散列的全局名称。- 如果
USEEXTENTSET=0且未指定DEFAULTGLOBAL,则以下示例将描述生成的全局名称:Sample.MyTest持久类将定义名为^Sample.MyTestD的master map全局名^Sample.MyTestD位图范围索引全局名^Sample.MyTestI(“$MyTest”)(或^Sample.MyTestI(“DDLBEIndex”)),并且对于定义的索引NameIDX,它将定义名为^Sample.MyTestI(“DDLBEIndex”)的全局名。请注意,这些全局变量指定的是持久性类名(区分大小写),而不是SQL表名。 - 如果
USEEXTENTSET=0并指定了DEFAULTGLOBAL,则指定的全局名称将替换永久类名。这允许指定一个比持久类名称更短或更清晰的名称。例如,如果DEFAULTGLOBAL=“MyGlobal”,则全局变量的名称如下:^MyGlobalD和^MyGlobalI(“NameIDX”)。
- 如果
%CLASSPARAMETER USEEXTENTSET=1使用创建哈希全局名称的全局命名策略。这包括对包名进行散列,对类名进行散列,然后追加一个点和一个标识索引的连续整数后缀。这些全局名称对用户来说不太容易理解,但往往更短、效率更高。
整数后缀仅作为索引名的关键字;与索引名和索引类型相关联的字段对整数编号没有影响。例如,^EW3K.CgZk.1 是 Master Map,^EW3K.CgZk.2是位图范围(Bitmap Extent),^EW3K.CgZk.3是LastName字段的已定义标准索引NameIDX,^EW3K.CgZk.4是已定义索引WorkIdIDX。如果删除NameIDX,则全局^EW3K.CgZk.3也会被删除,从而在整数序列中产生间隙。如果为LastName字段定义LNameIDX,则会创建全局^EW3K.CgZk.5;但是,如果稍后为FullName字段创建位图索引NameIDX,则全局索引将再次为^EW3K.CgZk.3。
- 如果
USEEXTENTSET=1并且未指定DEFAULTGLOBAL,则包名和类名将被散列,如上所述。将追加连续的整数后缀。 - 如果
USEEXTENTSET=1并指定了DEFAULTGLOBAL,则使用DEFAULTGLOBAL名称,而不是散列的包名和类名。将追加连续的整数后缀。例如,如果DEFAULTGLOBAL="MyGlobal",则全局变量的名称如下:^MyGlobal.1和^MyGlobal.3
如果使用CREATE TABLE命令定义表,则USEEXTENTSET默认为1。因此,默认情况下,CREATE TABLE创建散列全局名称。可以使用%CLASSPARAMETER关键字以及USEEXTENTSET和DEFAULTGLOBAL参数更改此默认行为。可以使用$SYSTEM.SQL.Util.SetOption()方法在系统范围内更改此默认设置。
SET status=$SYSTEM.SQL.Util.SetOption("DDLUseExtentSet",0,.oldval).
如果定义投影到表的持久类,则USEEXTENTSET默认为0。因此,默认情况下,使用传统的全局名称。
DEFAULTGLOBAL(如果已定义)将作为默认值。如果定义了ExtentLocation、DataLocation或IndexLocation存储关键字,则使用这些值,而不是上述默认值。
可以向ZWRITE提供全局名称以显示索引数据。
Master Map
系统自动为每个表定义一个主图(Data/Master)。Master Map不是索引,它是使用其Map下标字段直接访问数据本身的Map。默认情况下,Master Map下标字段是系统定义的RowID字段。默认情况下,使用RowID字段进行的这种直接数据访问由SQL映射名称(SQL索引名称)IDKEY表示。
默认情况下,用户定义的主键不是IDKEY。这是因为使用RowID整数查找 Master Map总是比使用主键值查找效率更高。 但是,如果指定主键为IDKEY,则主键索引被定义为表的主映射,SQL映射名称为主键SQL索引名。
对于单字段key/IDKEY,,主键索引是主映射,但主映射数据访问列仍然是RowID。这是因为在记录的唯一主键字段值和其RowID值之间存在一对一的匹配,而RowID被认为是更高效的查找。对于多字段主键/IDKEY,会为Master Map指定主键索引名称,并且Master Map Data Access列是主键字段。
可以通过Management Portal SQL Catalog Details(管理门户SQL目录详细信息)选项卡查看主图定义。除其他项目外,它还显示存储Master Map数据的全局名称。对于SQL和默认存储,此主映射全局默认为^Package.classnameD,并记录命名空间以防止歧义。对于自定义存储,未定义主地图数据存储全局名称;可以使用DATALOCATIONGLOBAL类参数指定数据存储全局名称。
对于SQL和默认存储,主映射数据存储在下标全局名为^package.classnameD 或 ^hashpackage.hashclass.1。请注意,全局名指定持久类名,而不是相应的SQL表名,并且全局名区分大小写。可以向ZWRITE提供全局名称以显示Master Map数据。
使用Master Map访问数据效率很低,尤其是对于大型表。因此,建议用户定义可用于访问WHERE条件、联接操作和其他操作中指定的数据字段的索引。
自动定义的索引
定义表时,系统会自动定义某些索引。在为表格定义并在添加或修改表数据时,自动生成以下索引。如果定义:
- 不是
IDKEY的主键,则系统会生成唯一类型的相应索引。主键索引的名称可以是用户指定的,也可以是从表名派生的。例如,如果定义一个未命名的主键,则相应的索引将命名为tablenamePKEY#,其中#是每个UNIQUE和PRIMARY KEY约束的顺序整数。 - 唯一的字段,Intersystems Iris为每个唯一字段生成索引,其中名称T
ableNameUnique#,其中#是每个唯一和主键约束的顺序整数。 - 唯一约束,系统为每个具有指定名称的唯一约束生成索引,为共同定义唯一值的字段编制索引。
- shard key,系统在shard key字段上生成一个索引,命名为
ShardKey。
可以通过Management Portal SQL Catalog Details选项卡查看这些索引。CREATE INDEX命令可用于添加唯一字段约束;DROP INDEX命令可用于删除唯一字段约束。
默认情况下,系统在RowID字段上生成IDKEY索引。定义身份字段不会生成索引。但是,如果定义标识字段并将该字段作为主键,则InterSystems IRIS将在标识字段上定义IDKEY索引并将其作为主键索引。下面的示例显示了这一点:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentPK PRIMARY KEY (StudentID) )
同样,如果定义标识字段并为该字段提供唯一约束,则InterSystems IRIS将在标识字段上显式定义IdKey/Unique索引。下面的示例显示了这一点:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentU UNIQUE (StudentID) )
这些标识索引操作仅在没有明确定义的idkey索引时出现,并且表不包含任何数据。
位图范围索引
位图范围索引是表的行的位图索引,而不是针对表的任何指定字段。在位图范围索引中,每个位表示顺序ROWID整数值,并且每个位的值指定相应的行是否存在。
SQL使用此索引来提高Count(*)的性能,返回表中的记录数(行)。
一个表最多可以有一个位图区段索引。创建多个位图范围索引导致SQLCode -400错误。 其中 ERROR #5445: Multiple Extent indices defined:DDLBEIndex.
所有使用CREATE TABLE定义的表都会自动定义位图区段索引。
将此自动生成的索引分配索引名称(索引属性名称)DDLBEIndex和SQL MapName (SQL索引名称)%%DDLBEIndex。
定义为类的表可以有一个位图区索引,索引名和$ClassName的SQL MapName(其中ClassName是表的持久化类的名称)。
可以使用带有BITMAPEXTENT关键字的CREATE INDEX命令将位图区段索引添加到表中,或者重命名自动生成的位图区段索引。
可以通过管理门户SQL Catalog详细选项卡查看表的位图范围索引。虽然表只有一个位图范围索引,但是从另一个表中继承的表在其自身位图范围索引和它从其扩展的表中的位图范围索引中列出。例如,Sample.employee表扩展了Sample.person表;在目录详细信息映射 Sample.Employee列出$Employee 和 $Person Bitmap范围索引。
在经历许多删除操作的表格中,位图范围索引的存储可以逐渐变得效率较低。可以通过选择表的“目录详细信息”选项卡,“映射”选项和选择重建索引来重建从管理门户中重建位图范围索引。
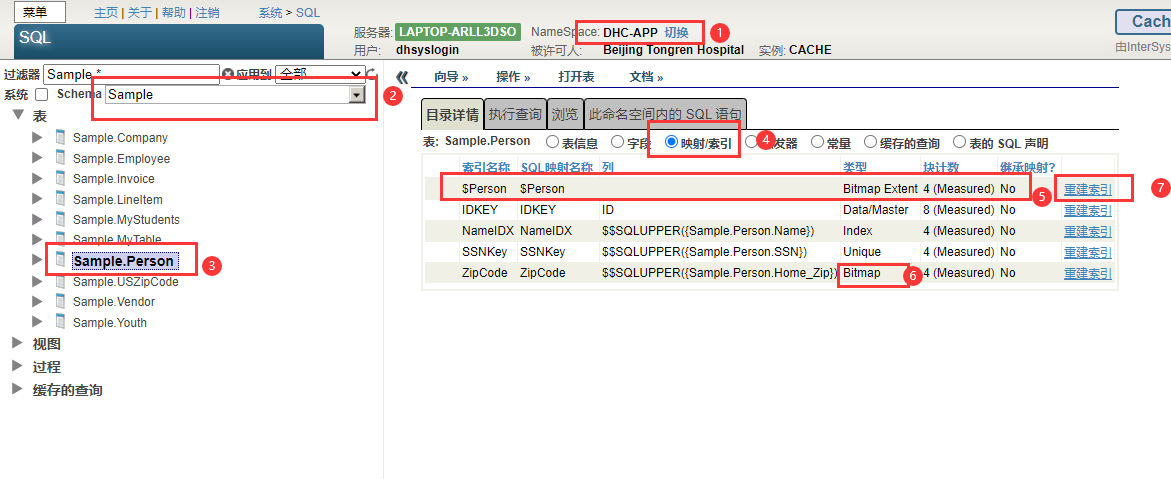
%SYS.Maint.Bitmap实用程序方法压缩位图范围索引,以及位图指数和bitslice索引。
在以下任何情况下,调用%BuildIndices()方法都会构建现有的位图范围索引:未指定%BuildIndices() pIndexList参数(构建所有定义的索引);pIndexList按名称指定位图范围索引;或pIndexList指定任何定义的位图索引。
定义索引
使用类定义定义索引
在Studio中,可以使用新建索引向导或通过编辑类定义的文本将索引定义添加到%Persistent类定义。索引在一个或多个索引属性表达式上定义,后跟一个或多个可选索引关键字(可选)。它采用以下形式:
INDEX index_name ON index_property_expression_list [index_keyword_list];
index_name是有效的标识符。index_property_expression_list是一个或多个以逗号分隔的属性表达式的列表,它们作为索引的基础。index_keyword_list是一个可选的索引关键字列表,用逗号分隔,用方括号括起来。 用于指定位图或位片索引的索引类型。 也用于指定唯一的、IdKey或PrimaryKey索引。 (根据定义,IdKey或PrimaryKey索引也是唯一索引。) 索引关键字的完整列表出现在类定义引用中。
index_property_expression_list参数由一个或多个索引属性表达式组成。
索引属性表达式包括:
- 要建立索引的属性的名称。
- 可选(元素)或(键)表达式,提供对集合子值进行索引的方法。
如果
index属性不是一个集合,用户可以使用BuildValueArray()方法生成一个包含键和元素的数组。 - 可选的排序规则表达式。
它包含一个排序规则名称,后面可选地跟着一个或多个以逗号分隔的排序规则参数列表。
不能为惟一索引、
IdKey索引或PrimaryKey索引指定索引排序规则。 唯一索引或PrimaryKey索引从正在建立索引的属性(字段)中获取其排序规则。IdKey索引总是精确(EXACT)的排序。
例如,下面的类定义定义了两个属性和一个基于它们的索引:
Class MyApp.Student Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property GPA As %Decimal;
Index NameIDX On Name;
Index GPAIDX On GPA;
}
更复杂的索引定义是:
Index Index1 On (Property1 As SQLUPPER(77), Property2 AS EXACT);
可以建立索引的属性
唯一可以被索引的属性是:
- 那些存储在数据库中的
- 那些可以从存储的属性可靠地派生出来的
必须使用SQLComputed关键字定义可以可靠地派生(并且未存储)的属性; SQLComputeCode指定的代码必须是导出属性值的唯一方法,并且无法直接设置属性。
如果可以直接设置一个派生属性的值,比如是一个简单的情况下(non-collection)属性定义为瞬态和不也定义为计算,然后直接设置属性的值将覆盖SQLComputeCode中定义的计算和存储的值不能可靠地来自属性;
这种类型的派生属性称为不确定性。(计算的关键字实际上意味着没有分配实例内存。)
一般规则是,只有定义为calculate和SQLComputed的派生属性才能被索引。
但是,派生集合有一个例外:派生的(SQLComputed)集合是暂时的(没有存储)集合,也没有定义为计算的集合(意味着没有实例内存)可以被索引。
注意:IdKey索引所使用的任何属性的值内都不能有连续的一对竖条(||),除非该属性是对持久类实例的有效引用。
这个限制是InterSystems SQL内部机制所要求的。
在IdKey属性中使用||会导致不可预知的行为。
多个属性的索引
可以在两个或多个属性(字段)的组合上定义索引。在类定义中,使用索引定义的ON子句指定属性列表,例如:
Class MyApp.Employee Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Salary As %Integer;
Property State As %String(MAXLEN=2);
Index MainIDX On(State,Salary);
}
如果需要执行使用字段值组合的查询,例如:
SELECT Name,State,Salary
FROM Employee
ORDER BY State,Salary
索引排序
唯一索引、PrimaryKey索引或IdKey索引不能指定排序规则类型。
对于其他类型的索引,索引定义中指定的每个属性都可以有一个排序规则类型。
应用索引时,索引排序类型应与属性(字段)排序类型匹配。
- 如果索引定义包含为属性显式指定的排序规则,则索引使用该排序规则。
- 如果索引定义不包括为属性显式指定的排序规则,则索引使用属性定义中显式指定的排序规则。
- 如果属性定义不包括显式指定的排序规则,则索引使用属性数据类型的默认排序规则。
例如,Name属性被定义为字符串,因此在默认情况下具有SQLUPPER排序规则。
如果在Name上定义一个索引,默认情况下,它接受属性的排序规则,索引也将使用SQLUPPER定义。
属性排序和索引排序匹配。
但是,如果比较应用不同的排序规则,例如,WHERE %EXACT(Name)=%EXACT(:invar),则此用法中的属性排序规则类型不再与索引排序规则类型匹配。属性比较排序规则类型与索引排序规则类型之间的不匹配可能会导致不使用索引。因此,在这种情况下,可能希望为具有精确(EXACT)排序规则的Name属性定义索引。如果JOIN语句的ON子句指定了排序规则类型,例如,FROM Table1 LEFT JOIN Table2 ON %EXACT(Table1.Name) = %EXACT(Table2.Name),此处指定的属性排序类型与索引排序类型不匹配可能导致InterSystems IRIS不使用该索引。
以下规则控制索引和属性之间的排序规则匹配:
- 匹配的排序规则类型总是最大限度地使用索引。
- 排序规则类型不匹配,其中属性指定为精确的排序规则(如上所示),并且索引有一些其他的排序规则,允许使用索引,但是它的使用不如匹配排序类型有效。
- 排序规则类型不匹配,其中属性排序规则不准确,属性排序规则不匹配索引排序规则,这将导致不使用索引。
要在索引定义中显式地为属性指定排序规则,语法如下:
Index IndexName On PropertyName As CollationName;
IndexName是索引的名称PropertyName是被索引的属性CollationName是用于索引的排序规则的类型
例如:
Index NameIDX On Name As Exact;
不同的属性可以有不同的排序规则类型。
例如,在下面的例子中,F1属性使用SQLUPPER排序,而F2使用EXACT排序:
Index Index1 On (F1 As SQLUPPER, F2 As EXACT);
注意:指定为Unique、PrimaryKey或IdKey的索引不能指定索引排序规则。
索引从属性collations中获取其collation。