概述
此版本重点聚焦于多个InterSystems云服务在升级可靠性、安全功能扩展以及支持体验优化方面的提升。通过该版本,包括 FHIR Server、InterSystems Data Fabric Studio (IDS)、IDS with Supply Chain 和 IRIS Managed Services 在内的所有主要产品,现均支持高级安全功能,从而提供了统一且增强的安全态势。
新功能和增强功能
概述
此版本重点聚焦于多个InterSystems云服务在升级可靠性、安全功能扩展以及支持体验优化方面的提升。通过该版本,包括 FHIR Server、InterSystems Data Fabric Studio (IDS)、IDS with Supply Chain 和 IRIS Managed Services 在内的所有主要产品,现均支持高级安全功能,从而提供了统一且增强的安全态势。
新功能和增强功能
大家好! 我最近才加入 InterSystems,但发现尽管我们推出了完全免费且出色的社区版,但大家并不是十分清楚如何获取。 因此我决定编写一份指南,详细介绍获取 InterSystems IRIS 社区版的所有不同方式:
对于刚刚接触 InterSystems IRIS 开发的伙伴,推荐使用社区版的容器化实例,在我看来,这是最简单直接的方式。 InterSystems IRIS 社区版可以在 DockerHub 上获取;如果您有 InterSystems SSO 帐户,还可以在 InterSystems 容器注册表中获取。
在这两种情况下,您都需要使用 docker CLI 拉取所需镜像:
docker pull intersystems/iris-community:latest-em
// or
docker pull containers.intersystems.com/intersystems/iris-community:latest-em接下来,您需要启动容器:要从容器外部与 IRIS 进行交互(例如使用管理门户),您需要发布一些端口。 以下命令将运行 IRIS 社区版容器,并发布超级服务器和 Web 服务器端口;请注意,此时不能运行其他依赖 1972 或 52773 端口的程序!
docker run --name iris -d --publish 1972:1972 --publish 52773:52773 intersystems/iris-community:latest-em您可能想要完全避免本地安装的一系列操作,如果是这种情况,您可以借助 InterSystems IRIS 社区版的云部署实现环境搭建和运行。 所有主流云提供商均受支持;有关详细信息,请参阅我们的云合作伙伴页面。 本例将重点介绍如何在 AWS 上部署。
先在 AWS Marketplace 中找到 InterSystems IRIS 社区版:
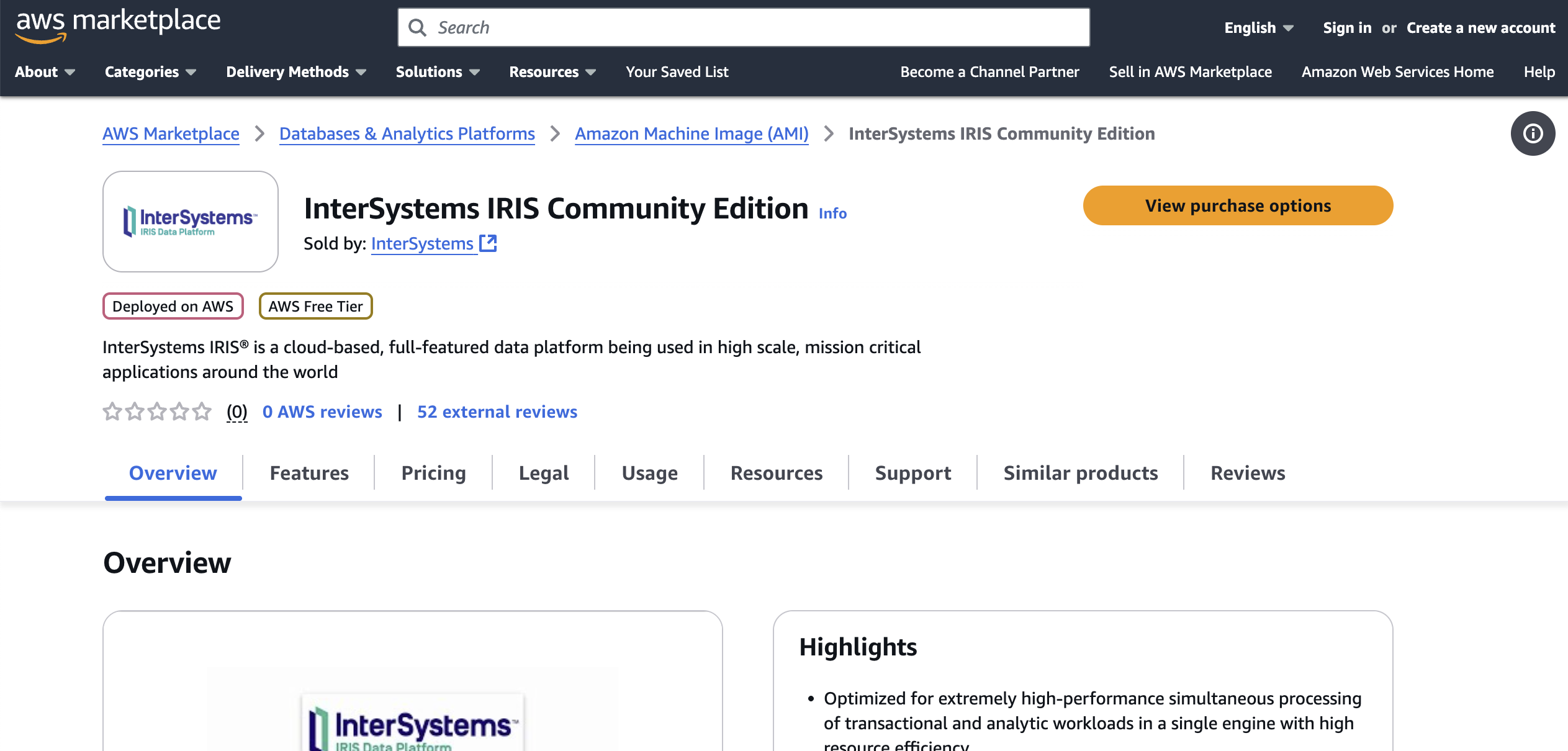
您可以点击“查看购买选项”,并登录您的帐户查看订阅页面:
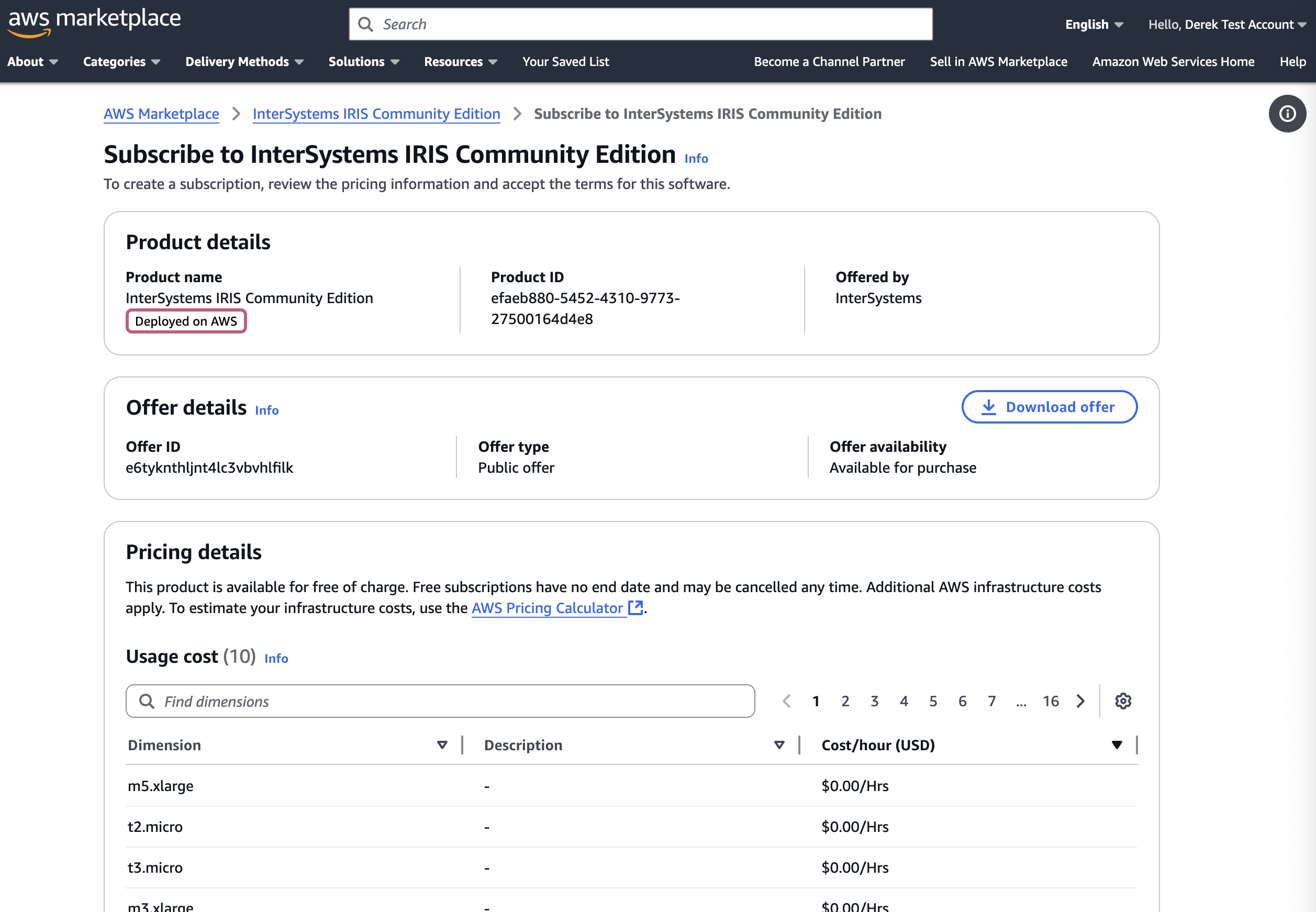
向下滚动,点击“订阅”,填写必填信息,然后点击“部署”,将 IRIS 社区版部署为云节点! 有关详细信息,请参阅我们关于将 InterSystems IRIS 部署到云端的文档。
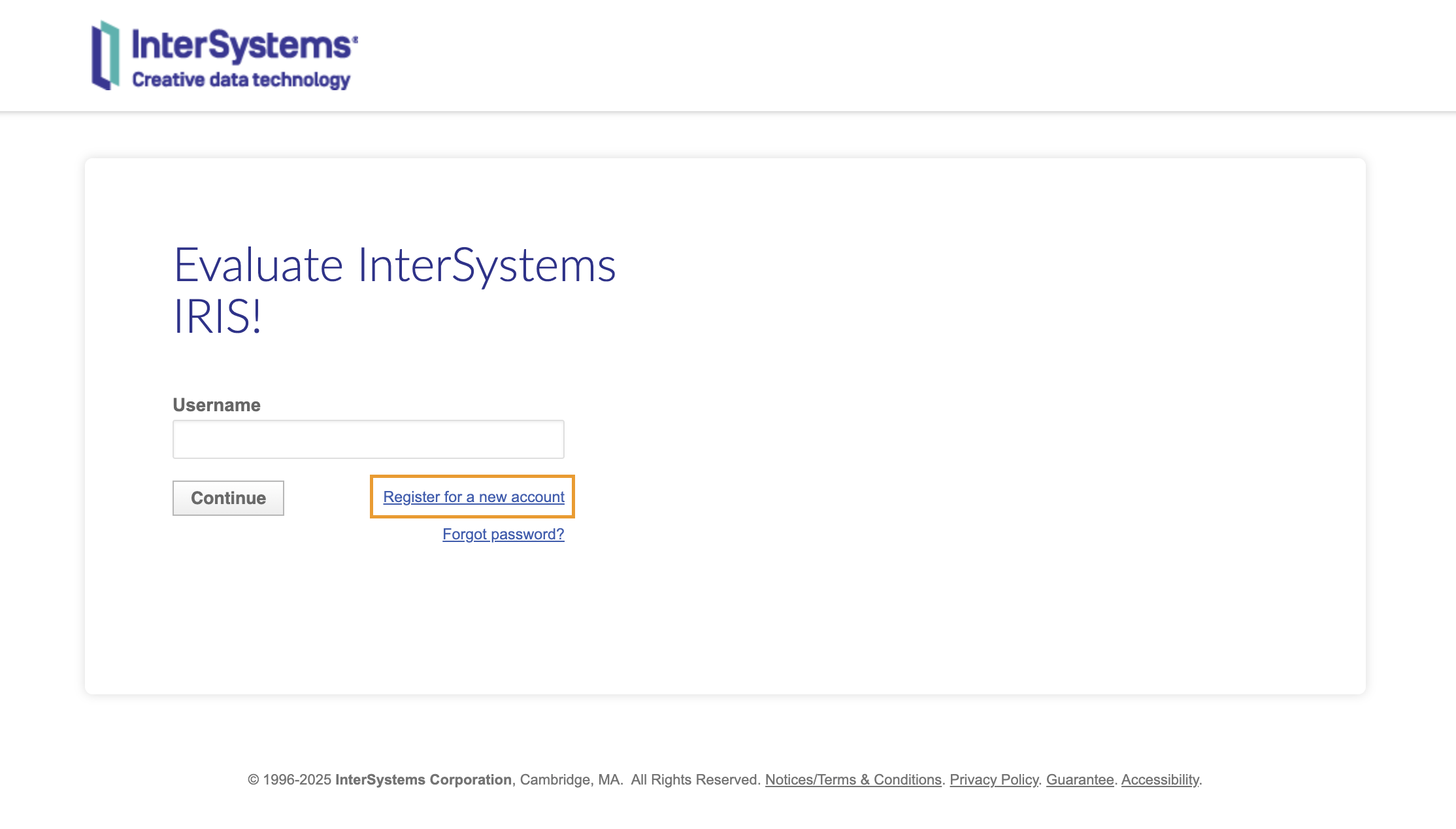
如果您倾向于将 InterSystems IRIS 直接安装到自己的机器上使用,且不想处理容器,可从 InterSystems 评估服务下载适合您系统的安装套件。要下载安装套件,您需要有 InterSystems SSO 登录帐户;但好消息是,如果您有开发者社区帐户,就说明您已有 InterSystems SSO 帐户! 如果您没有此帐户,可以点击“注册新帐户”并完成后续步骤:
 登录后,您应会看到以下页面;点击“下载社区版”开始下载安装套件:
登录后,您应会看到以下页面;点击“下载社区版”开始下载安装套件:
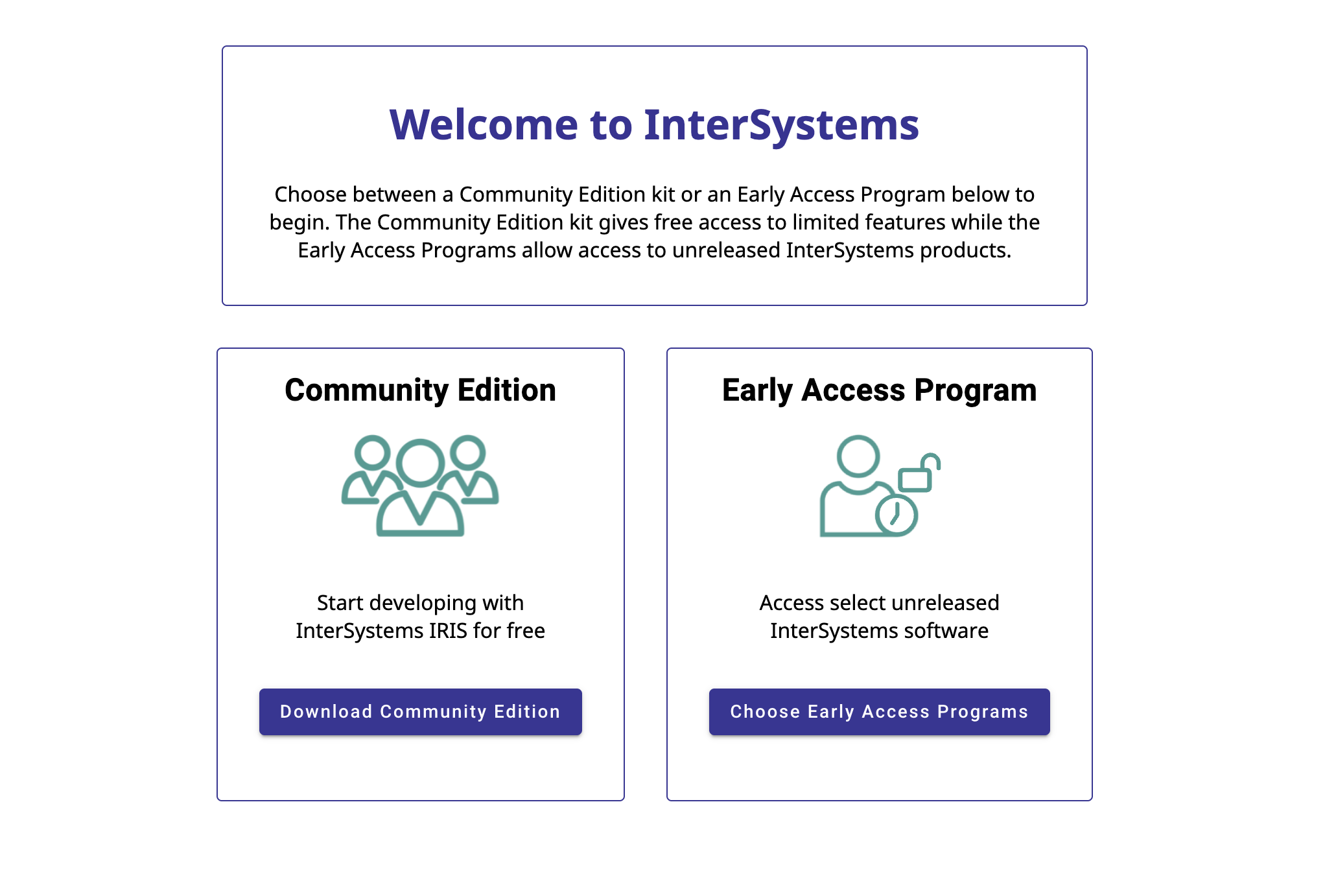
系统将提示您填写关于所需 InterSystems IRIS 的具体版本和安装平台的信息:
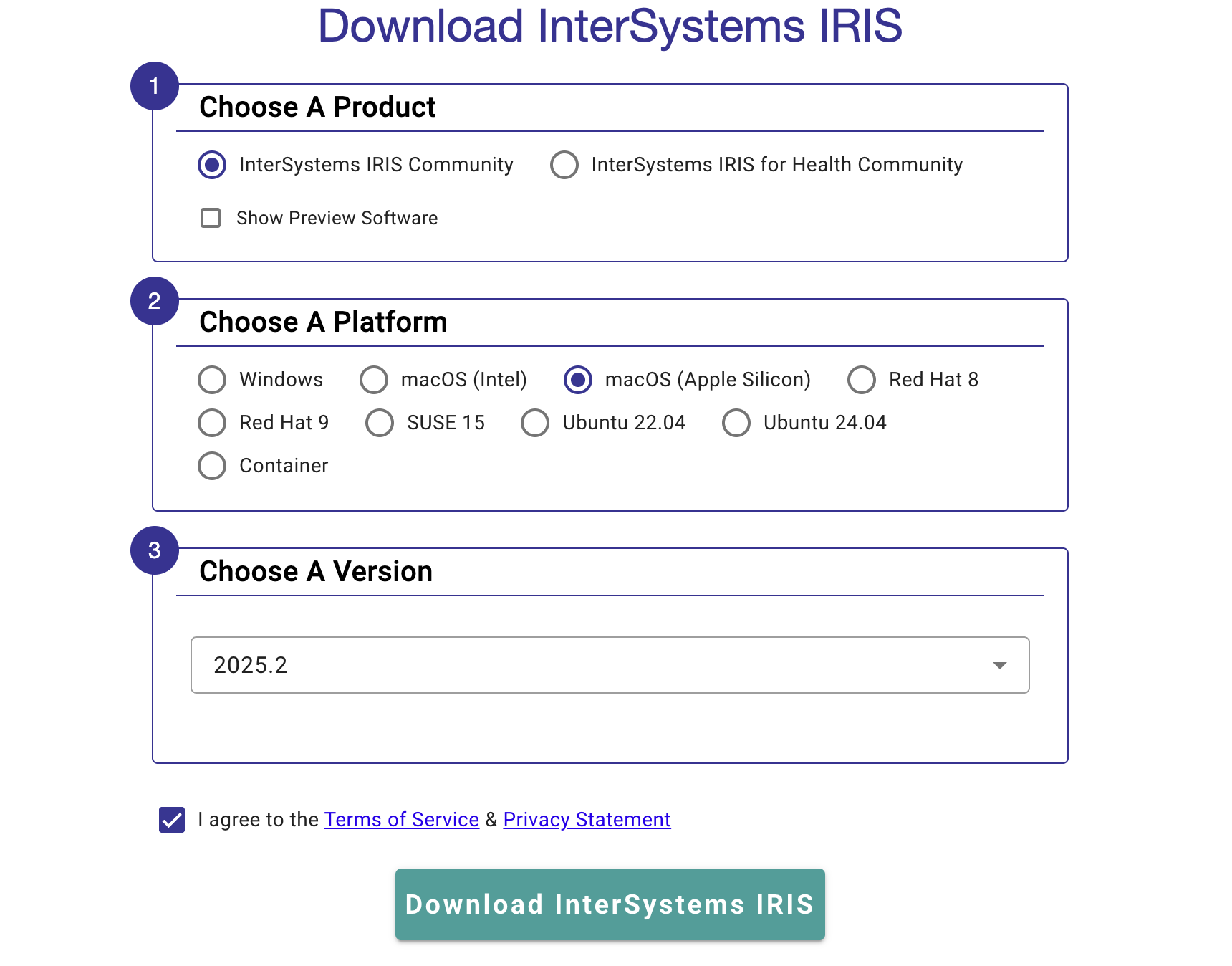
对于大部分用例,您需要选择“InterSystems IRIS 社区版”以及您的平台可用的最新版本。 同意《服务条款》后,您便可下载安装套件! 按照平台特定文档中的安装说明进行操作,一切就搞定啦!
在这一系列文章中,我想向大家介绍并探讨使用 InterSystems 技术和 GitLab 进行软件开发可以采用的几种方式。 我将介绍以下主题:
在本文中,我们将使用 InterSystems Cloud Manager 构建持续交付。 ICM 是一个面向基于 InterSystems IRIS 的应用程序的云配置和部署解决方案。 它允许您定义所需部署配置,ICM 会自动提供这些配置。 有关详情,请参阅 ICM 概述。
在我们的持续交付配置中,我们将完成以下任务:
也可以用示意图形式表示此流程:
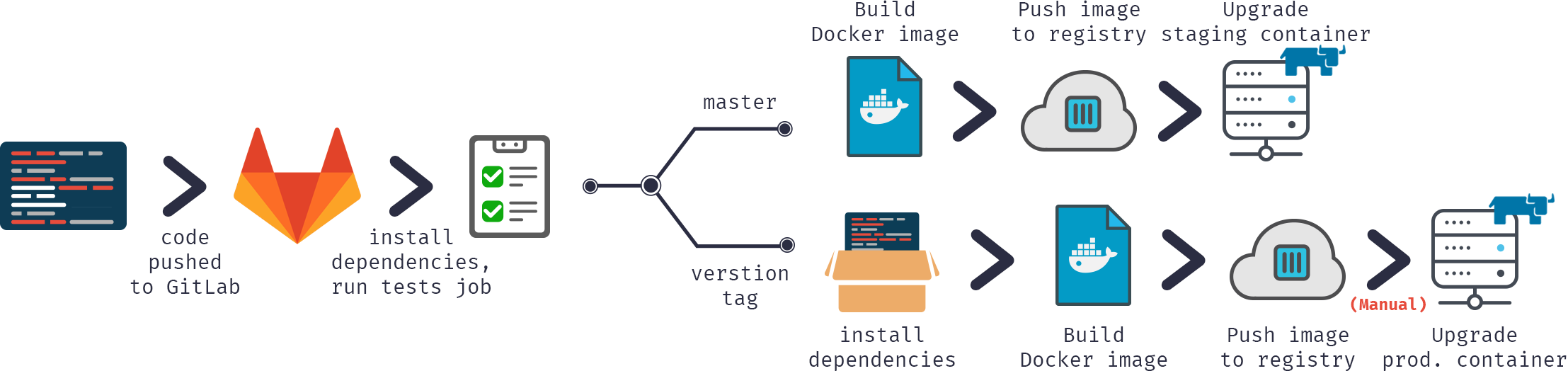
如您所见,基本操作是相同的,不过我们将使用 ICM 而不是手动方式来管理 Docker 容器。
在我们开始升级容器之前,需要对它们进行配置。 因此,我们需要定义 defaults.json 和 definitions.json 来描述我们的架构。 我将为 LIVE 服务器提供这 2 个文件,TEST 服务器的 definitions 是相同的,defaults 只在 Tag 和 SystemMode 值上有所不同。
{
"Provider": "GCP",
"Label": "gsdemo2",
"Tag": "LIVE","SystemMode": "LIVE",
"DataVolumeSize": "10",
"SSHUser": "sample",
"SSHPublicKey": "/icmdata/ssh/insecure.pub",
"SSHPrivateKey": "/icmdata/ssh/insecure",
"DockerImage": "eduard93/icmdemo:master",
"DockerUsername": "eduard93",
"DockerPassword": "...",
"TLSKeyDir": "/icmdata/tls",
"Credentials": "/icmdata/gcp.json",
"Project": "elebedyu-test",
"MachineType": "n1-standard-1",
"Region": "us-east1",
"Zone": "us-east1-b",
"Image": "rhel-cloud/rhel-7-v20170719",
"ISCPassword": "SYS",
"Mirror": "false"
}
[
{
"Role": "DM",
"Count": "1",
"ISCLicense": "/icmdata/iris.key"
}
]在 ICM 容器内部,/icmdata 文件夹从主机挂载,并且:
获取所有必需的密钥后:
keygenSSH.sh /icmdata/ssh keygenTLS.sh /icmdata/tls
并将必需的文件放置在 /icmdata 中:
调用 ICM 来配置您的实例:
cd /icmdata/test icm provision icm run cd /icmdata/live icm provision icm run
这将为每个 TEST 和 LIVE 服务器配置一个独立的 InterSystems IRIS 实例。
有关更详细的指南,请参阅 ICM 概述。
首先,我们需要构建镜像。
我们的代码通常存储在仓库中,CD 配置位于 gitlab-ci.yml 中,但为了提高安全性,我们会在构建服务器上存储几个服务器特定的文件。
许可证密钥。 或者,它可以在容器构建过程中下载,而不是存储在服务器上。 将密钥存储在仓库中非常不安全。
包含默认密码的文件。 将这类文件存储在仓库中也非常不安全。 此外,如果您在单独的服务器上托管生产环境,它可能有不同的默认密码。
初始脚本,它执行以下任务:
set dir = ##class(%File).NormalizeDirectory($system.Util.GetEnviron("CI_PROJECT_DIR"))
do ##class(%SYSTEM.OBJ).Load(dir _ "Installer/Global.cls","cdk")
do ##class(Installer.Global).init()
halt请注意,第一行有意留空。
与之前的示例相比,有几个不同之处。 首先,我们没有启用操作系统身份验证,因为 ICM 会与容器交互而不是直接与 GitLab 交互。 其次,我使用安装程序清单来初始化我们的应用程序,以展示不同的初始化方式。 有关安装程序的更多信息,请参阅这篇文章。 最后,我们将在 Docker Hub 中以私有仓库的形式发布我们的镜像。
我们的安装程序清单如下所示:
<Manifest>
<Log Text="Creating namespace ${Namespace}" Level="0"/>
<Namespace Name="${Namespace}" Create="yes" Code="${Namespace}" Ensemble="" Data="IRISTEMP">
<Configuration>
<Database Name="${Namespace}" Dir="${MGRDIR}/${Namespace}" Create="yes" MountRequired="true" Resource="%DB_${Namespace}" PublicPermissions="RW" MountAtStartup="true"/>
</Configuration>
<Import File="${Dir}MyApp" Recurse="1" Flags="cdk" IgnoreErrors="1" />
</Namespace>
<Log Text="Mapping to USER" Level="0"/>
<Namespace Name="USER" Create="no" Code="USER" Data="USER" Ensemble="0">
<Configuration>
<Log Text="Mapping MyApp package to USER namespace" Level="0"/>
<ClassMapping From="${Namespace}" Package="MyApp"/>
</Configuration>
<CSPApplication Url="/" Directory="${Dir}client" AuthenticationMethods="64" IsNamespaceDefault="false" Grant="%ALL" />
<CSPApplication Url="/myApp" Directory="${Dir}" AuthenticationMethods="64" IsNamespaceDefault="false" Grant="%ALL" />
</Namespace>
</Manifest>它实现了以下更改:
现在,继续持续交付配置:
build image:
stage: build
tags:
- master
script:
- cp -r /InterSystems/mount ci
- cd ci
- echo 'SuperUser' | cat - pwd.txt load_ci_icm.script > temp.txt
- mv temp.txt load_ci.script
- cd ..
- docker build --build-arg CI_PROJECT_DIR=$CI_PROJECT_DIR -t eduard93/icmdemo:$CI_COMMIT_REF_NAME .这里会执行哪些操作?
首先,由于 docker build 只能访问基础构建目录(在我们的示例中为仓库根目录)的子目录,我们需要将我们的“秘密”目录(其中包含 iris.key、pwd.txt 和 load_ci_icm.script)复制到克隆的仓库中。
接下来,首次终端访问需要用户名/密码,因此我们会将这些信息添加到 load_ci.script 中(这也是 load_ci.script 开头一行留空的原因)。
最后,我们会构建 docker 镜像并适当地为其添加标签:eduard93/icmdemo:$CI_COMMIT_REF_NAME
其中,$CI_COMMIT_REF_NAME 是当前分支的名称。 请注意,镜像标签的第一部分应与 GitLab 中的项目名称相同,这样才能在 GitLab 的“注册表”标签页中看到它(“注册表”标签页中提供了关于添加标签的说明)。
构建 docker 镜像是通过 Dockerfile 完成的,具体如下:
FROM intersystems/iris:2018.1.1-released ENV SRC_DIR=/tmp/src ENV CI_DIR=$SRC_DIR/ci ENV CI_PROJECT_DIR=$SRC_DIR COPY ./ $SRC_DIR RUN cp $CI_DIR/iris.key $ISC_PACKAGE_INSTALLDIR/mgr/ \ && cp $CI_DIR/GitLab.xml $ISC_PACKAGE_INSTALLDIR/mgr/ \ && $ISC_PACKAGE_INSTALLDIR/dev/Cloud/ICM/changePassword.sh $CI_DIR/pwd.txt \ && iris start $ISC_PACKAGE_INSTANCENAME \ && irissession $ISC_PACKAGE_INSTANCENAME -U%SYS < $CI_DIR/load_ci.script \ && iris stop $ISC_PACKAGE_INSTANCENAME quietly
我们从基本的 iris 容器开始。
首先,我们将仓库(和“秘密”目录)复制到容器中。
接下来,我们将许可证密钥复制到 mgr 目录中。
然后,我们将密码更改为 pwd.txt 中的值。 请注意,此操作会删除 pwd.txt。
之后,实例启动并执行 load_ci.script。
最后,iris 实例停止。
请注意,我使用的是 GitLab Shell 执行器,而不是 Docker 执行器。 当您需要从镜像内部提取某些内容时,将使用 Docker 执行器,例如在 Java 容器中构建 Android 应用程序并且只需要一个 apk 时。 在我们的示例中,我们需要整个容器,因此需要使用 Shell 执行器。 因此,我们通过 GitLab Shell 执行器运行 Docker 命令。
现在,我们将镜像发布到 Docker Hub
publish image:
stage: publish
tags:
- master
script:
- docker login -u eduard93 -p ${DOCKERPASSWORD}
- docker push eduard93/icmdemo:$CI_COMMIT_REF_NAME注意 ${DOCKERPASSWORD} 变量,它是 GitLab 的秘密变量。 我们可以在“GitLab > 项目 > 设置 > CI/CD > 变量”中添加它们:

作业日志中也不包含密码值:
Running with gitlab-runner 10.6.0 (a3543a27)
on icm 82634fd1
Using Shell executor...
Running on docker...
Fetching changes...
Removing ci/
HEAD is now at 8e24591 Add deploy to LIVE
Checking out 8e245910 as master...Skipping Git submodules setup$ docker login -u eduard93 -p ${DOCKERPASSWORD}
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Login Succeeded
$ docker push eduard93/icmdemo:$CI_COMMIT_REF_NAME
The push refers to repository [docker.io/eduard93/icmdemo]
master: digest: sha256:d1612811c11154e77c84f0c08a564a3edeb7ddbbd9b7acb80754fda97f95d101 size: 2620
Job succeeded
在 Docker Hub 中,我们可以看到新镜像:

我们有了镜像,接下来在我们的测试服务器上运行它。 脚本如下。
run image:
stage: run
environment:
name: $CI_COMMIT_REF_NAME
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/test && icm upgrade -image eduard93/icmdemo:$CI_COMMIT_REF_NAME"使用 ICM,我们只需要运行一个命令 (icm upgrade) 即可升级现有部署。 我们通过运行“docker exec icm sh -c”来调用它,这会在 icm 容器内执行指定的命令。首先,我们进入 /icmdata/test,这里定义了我们为 TEST 服务器准备的 ICM 部署定义。 之后,我们调用 icm upgrade 将当前存在的容器替换为新容器。
我们来运行一些测试。
test image:
stage: test
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/test && icm session -namespace USER -command 'do \$classmethod(\"%UnitTest.Manager\",\"RunTest\",\"MyApp/Tests\",\"/nodelete\")' | tee /dev/stderr | grep 'All PASSED' && exit 0 || exit 1"
同样,我们在 icm 容器内执行一条命令。 icm 会话在一个已部署的节点上执行命令。 该命令运行单元测试。 之后,它将所有输出传输到屏幕,同时也传输给 grep 以查找单元测试结果,并成功退出进程或以出错方式退出。
生产服务器上的部署与测试服务器上的部署完全相同,只是为 LIVE 部署定义使用了另一个目录。 如果测试失败,此阶段将不会被执行。
deploy image:
stage: deploy
environment:
name: $CI_COMMIT_REF_NAME
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/live && icm upgrade -image eduard93/icmdemo:$CI_COMMIT_REF_NAME"近日,InterSystems宣布 InterSystems IRIS® Cloud SQL 和 InterSystems IRIS® Cloud IntegratedML® 服务全面上市。 这些全面托管的云原生智能数据服务使开发人员能够轻松地在SQL环境中构建云原生数据库和机器学习(ML)应用程序。
通过 Cloud SQL和 Cloud IntegratedML,开发人员可以访问下一代关系数据库即服务(DBaaS),DBaaS快速且易于配置和使用。 嵌入式AutoML功能支持开发人员在全面托管的、弹性的云原生环境中,仅仅通过几条类似SQL的命令即可轻松开发并执行机器学习模型。
++ 更新:2018 年 8 月 1 日
使用内置于 Caché 数据库镜像的 InterSystems 虚拟 IP (VIP) 地址有一定的局限性。特别是,它只能在镜像成员驻留在同一网络子网时使用。当使用多个数据中心时,由于增加了网络复杂性( 此处有更详细的讨论),网络子网通常不会“延伸”到物理数据中心之外。出于类似的原因,当数据库托管在云端时,虚拟 IP 通常无法使用。
负载均衡器(物理或虚拟)等网络流量管理设备可用于实现相同级别的透明度,为客户端应用程序或设备提供单一地址。网络流量管理器自动将客户端重定向到当前镜像主服务器的真实 IP 地址。自动化旨在满足灾难后 HA 故障转移和 DR 升级的需求。
Caché 镜像是一种可靠、廉价且易于实施的高可用性和灾难恢复解决方案,适用于基于 Caché 和 Ensemble 的应用程序。镜像在广泛的计划内和计划外中断情况下提供自动故障转移,应用程序恢复时间通常限制在几秒钟内。逻辑数据复制消除了存储作为单点故障和数据损坏的根源。升级可以在很少或没有停机时间的情况下执行。
但是,部署 Caché 镜像确实需要大量规划,并且涉及许多不同的过程。与任何其他关键基础设施组件一样,操作镜像需要持续监控和维护。
您可以通过两种方式使用本文:作为常见问题列表,或作为理解和评估镜像、规划镜像、配置镜像和操作镜像的简要顺序指南。每个答案都包含指向每个主题的详细讨论以及每个任务的分步过程的链接。
当您准备好开始规划镜像部署时,您的起点应该始终是Caché 高可用性指南“镜像”一章的镜像架构和规划部分。
国务院于2022年12月19日发布了《中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见》(后简称《数据二十条》),如何有效利用数据已经成为下一步的趋势。另一方面,无论是基于数据中台还是数据编织理念,两者也都对如何利用数据提出了构想。因此医疗行业数字化建设的目标已不能再局限于如何收集数据,建立医疗行业数据的流通机制将会是为越来越普遍的需求。
时钟拨回几年前,数据中台概念开始火爆。人们对数据中台的定义、诠释尽管有诸多差异,通过数据中台降低数据共享和利用的成本则是共同的期望。但经过这几年的探索之后,中台已死的观点也在涌现。究其原因,除去中台概念在技术上的不确定,数据流通过程中的责权益的不清晰也是严重的制约因素。毕竟,数据中台自身作为一套技术框架并不能代替法律法规与市场自动将数据转变为商品从而创造出流通价值。
那么,如何能够使数据的流通合规合法,使数据能够如货币和商品一般自由流动,则是我们需要思考和探索的主题,这次《数据二十条》的出现,无疑为医疗信息技术工作者提供了一个明确的思考方向。
在这篇文章中,你可以访问InterSystems开发者社区中与学习InterSystems IRIS最相关主题的文章库。找到按机器学习、嵌入式Python、JSON、API和REST应用、管理和配置InterSystems环境、Docker和云、VSCode、SQL、分析/BI、全局、安全、DevOps、互操作性、Native API排列的顶级发表的文章。快来享受学习的乐趣吧!
机器学习是建立先进的数据分析和自动化人工活动的一种必要的技术,具有很好的效率。它可以创建认知模型,从现有的数据中学习,并根据其自我调整的算法进行预测、概率计算、分类、识别和 "非创造性 "的人类活动的自动化。
在所有情况下,InterSystems IRIS作为一个数据平台和环境来创建、执行、提供和使用这些机器学习模型。IRIS能够从SQL命令(IntegratedML)中使用ML,使用嵌入式Python和PMML(预测模型标记语言)来执行ML。你可以在以下文章中查看它的功能:
所有源代码均在: https://github.com/antonum/ha-iris-k8s
在上一篇文章中,我们讨论了如何在k8s集群上建立具有高可用性的IRIS,基于分布式存储,而不是传统的镜像。作为一个例子,那篇文章使用了Azure AKS集群。在这一篇中,我们将继续探讨k8s上的高可用配置。这一次,基于Amazon EKS(AWS管理的Kubernetes服务),并将包括一个基于Kubernetes 快照进行数据库备份和恢复的选项。
开始干活. 首先需要一个AWS账户,安装 AWS CLI,kubectl 和 eksctl 工具. 要创建新的集群,请运行以下命令:
eksctl create cluster \ --name my-cluster \ --node-type m5.2xlarge \ --nodes 3 \ --node-volume-size 500 \ --region us-east-1
这个命令需要大约15分钟,部署EKS集群并使其成为你的kubectl工具的默认集群。你可以通过运行以下代码来验证你的部署:
大家好! 对于那些参加了2021年虚拟峰会的体验实验室的人来说,你可能还记得其中一个实验室会议是围绕Kubernetes进行的。我们现在已经将该实验室转换为完全线上按需使用。你可以启动一个小型的虚拟机集群,并按照练习来管理你的Kubernetes集群,将InterSystems IRIS容器部署到其中,并观察它在摧毁一个吊舱时的自我修复性质。
如果你有兴趣,这是一个很好的Kubernetes介绍。请看这里: 用InterSystems IRIS 和 Kubernetes实现高可用
我们将从我们在 InterSystems 数据科学实践中遇到的示例开始讲起:
综合考虑包括上述在内的示例后,我们总结了以下因过渡到使用实时机器学习和人工智能而出现的挑战:
本文综合概述了 InterSystems IRIS 平台在全面支持人工智能/机器学习机制部署、人工智能/机器学习解决方案装配(集成)和基于密集数据流的人工智能/机器学习解决方案训练(测试)方面的功能。 我们将关注市场研究、人工智能/机器学习解决方案实例以及我们在本文中称为实时人工智能/机器学习平台的概念方面的内容。
由 Lightbend 在 2019 年面向约 800 名专业 IT 人士进行的调查,结果不言自明:
图 1:实时数据的主要使用者
我们将引用该调查结果报告中对我们最重要的片段:“… 流式传输数据流水线和基于容器的基础架构有着并驾齐驱的增长趋势,二者相结合可应对在更快、更高效且更敏捷地交付有影响力的结果方面存在的竞争压力。 与传统的批处理相比,流式传输能够更快地从数据中提取有用信息。 它还可以及时地集成高级分析数据,例如基于人工智能和机器学习 (AI/ML) 模型的推荐,所有功能都旨在通过提高客户满意度来实现差异化竞争优势。 时间压力也会对 DevOps 团队构建和部署应用造成影响。 诸如 Kubernetes 等基于容器的基础架构可帮助常要通过快速、重复构建和部署应用以应对变化的团队化解其面对的许多效率低下和设计问题。 … 804 位 IT 专业人士提供了有关其组织内使用流式处理的应用的详细信息。 受访者主要来自西方国家/地区(欧洲占比 41%,北美占比 37%),任职于大中小型组织的人数占比大致相等。 … … 人工智能并非投机炒作。 在已于人工智能/机器学习生产应用中使用流式处理的受访者中,有 58% 的人表示明年将出现一些最大幅增长。
这项非常有趣的调查表明,机器学习和人工智能场景是实时数据的主要使用者,这种看法已得到广泛认可。 另一个重要的收获是透过 DevOps 视角折射出的对于人工智能/机器学习的看法:我们现在已经可以断言,仍占主导地位的“基于完全已知数据集的一次性人工智能/机器学习”文化已发生转变。
实时人工智能/机器学习最典型的使用领域之一是工业中的制造过程管理。 让我们以这一领域为例并考虑上述所有想法,为实时人工智能/机器学习平台的概念给出确切的定义。 使用人工智能和机器学习来满足制造过程管理的需求具备多项与众不同的特性:
这些特性使我们除了需要实时接收和基本处理来自制造过程的密集“宽带信号”之外,也需要以实时方式执行(并行)人工智能/机器学习模型应用、训练和准确率控制。 我们的模型在移动观察窗口中“看到”的“框架”在不断变化 – 基于之前某一“框架”训练的人工智能/机器学习模型在准确率方面也会发生变化。 如果人工智能/机器学习建模准确率下降(例如,“警报范数”分类误差的值超过了给定的容差边界),则应自动触发基于较新“框架”的重新训练 – 同时,在选择开始重新训练的时刻时,必须考虑到重新训练过程持续时间和当前模型版本的准确率下降速度(因为在获得“重新训练”版本的模型之前,在执行重新训练的过程期间会一直持续应用当前版本)。 InterSystems IRIS 拥有关键的平台内功能,可充分支持用于制造过程管理的实时人工智能/机器学习解决方案。 这些功能可以分为三大类:
将与机器学习和人工智能相关的平台功能归入上述类别并非随意而为。 我们引用了由 Google 发表的方法论文章,文中为这种分组提供了概念基础:“… DevOps 是开发和运行大规模软件系统的一种常见做法。 这种做法具有诸多优势,例如缩短开发周期、提高部署速度、实现可靠的发布。 如需获得这些优势,您需要在软件系统开发中引入两个概念:
机器学习系统是一种软件系统,因此类似的做法有助于确保您能够可靠地大规模构建和运行机器学习系统。 但是,机器学习系统在以下方面与其他软件系统不同:
机器学习和其他软件系统在源代码控制的持续集成、单元测试、集成测试以及软件模块或软件包的持续交付方面类似。 但是,在机器学习中,有一些显著的差异:
我们可以得出结论,基于实时数据的机器学习和人工智能需要更为广泛的工具和更加丰富的功能(从代码开发到数学建模环境编排)、所有功能和主题领域之间更加紧密的集成、更好的人力及机器资源管理。
继续以制造过程管理领域为例,我们将探讨一个已在开头引用过的实际案例:需要建立一种基于制造过程参数值流以及维护人员缺陷检测报告来实时识别进料泵中出现的缺陷的机制。
图 2:识别出现缺陷的案例解析
许多类似的实际案例中都有一个共同的特点,即在考虑规律且及时地馈送数据 (SCADA) 时,还需要同时考虑偶发且不规则地检测(和记录)各种缺陷类型。 换句话说:SCADA 数据每秒馈送一次以供分析,但需要用纸笔记录缺陷并注明日期(例如:“1 月 12 日– 第三轴承区域漏油渗入泵盖”)。 因此,我们可以通过添加以下重要限制来对案例解析加以补充:我们只有一种具体缺陷类型的“指纹”(即具体缺陷类型由截至具体日期的 SCADA 数据表示 – 该特定缺陷类型没有其他示例)。 这一限制立即使我们脱离了假定有大量可用“指纹”的传统机器学习范式(监督学习)。
图 3:细化缺陷识别案例解析
我们能否以某种方式“倍增”我们可用的“指纹”? 是的,可以。 泵的当前状况由其与已记录缺陷的相似度表征。 即使不运用定量方法,仅通过观察从 SCADA 系统接收到的参数值的动态,也可以了解很多信息:
图 4:泵状况动态与具体缺陷类型“指纹”
然而,视觉感知(至少目前)在我们动态发展的场景中并不是最合适的机器学习“标签”生成器。 我们将使用统计检验来评估当前泵状况与已记录缺陷的相似度。
图 5:对传入数据与缺陷“指纹”应用统计检验
统计检验可评估一组包含制造过程参数值的记录(以“批次”形式取自 SCADA 系统)与具体缺陷“指纹”的记录相似的概率。 使用统计检验(统计相似度指数)评估的概率随后会被转换为 0 或 1,成为我们评估相似度的每组记录中的机器学习“标签”。 即,使用统计检验处理获取到的一批泵状况记录后,我们就能够 (a) 将该批次添加到人工智能/机器学习模型的训练数据集以及 (b) 评估人工智能/机器学习模型当前版本应用于该批次时的准确率。
图 6:对传入数据与缺陷“指纹”应用机器学习模型
在之前的一期在线讲座中,我们展示并讲解了 InterSystems IRIS 平台如何将任何人工智能/机器学习机制实现为能够控制建模输出似然并调整模型参数的持续执行的业务流程。 我们实现泵场景依赖于在线讲座中介绍的完整 InterSystems IRIS 功能 – 这些功能在作为我们的解决方案一部分的 ANALYZER 流程中使用,通过自动管理训练数据集实现强化学习,取代了传统的监督学习。 我们会将在应用统计检验(相似度指数转换为 0 或 1)和当前版本的模型之后呈现“检测一致性”(即统计检验和模型基于这些记录均输出 1)的记录添加到训练数据集中。 重新训练模型时,在其验证阶段(将新训练的模型应用于自身的训练数据集,在此之前需要对该数据集提前进行统计检验),应用统计检验后“未能保持”输出 1 的记录(由于训练数据集中永远存在属于原始缺陷“指纹”的记录)将从训练数据集中移除,并基于缺陷“指纹”和数据流中的“成功”记录训练新版本模型。
图 7:InterSystems IRIS 中人工智能/机器学习计算的机器人化
如果需要对通过 InterSystems IRIS 中的本地计算获得的检测准确率寻求“第二意见”,我们可以创建一个顾问流程,以使用云提供商(例如 Microsoft Azure、Amazon Web Services、 Google Cloud Platform 等)基于控制数据集重做模型训练/应用):
图 8:来自 Microsoft Azure 的“第二意见”,由 InterSystems IRIS 编排
我们场景的原型在 InterSystems IRIS 中实现为分析过程的代理系统,与设备(泵)、数学建模环境(Python、R 和 Julia)交互,并支持所有相关人工智能/机器学习机制的自我训练 – 基于实时数据流。
图 9:InterSystems IRIS 中实时人工智能/机器学习解决方案的核心功能
基于我们的原型获得的一些实际结果:

 对包含多次发生相同缺陷的真实数据进行的模拟表明,我们使用 InterSystems IRIS 平台实现的解决方案可以在维修队发现问题的几日之前检测到缺陷。
对包含多次发生相同缺陷的真实数据进行的模拟表明,我们使用 InterSystems IRIS 平台实现的解决方案可以在维修队发现问题的几日之前检测到缺陷。
InterSystems IRIS 是一款完整、统一的平台,可简化实时富数据解决方案的开发、部署和维护。 它提供了并发事务和分析处理能力,支持多个完全同步的数据模型(关系、分层、对象和文档),一个可集成不同数据孤岛和应用的完整的互操作性平台,以及支持批处理和实时用例的复杂结构化和非结构化分析功能。 该平台还提供了一个开放的分析环境,可将同类最佳的分析整合到 InterSystems IRIS 解决方案中,并提供灵活的部署功能以支持云和本地部署的任意组合。 由 InterSystems IRIS 平台提供支持的应用目前已在各行各业中得到广泛使用,帮助公司在战略和战术执行中获得切实的经济利益,促进明智的决策制定并消除事件、分析和行动之间的“差距”。
图 10:实时人工智能/机器学习背景下的 InterSystems IRIS 架构
与上图相同,下图将新的“基础”(CD/CI/CT) 与平台工作元素之间的信息流结合起来。 可视化始于 CD 宏机制,并继续贯穿于 CI/CT 宏机制。
图 11:InterSystems IRIS 平台人工智能/机器学习工作元素之间的信息流图
InterSystems IRIS 中 CD 机制的基本要素:平台用户(人工智能/机器学习解决方案开发者)使用专门的人工智能/机器学习代码编辑器调整现有和/或创建新的人工智能/机器学习机制。上述代码编辑器为 Jupyter(全称:Jupyter Notebook;为简洁起见,在此编辑器中创建的文档也常被称为相同的名称)。 在 Jupyter 中,开发者可以在传输(“部署”)到 InterSystems IRIS 之前编写、调试和测试(也使用可视化表示)具体的人工智能/机器学习机制。 显然,以这种方式开发的新机制只能进行基本的调试(特别是因为 Jupyter 不处理实时数据流)– 但我们对此没有意见,因为原则上,在 Jupyter 中开发代码的主要目标是验证单独的人工智能/机器学习机制的功能。 类似地,已部署在平台中的人工智能/机器学习机制(请参阅其他宏机制)在调试前可能需要“回滚”到其“平台前”版本(从文件读取数据、通过 xDBC 而非本地表或 global(即 InterSystems IRIS 中的多维数据数组)访问数据等)。 在 InterSystems IRIS 中实现 CD 具有一项重要特性:平台和 Jupyter 之间存在双向集成关系,支持在平台内部署(利用进一步的平台内处理)Python、R 和 Julia 内容(三种语言均为各自主要开源数学建模环境的编程语言)。 也就是说,人工智能/机器学习内容开发者获得了在平台中“持续部署”其内容的能力,同时能够使用其常用 Jupyter 编辑器以及 Python、R、Julia 所提供的常用函数库,在平台外部提供基本的调试功能(必要情况下)。 继续聊聊 InterSystems IRIS 中的 CI 宏机制。 该图展示了“实时机器人化”的宏流程(一组数据结构、以数学环境语言编写的业务流程和代码段,以及以其编排的 InterSystems IRIS 原生开发语言 ObjectScript)。 宏流程的目标是:支持人工智能/机器学习机制运行所需的数据处理队列(基于实时传输到平台的数据流),对人工智能/机器学习机制的排序和“分类” (又名 “数学算法”、“模型”等 – 可根据实现细节和术语偏好采用多种不同名称)做出决策,对围绕人工智能/机器学习输出(多维数据集、表格、多维数据数组等 – 生成报告、仪表板等)的智能保持最新的分析结构。 在 InterSystems IRIS 中实现 CI 具有一项重要特性:平台和数学建模环境之间存在双向集成关系,支持在平台内执行使用 Python、R 或 Julia 在各自的环境中编写的内容并接收执行结果。 这种集成在“终端模式”(即人工智能/机器学习内容被制定为对数学环境执行标注的 ObjectScript 代码)和“业务流程模式”(即人工智能/机器学习内容被制定为使用可视化编辑器、Jupyter 或 IDE(IRIS Studio、Eclipse、Visual Studio Code)的业务流程)下均适用。 需要使用 CI 层内的 IRIS 和 CD 层内的 Jupyter 之间的链接指定在 Jupyter 中编辑业务流程的可用性。 本文将进一步提供与数学建模环境相集成的更为详细的概述。 我们认为此时完全有理由向您说明,平台中提供了将人工智能/机器学习机制(源自“持续部署”)“持续集成”到实时人工智能/机器学习解决方案中所需的所有工具。 最后要聊到的是至关重要的宏机制:CT。 没有它,就不会存在人工智能/机器学习平台(即便可以通过 CD/CI 实现“实时”)。 CT 的本质是平台能够在数学建模环境的会话中直接操作机器学习和人工智能的“工件”:模型、分布表、向量/矩阵、神经网络层等。 在大多数情况下,这种“互操作性”体现于在环境中创建上述工件(例如,对于模型,“创建”包括模型规范及其参数的后续评估,即所谓的模型“训练”),对工件进行应用(对于模型:借助目标变量的“建模”值进行计算 – 预测、类别指定、事件概率等),以及对已经创建的和应用的工件进行改进 (例如,通过根据模型的性能重新定义模型的输入变量以便提高预测准确率,作为一种可行选项)。 CT 角色的关键属性是它对 CD 和 CI 现实的“抽象”:CT 可以在具体环境中存在的限制下使用人工智能/机器学习解决方案的计算和数学细节来实现所有工件。 将由 CD 和 CI 负责“提供输入数据”和“交付输出”。 在 InterSystems IRIS 中实现 CT 具有一项重要特性:使用上述与数学建模环境的集成时,平台可以从其编排的数学环境内的会话中提取工件,并且(最重要的是)将它们转换为平台内数据对象。 例如,刚刚在 Python 会话中创建的分布表可以(无需暂停 Python 会话)传输到平台中作为 global(InterSystems IRIS 中的多维数据数组),并进一步重用于在不同的人工智能/机器学习机制下的计算(使用不同环境的语言实现,如 R),或者作为虚拟表。 另一个示例:与模型的“例程”功能并行(在 Python 会话中),它的输入数据集使用“自动机器学习”进行处理 – 自动搜索优化的输入变量和模型参数。 与“例程”训练一起,生产模型可以实时接收“优化建议”,以根据调整后的输入变量集、调整后的模型参数值(不再是 Python 训练的结果,而是作为其“替代”版本的训练结果,例如使用 H2O 框架),使整个人工智能/机器学习解决方案能够以自主方式处理输入数据和建模对象/流程中不可预见的漂移。 我们现在将以现有原型为例,深入了解 InterSystems IRIS 的平台内人工智能/机器学习功能。 在下图中,在图像的左侧部分,我们看到了实现 Python 和 R 脚本执行的业务流程的片段。 在中央部分,我们看到了执行这些脚本后的 Python 和 R 的相应可视化日志。 接下来是两种语言的内容示例,在各自环境中执行。 右侧为基于脚本输出的可视化。 右上角的可视化使用 IRIS Analytics 开发(数据从 Python 传输到 InterSystems IRIS 平台,并使用平台功能呈现在仪表板中),右下角所示为直接在 R 会话中获取并从中传输到图形文件的内容。 重要说明:所讨论的业务流程片段在此原型中负责基于从设备模拟器流程实时接收的数据进行模型训练(设备状况分类),该流程由监控分类模型性能的分类准确率监控流程触发。 文中会进一步讨论将人工智能/机器学习解决方案实现为一组交互式业务流程(“代理”)。
图 12:在 InterSystems IRIS 中与 Python、R 和 Julia 的交互
平台内流程(又称 “业务流程”、“分析过程”、“流水线”等,具体取决于上下文)可以编辑,首先是使用平台中的可视化业务流程编辑器,所用方式可同时创建流程图及其相应的人工智能/机器学习机制(代码)。 我们所说的“创建人工智能/机器学习机制”是指从一开始就进行混合(在流程级别):使用数学建模环境的语言编写的内容与使用 SQL (包括 IntegratedML 扩展程序)、InterSystems ObjectScript 以及其他支持的语言编写的内容相邻。 此外,平台内范式以嵌入片段集的形式(如下图所示)为“绘制”流程提供了广泛的功能,有助于高效地构建有时相当复杂的内容,避免视觉组合中的“随机失活” (“非可视化”方法/类/过程等)。 即,在必要情况下(可能在大多数项目中),可以采用可视化的自文档格式实现整个人工智能/机器学习解决方案。 请您注意下图中心部分,该部分展示了“更高级的嵌入向量层”,并表明除了这样的模型训练(使用 Python 和 R 实现)之外,还有针对训练模型的所谓 ROC 曲线分析,可对其训练质量进行视觉(和计算)评估 – 该分析使用 Julia 语言实现(在其各自的 Julia 环境中执行)。
图 13:InterSystems IRIS 中的视觉人工智能/机器学习解决方案组合环境
如前所述,已实现的平台内人工智能/机器学习机制的初始开发和(在其他情况中)调整将在平台外部的 Jupyter 编辑器中执行。 在下图中,我们可以找到一个编辑现有平台内流程的示例(与上图中的流程相同)– 这就是其模型训练片段在 Jupyter 中的外观。 Python 语言的内容支持在 Jupyter 中编辑、调试、查看内嵌计算图。 更改(如果需要)可以立即复制到平台内流程,包括其生产版本。 同样,新开发的内容也可以复制到平台(自动创建一个新的平台内流程)。
图 14 在 InterSystems IRIS 中使用 Jupyter Notebook 编辑平台内人工智能/机器学习机制
平台内流程的编辑不仅可以使用可视化或笔记本格式执行,还可以使用“完整”的 IDE(集成开发环境)格式执行。 IDE 为 IRIS Studio(原生 IRIS 开发工作室)、Visual Studio Code(VSCode 的 InterSystems IRIS 扩展程序)和 Eclipse(Atelier 插件)。 在某些情况下,开发团队可以同时使用全部三种 IDE。 下图展示了在 IRIS Studio、Visual Studio Code 和 Eclipse 中编辑完全相同流程的示例。 内容的任何部分都完全可以编辑:Python/R/Julia/SQL、ObjectScript 和业务流程元素。
图 15:在各种 IDE 中编辑 InterSystems IRIS 业务流程
在 InterSystems IRIS 中使用业务流程语言 (BPL) 组合和执行业务流程的方法值得特别提及。 BPL 允许在业务流程中使用“预先配置的集成组件”(活动)– 确切地说,这让我们有权声明 IRIS 支持“持续集成”。 预配置的业务流程组件(活动和活动之间的链接)对于装配人工智能/机器学习解决方案而言是极其强大的加速器。 不仅用于装配:由于活动及其链接,在不同的人工智能/机器学习机制之上引入了“自主管理层”,能够根据具体情况做出实时决策。
图 16:InterSystems IRIS 平台中用于持续集成 (CI) 的预配置业务流程组件
代理系统(又名 “多代理系统”)的概念在机器人化领域被广泛接受,InterSystems IRIS 平台通过其“生产/流程”结构为其提供有机支持。 除了使用整体解决方案所需的功能“武装”每个流程的无限能力之外,“代理”作为平台内流程家族中的一员,能够为非常不稳定的建模现象(社会/生物系统的行为, 实施部分观察的制造过程等)创建高效的解决方案。
图 17:在 InterSystems IRIS 中以业务流程代理系统形式运行的人工智能/机器学习解决方案
现在继续概述 InterSystems IRIS 平台,我们将向您展示包含适用于所有实时场景类别的解决方案的应用领域(我们在之前的一期在线讲座中提供了对一些基于 InterSystems IRIS 的平台内人工智能/机器学习最佳做法的十分详细的发现) 。 紧接上图,我们在下面提供了一幅更具说明性的代理系统图。 在该图中,完全相同的原型显示了其四个代理流程以及它们之间的交互: GENERATOR – 模拟设备传感器的生成数据;BUFFER – 管理数据处理队列;ANALYZER – 执行机器学习;MONITOR – 监控机器学习质量以及在有必要重新训练模型时发出信号。
图 18:在 InterSystems IRIS 中以业务流程代理系统形式构成的人工智能/机器学习解决方案
下图展示了不同机器人化原型(文本情感分析)在一段时间内的运行。 上半部分 – 模型训练质量指标演变(质量提高),下半部分 – 模型应用质量指标和重新训练(红条)的动态。 正如所见,该解决方案显示出有效且自主的自我训练,同时继续以所需的质量水平运行(质量指标值保持在 80% 以上)。
图 19:基于 InterSystems IRIS 平台的持续(自)训练 (CT)
我们之前已经提到过“自动机器学习”,在下图中,我们将以另一个原型为例提供有关此功能的更多详细信息。 在业务流程片段图中,我们看到了在 H2O 框架中启动建模的活动,以及该建模的结果(与其他“手工”模型相比,获得的模型在 ROC 曲线方面具有明显优势,以及自动检测原始数据集中可用变量中“最具影响力的变量”)。 这里的一个重要优势是“自动机器学习”可节省时间并提供专家资源:我们的平台内流程可以在半分钟内交付专家可能需要一周到一个月时间才能完成的工作(确定和证明最佳模型)。
图 20:在基于 InterSystems IRIS 平台的人工智能/机器学习解决方案中嵌入的“自动机器学习”
下图“直击高潮”,同时也很好地将有关各类实时场景的故事推向尾声:在此提醒您,尽管 InterSystems IRIS 可提供所有平台内功能,但在其编排下训练模型并非强制要求。 该平台可以接收来自在非平台编排工具中训练的模型的外部来源的所谓 PMML 规范,然后自其导入 PMML 规范之时起继续实时应用该模型。 请务必记住,尽管大多数最广泛使用的人工智能/机器学习工件都支持,但并非每个给定的人工智能/机器学习工件都可以解析为 PMML 规范。 因此,InterSystems IRIS 是一种开放的平台,对其用户而言完全不存在“平台奴役”情况。
图 21:InterSystems IRIS 平台中基于 PMML 规范的模型应用
让我们聊聊 InterSystems IRIS 平台的其他优势(为了更好地说明,请参考制造过程管理),这些优势对于人工智能和机器学习的实时自动化非常重要:
在 InterSystems IRIS 平台中实现的人工智能/机器学习解决方案可轻松适应现有的 IT 基础架构。 得益于高可用性和灾难恢复配置支持,以及在虚拟环境、物理服务器、私有云和公共云、Docker 容器中的灵活部署能力,InterSystems IRIS 能够有效保障人工智能/机器学习解决方案的可靠性。 也就是说,InterSystems IRIS 确实是实时人工智能/机器学习计算的多功能通用平台。 我们平台的多功能特质在实际应用中得到了证明:对实现计算的复杂性实际上毫无限制;InterSystems IRIS 能够结合(实时)执行不同行业的场景;具有出色的适应性,能够提供满足用户具体需求的任何平台内功能和机制。
图 22:InterSystems IRIS — 适用于实时人工智能/机器学习计算的多功能通用平台
为了与对本文感兴趣的读者进行更加具体的对话,我们建议您继续与我们进行“实时”交流。 我们将随时提供支持,制定与贵公司具体情况相吻合的实时人工智能/机器学习场景,运行基于 InterSystems IRIS 平台的协作原型设计,设计和执行路线图以在您的制造及管理过程中实现人工智能和机器学习。 我们人工智能/机器学习专家团队的联系电子邮件:MLToolkit@intersystems.com。
Intersystems RIS 机器学习工具包, 包括Python/R/Julia, 支持协调管理基于云的高级分析服务,如微软Azure数据工厂和机器学习。
什么是分布式人工智能 (DAI)?
试图找到一个“无懈可击”的定义是徒劳的:这个术语似乎有些“超前”。 但是,我们仍然可以从语义上分析该术语本身,推导出分布式人工智能也是人工智能(请参见我们为提出一个“实用”定义所做的努力),只是它分布在多台没有聚合在一起(既不在数据方面,也不通过应用程序聚合,原则上不提供对特定计算机的访问)的计算机上。 即,在理想情况下,分布式人工智能的安排方式是:参与该“分布”的任何计算机都不能直接访问其他计算机的数据和应用程序,唯一的替代方案是通过“透明的”消息传递来传输数据样本和可执行脚本。 与该理想情况的任何偏差都会导致出现“部分分布式人工智能”- 一个示例是通过中央应用程序服务器分发数据, 或者其反向操作。 不管怎样,我们都会得到一组“联合”模型(即,在各自数据源上训练的模型,或者按自己的算法训练的模型,或者同时以这两种方式训练的模型)。
“面向大众”的分布式人工智能方案
我们不会讨论边缘计算、机密数据操作员、分散的移动搜索,或者类似的引人入胜但又不是最有意识和最广泛应用(目前不是)的方案。 我们将更“贴近于生活”,例如,如果考虑以下方案(其详细演示应该可以在此处观看):一家公司运行一个生产级 AI/ML 解决方案,其运行质量正在由一名外部数据科学家(即,不是该公司员工的专家)系统地进行检查。 由于种种原因,该公司无法授予数据科学家访问该解决方案的权限,但可以按照时间表或在特定事件(例如,解决方案终止一个或多个模型的训练会话)后向其发送所需表中的记录样本。 我们据此假定,该数据科学家拥有某个版本的 AI/ML 机制,且这些机制已经集成在公司正在运行的生产级解决方案中,而且数据科学家本人很可能正在开发、改进和调整这些机制,以适应该具体公司的具体用例。 将这些机制部署到正在运行的解决方案中、监控机制的运行以及其他生命周期方面的工作由一名数据工程师(公司员工)负责。
我们在这篇文章中提供了一个在 InterSystems IRIS 平台上部署生产级 AI/ML 解决方案的示例,该解决方案可自主处理来自设备的数据流。 上一段提供的链接下的演示中也运行了相同的解决方案。 您可以使用我们的仓库 Convergent Analytics 中的内容(免费且无时间限制,请访问 Links to Required Downloads 和 Root Resources 部分)在 InterSystems IRIS 上构建您自己的解决方案原型。
通过这样的方案,我们可获得“分布程度”如何的人工智能? 在我们看来,此方案相当接近理想情况,因为数据科学家与公司的数据和算法均保持“切割”(只是传输了有限的样本,但在某个时间点前很重要;而且数据科学家自己的“样本”永远不会与作为实时生产级解决方案的一部分部署和运行的“活跃”机制 100% 同步),他完全不能访问公司的 IT 基础架构。 因此,数据科学家的作用变为在他的本地计算资源上部分重放该公司生产级 AI/ML 解决方案的运行片段,获得可接受置信级别的运行质量评估,并向公司返回反馈(在我们的具体方案中,以“审核”结果表示,可能还加上该公司解决方案涉及的 AI/ML 机制的改进版本)。

图 1 分布式人工智能方案表示
我们知道,在人类执行人工智能项目交换的过程中,不一定需要表示和传输反馈,这源于有关现代方法的出版物以及已有的分布式人工智能实现经验。 但是,InterSystems IRIS 平台的优势在于,它允许同样高效地开发和启动“混合”(人类和机器串联)且完全自动化的人工智能用例,因此,我们将继续根据上述“混合”示例进行分析,同时为读者留下自行阐述其完全自动化的可能性。
如何在 InterSystems IRIS 平台上运行具体的分布式人工智能方案
本文上一节提到的带有方案演示的视频介绍对作为实时 AI/ML 平台的 InterSystems IRIS 进行了总体概述,并解释了其对 DevOps 宏机制的支持。 在演示中,没有明确覆盖负责定期将训练数据集传输给外部数据科学家的“公司侧”业务流程,因此,我们将从该业务流程及其步骤的简介开始。
发送方业务流程的一个主要“引擎”是 while 循环(使用 InterSystems IRIS 可视业务流程编辑器实现,该编辑器基于平台解释的 BPL 表示法),负责将训练数据集系统地发送给外部数据科学家。 该“引擎”内部执行以下操作(参见下图,跳过数据一致性操作):

图 2“发送方”业务流程的主要部分
(a) 负载分析器 – 将训练数据集表中的当前记录集加载到业务流程中,并基于它在 Python 会话中形成一个数据框架。 调用操作会触发对 InterSystems IRIS DBMS 的 SQL 查询,并触发对 Python 接口的调用以将 SQL 结果传输给它,以便形成数据框架;
(b) Azure 分析器 – 另一个调用操作,触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从而在 Azure 中构建所需的基础架构,并在该基础架构上部署前一个操作中形成的数据框架数据;
作为执行上述业务流程操作的结果,我们在 Azure 中获得一个存储对象(一个 .csv 文件),其中包含公司的生产级解决方案用于模型训练的最近数据集的导出:

图 3 训练数据集“到达”Azure ML
这样,发送方业务流程的主要部分已经结束,但是我们还需要再执行一个操作,同时请记住,我们在 Azure ML 中创建的任何计算资源都是可计费的(参见下图,跳过数据一致性操作):

图 4“发送方”业务流程的最后部分
(c) 资源清理 – 触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从 Azure 中删除上一个操作中构建的计算基础架构。
数据科学家所需的数据已经传输完毕(数据集现在在 Azure 中),因此我们可以继续启动将访问数据集的“外部”业务流程,运行至少一次替代模型训练(从算法上讲,替代模型不同于作为生产级解决方案一部分运行的模型),并向数据科学家返回得到的模型质量指标及可视化,从而表示有关公司生产级解决方案运行效率的“审核结果”。
我们现在看一下接收方业务流程:与发送方业务流程(在包含公司自主 AI/ML 解决方案的其他业务流程中运行)不同,它不需要 while 循环,而是包含与在 Azure ML 和 IntegratedML(InterSystems IRIS 中用于自动 ML 框架的加速器)中训练替代模型有关的一系列操作,并将训练结果提取到 InterSystems IRIS 中(该平台也被认为在数据科学家处本地安装):

图 5“接收方”业务流程
(a) 导入 Python 模块 – 触发对 Python 接口的调用,以向其传输一组指令,导入进一步操作所需的 Python 模块;
(b) 设置 AUDITOR 参数 – 触发对 Python 接口的调用,以向其传输一组指令,为进一步操作所需的变量指定默认值;
(c) Azure ML 审核 –(我们将跳过任何对 Python 接口触发的进一步引用)将“审核任务”提交到 Azure ML;
(d) 解释 Azure ML – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起获取到本地 Python 会话中(此外,在 Python 会话中创建“审核”结果的可视化);
(e) 流式传输到 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从本地 Python 会话中提取到 IRIS 中的业务流程变量;
(f) 填充 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从 IRIS 中的业务流程变量写入 IRIS 中的表;
(g) IntegratedML 审核 – 使用 IntegratedML 加速器“审核”从 Azure ML 接收的数据以及上一个操作中写入 IRIS 的 Azure ML“审核”结果(在此特定情况下,该加速器处理 H2O auto-ML 框架);
(h) 对 Python 进行查询 – 将数据和 IntegratedML“审核”结果传输到 Python 会话中;
(i) 解释 IntegratedML – 在 Python 会话中,创建 IntegratedML“审核”结果的可视化;
(j) 资源清理 – 从 Azure 中删除先前的操作中创建的计算基础架构。

图 6 Azure ML“审核”结果的可视化

图 7 IntegratedML“审核”结果的可视化
分布式人工智能一般如何在 InterSystems IRIS 平台上实现
InterSystems IRIS 平台实现分布式人工智能有三种基本方法:
· 根据用户定义的规则和算法,直接交换人工智能项目,并对其进行本地和中央处理
· 人工智能项目处理委托给专门的框架(例如:TensorFlow、PyTorch),交换的编排和各个准备步骤由用户在 InterSystems IRIS 的本地和中央实例上配置
· 人工智能项目的交换和处理都通过云提供商(Azure、AWS、GCP)来完成,本地和中央实例只向云提供商发送输入数据并接收最终结果

图 8 在 InterSystems IRIS 平台上实现分布式人工智能的基本方法
这些基本方法可以修改/组合使用:尤其是,在本文的上一节(“审核”)所描述的具体方案中,使用了第三种方法“以云为中心”,将“审核员”部分划分到云端,而在数据科学家一侧执行本地部分(作为“中央实例”)。
目前,在我们生活的现实中,“分布式人工智能”学科的理论和应用要素正在不断积累,但还没有形成“规范形式”,这使得创新实现具有巨大潜力。 我们的专家团队密切关注分布式人工智能作为一门学科的发展,并为其在 InterSystems IRIS 平台上的实现设计加速器。 我们乐于分享我们的内容,并帮助每一个认为这里讨论的领域有用的人开始分布式人工智能机制的原型设计。 您可以使用以下电子邮件地址联系我们的 AI/ML 专家团队 – MLToolkit@intersystems.com。
去年,AWS推出了基于ARM架构的AWS Graviton处理器第一代Amazon EC2 A1实例。在2019年AWS re:Invent 大会上,亚马逊宣布了第二代AWS Graviton2处理器和相关的Amazon EC2 M6g实例。相比前一代基于Intel Xeon的M5实例,Amazon EC2 M6g实例的性价比提升幅度高达40%。
AWS 的核心是 Amazon EC2。它是支持各种操作系统和机器配置(例如 CPU、RAM、网络)的云计算基础设施。 AWS 提供预先配置的虚拟机 (VM) 映像(称为 Amazon 系统映像或 AMI),客户操作系统包括各种 Linux® 和 Windows 发行版及版本。可以将其它软件用作 AWS 中运行的虚拟化实例的基础。您可以将这些 AMI 用作实例化以及安装或配置其他软件、数据等的起点,以创建特定于应用程序或工作负载的 AMI。
与任何平台或部署模式一样,必须留心以确保考虑到应用程序环境的各个方面,例如性能、可用性、操作和管理程序。
本文将详细介绍以下每个方面。
本文提供了一个参考架构,作为示例说明基于 InterSystems Technologies(适用于 Caché、Ensemble、HealthShare、TrakCare 以及相关的嵌入式技术,例如 DeepSee、iKnow、Zen 和 Zen Mojo)提供的强大性能和高可用性应用。
Azure 有两种用于创建和管理资源的不同部署模型:Azure Classic 和 Azure Resource Manager。本文中的详细信息基于 Azure Resource Manager (ARM) 模型。
Amazon Web Services (AWS) 云提供广泛的云基础设施服务,例如计算资源、存储选项和网络,这些都非常实用:按需提供,几秒内就可用,采用即付即用定价的模式。 新服务可得到快速配置,且前期无需支出大量资金。 这使得大企业、初创公司、中小型企业以及公共部门的客户可以访问他们所需的基础设施,从而快速响应不断变化的业务需求。
更新日期:2019 年 10 月 15 日
Google Cloud Platform (GCP) 为基础架构即服务 (IaaS) 提供功能丰富的环境,其作为云提供完备的功能,支持所有的 InterSystems 产品,包括最新的 InterSystems IRIS 数据平台。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、操作和管理程序。 本文将详细阐述所有这些方面。
以下概述和详细内容由谷歌提供,可在此处找到。
GCP 由一系列物理资产(例如计算机和硬盘驱动器)和虚拟资源(例如虚拟机(VM))组成,它们分布于谷歌遍布全球的数据中心。 每个数据中心的位置都是一个泛区域。 每个区域都是地区的集合,这些地区在该区域内彼此分离。 每个地区都通过一个名称标识,名称由字母标识符和相应区域的名称组成。
这种资源分配带来众多优势,包括发生故障时提供冗余,以及通过将资源配置在客户端附近来减少延迟。 这种分配也引入一些有关如何统筹资源的规则。
在云计算中,物理硬件和软件变成了服务。 这些服务提供对基础资源的访问。 在 GCP 上开发基于 InterSytems IRIS 的应用程序时,您可混合和匹配这些服务,组合它们来提供您所需的基础架构,然后添加您的代码来实现您要构建的方案。 有关可用服务的详细信息, 可在此处找到。
您分配和使用的任何 GCP 资源必须属于一个项目。 项目由设置、权限和其他描述应用程序的元数据组成。 根据区域和地区规则,单个项目中的资源能够轻松协作,例如通过内部网络进行通信。 每个项目包含的资源在项目边界上保持独立;您只能通过外部网络连接来互连它们。
GCP 提供 3 种与服务和资源交互的基本方法。
Google Cloud Platform 控制台提供基于 web 的图形用户界面,供您管理 GCP 项目和资源。 使用 GCP 控制台,您可创建新项目,或选择现有项目,可使用您在项目环境中创建的资源。 您可以创建多个项目,因此您可以使用项目以任何对您有意义的方式分开您的工作。 例如,如果您想确保只有某些团队成员可以访问项目中的资源,而所有团队成员可以继续访问另一个项目中的资源,则可以开始一个新项目。
如果您喜欢在终端窗口中工作,Google Cloud SDK 提供 gcloud 命令行工具,让您可以访问所需的命令。 gcloud 工具可用于管理您的开发工作流程和 GCP 资源。 有关 gcloud 的详细内容可在此处找到。
GCP 也提供 Cloud Shell,一种基于浏览器的 GCP 交互 shell 环境。 可从 GCP 控制台访问 Cloud Shell。 Cloud Shell 提供:
Cloud SDK 拥有客户端库,让您轻松创建和管理资源。 GCP 客户端库公开 API 有两个主要目的:
您还可以使用 Google API 客户端库来访问产品的 API,如 Google Map、Google Drive 和 YouTube。 有关 GCP 客户端库的详细信息可在此处找到。
本文部分内容阐述了面向 GCP 的 InterSystems IRIS 部署示例,旨在为特定应用程序的部署抛砖引玉。 这些示例可用作很多部署方案的指南。 此参考体系结构拥有非常强大的部署选项,从最小规模的部署,到满足计算和数据需求的大规模可扩展工作负载,不一而足。
本文还介绍了高可用性和灾难恢复选项以及其他建议的系统操作。 个体可对这些进行相应的修改以支持其组织的标准实践和安全策略。
针对您的特定应用,就基于 GCP 的 InterSystems IRIS 部署,您可联系 InterSystems 进一步探讨。
以下示例体系结构按照容量和功能逐步升级的顺序讲述了几种不同的配置, 分别为小型开发/生产/大型生产/分片集群生产。先从中小型配置讲起,然后讲述具有跨地区高可用性以及多区域灾难恢复的大规模可扩展性解决方案。 此外,还讲述了一个将 InterSystems IRIS 数据平台的新分片功能用于大规模处理并行 SQL 查询的混合工作负载的示例。
在本示例中,显示了一个能支持 10 名开发人员和 100GB 数据的小型开发环境,这基本是最小规模的配置。 只要适当地更改虚拟机实例类型并增加持久性磁盘存储,即可轻松支持更多的开发人员和数据。
这足以支持开发工作,并让您熟悉 InterSystems IRIS 功能以及 Docker 容器的构建和编排(如果需要的话)。 小型配置通常不采用具有高度可用性的数据库镜像,但是如果需要高可用性,则可随时添加。
示例图 2.1.1-a 显示了图表 2.1.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
.png)
下列 GCP VPC 项目资源是针对最小规模的配置提供的。 可根据需求添加或删除 GCP 资源。
下表提供了小型配置 GCP 资源的示例。
.png)
需要考虑适当的网络安全和防火墙规则,以防止对 VPC 的不必要访问。 谷歌提供网络安全最佳做法供您入门使用,可在此处找到。
如果您的安全策略确实需要内部 VM 实例,则您需要在网络上手动设置 NAT 代理和相应的路由,以便内部实例可以访问互联网。 务必要明确,您无法使用 SSH 直接完全连接到内部 VM 实例。 要连接到此类内部机器,必须设置具有外部 IP 地址的堡垒实例,然后建立隧道通过它。 可以配置堡垒主机,以提供进入 VPC 的外部入口点。
有关堡垒主机的详细信息,可在此处找到。
在本示例中,展示了一个规模较大的产品配置,其采用 InterSystems IRIS 数据库镜像功能来支持高可用性和灾难恢复。
此配置包括 InterSystems IRIS 数据库服务器同步镜像对,该镜像服务器在区域 1 内分为两个地区,用于自动故障转移,在区域 2 内的第三个 DR 异步镜像成员用于灾难恢复,以防万一整个 GCP 区域脱机 。
InterSystems Arbiter 和 ICM 服务器部署在单独的第三个地区,以提高弹性。 此示例体系结构还包括一组可选的负载均衡 web 服务器,用于支持启用 Web 的应用程序。 这些使用 InterSystems 网关的 web 服务器可以根据需要进行缩放。
示例图 2.2.1-a 显示了图表 2.2.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
.png)
建议将以下 GPC VPC 项目中的资源作为分片集群部署的最低配置。 可根据需求添加或删除 GCP 资源。
下表提供了产品配置 GCP 资源的示例。
.png)

在本示例中,提供了一个大规模可缩放性配置。该配置通过扩展 InterSystems IRIS 功能也引入使用 InterSystems 企业缓存协议 (ECP:EnterpriseCacheProtocol) 的应用程序服务器,实现对用户的大规模横向缩放。 本示例甚至包含了更高级别的可用性,因为即使在数据库实例发生故障转移的情况下,ECP 客户端也会保留会话细节。 多个 GCP 地区与基于 ECP 的应用程序服务器和部署在多个区域中的数据库镜像成员一起使用。 此配置能够支持每秒数千万次的数据库访问和数万亿字节数据。
示例图 2.3.1-a 显示了图表 2.3.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括一个故障转移镜像对,四个或更多的 ECP 客户端(应用程序服务器),以及每个应用程序服务器对应一个或多个 Web 服务器。 故障转移数据库镜像对在同一区域中的两个不同 GCP 地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
灾难恢复扩展至第二个 GCP 区域和地区,与上一示例中的情况类似。 如果需要,可以将多个 DR 区域与多个 DR 异步镜像成员目标一起使用。

建议将以下 GPC VPC 项目中的资源作为大型生产部署的最低配置。 可根据需求添加或删除 GCP 资源。
下表提供了大型产品配置 GCP 资源的示例。



在此示例中,提供了一个针对 SQL 混合工作负载的横向缩放性配置,其包含 InterSystems IRIS 的新分片集群功能,可实现 SQL 查询和表跨多个系统的大规模横向缩放。 本文后面将详细讨论 InterSystems IRIS 分片集群及其功能。
示例图 2.4.1-a 显示了图表 2.4.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括四个镜像对,它们为数据节点。 每个故障转移数据库镜像对在同一区域中的两个不同 GCP 地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
此配置允许从集群中的任何数据节点使用所有的数据库访问方法。 大型 SQL 表数据在物理上跨所有数据节点进行分区,以实现查询处理和数据卷的大规模并行。 将所有这些功能组合在一起,就可以支持复杂的混合工作负载,比如大规模分析 SQL 查询及引入的新数据,所有这一切均在一个 InterSystems IRIS 数据平台中执行。

注意,上面图表中以及下表“资源类型”列中的术语“计算[Engine]”是一个表示 GCP(虚拟)服务器实例的 GCP 术语,将在本文的 3.1节中做进一步介绍。 它并不表示或暗示本文后面所描述的集群体系结构中对“计算节点”的使用。
建议将以下 GPC VPC 项目中的资源作为分片集群部署的最低配置。 可根据需求添加或删除 GCP 资源。
下表提供了分片集群配置 GCP 资源的示例。

Google Cloud Platform (GCP) 为基础架构即服务 (IaaS) 提供功能丰富的云环境,使其具备完备的功能,支持所有的 InterSystems 产品,包括支持基于容器的 DevOps 及最新的 InterSystems IRIS 数据平台。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、系统操作、高可用性、灾难恢复、安全控制和其他管理程序。 本文档将介绍所有云部署涉及的三个主要组件:计算、存储和网络。
GCP 中存在数个针对计算引擎资源的选项,以及众多虚拟 CPU 和内存规范及相关存储选项。 在 GCP 中值得注意的一点是,对给定机器类型中 vCPU 数量的引用等于一个 vCPU,其是虚拟机监控程序层上物理主机中的一个超线程。
就本文档的目的而言,将使用 n1-standard * 和 n1-highmem * 实例类型,这些实例类型在大多数 GCP 部署区域中广泛可用。 但是,对于将大量数据缓存在内存中的大型工作数据集而言,使用 n1-ultramem * 实例类型是不错的选择。 除非另有说明,否则使用默认实例设置(例如实例可用性策略)或其他高级功能。 有关各种机器类型的详细信息,可在此处找到。
与 InterSystems 产品最直接相关的存储类型是持久性磁盘类型,但是,只要了解并适应数据可用性限制,本地存储可以用于高水平的性能。 还有其他一些选项,例如云存储(存储桶),但是这些选项更特定于单个应用程序的需求,而非支持 InterSystems IRIS 数据平台的操作。
与大多数其他云提供商一样,GCP 对可与单个计算引擎关联的持久性存储施加了限制。 这些限制包括每个磁盘的最大容量、关联到每个计算引擎的持久性磁盘的数量,以及每个持久性磁盘的 IOPS 数量,对单个计算引擎实例 IOPS 设置上限。 此外,对每 GB 磁盘空间设有 IOPS 限制,因此有时需要调配更多磁盘容量才能达到所需的 IOPS 速率。
这些限制可能会随着时间而改变,可在适当时与谷歌确认。
磁盘卷有两种类型的持久性存储类型:“标准持久性”磁盘和“SSD 持久性”磁盘。 SSD 持久性磁盘更适合于那些要求低延迟 IOPS 和高吞吐量的生产工作负载。 标准持久性磁盘对于非生产开发和测试或归档类型的工作负载,是一种更经济的选择。
有关各种磁盘类型及限制的详细信息,可在此处找到。
强烈建议采用虚拟私有云 (VPC) 网络来支持 InterSystems IRIS 数据平台的各个组件,同时提供正确的网络安全控制、各种网关、路由、内部 IP 地址分配、网络接口隔离和访问控制。 本文档中提供了一个详细的 VPC 示例。
有关 VPC 网络和防火墙的详细信息,可在此处找到。
GCP VPC 与其他云提供商略有不同,其更加简单和灵活。 可在此处找到各概念的比较。
在 GCP 项目中,每个项目允许有数个 VPC(目前每个项目最多允许 5 个),且创建 VPC 网络有两个选项——自动模式和自定义模式。
此处提供每个类型的详细信息。
在大多数大型云部署中,采用多个 VPC 将各种网关类型与以应用为中心的 VPC 进行隔离,并利用 VPC 对等进行入站和出站通信。 有关适合您的公司使用的子网和任何组织防火墙规则的详细信息,强烈建议您咨询您的网络管理员。 本文档不阐述 VPC 对等方面的内容。
在本文档提供的示例中,使用 3 个子网的单一 VPC 用于提供各种组件的网络隔离,以应对各种 InterSystems IRIS 组件的可预测延迟和带宽以及安全性隔离。
本文档的示例中提供了两种网关,以支持互联网和安全 VPN 连接。 要求每个入口访问都具有适当的防火墙和路由规则,从而为应用程序提供足够的安全性。 有关如何使用路由的详细信息,可在此处找到。
提供的示例体系结构中使用了 3 个子网,它们专与 InterSystems IRIS 数据平台一起使用。 这些单独的网络子网和网络接口的使用为上述 3 个主要组件的每一个提供了安全控制、带宽保护和监视方面的灵活性。 有关各种用例的详细信息,可在此处找到。
有关创建具有多个网络接口的虚拟机实例的详细信息,可在此处找到。
这些示例中包含的子网:
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在自动化数据库故障转移设计中。 为了解决这一问题,InterSystems IRIS 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 Web 网关,从而不再依赖 VIP 功能使它们实现镜像感知和自动化。
xDBC、直接 TCP/IP 套接字等连接方法,或其他的直接连接协议,均需要使用类 VIP 地址。 为了支持这些入站协议,InterSystems 数据库镜像技术使用称作<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>的健康检查状态页面为 GCP 中的这些连接方法提供自动化故障转移,以与负载均衡器进行交互,实现负载均衡器的类 VIP 功能,仅将流量重定向至活动的主镜像成员,从而在 GCP 内实现完整且强大的高可用性设计。
.png)
此处提供了使用负载均衡器实现类 VIP 功能的详细信息。
下图 4.3-a 中的 VPC 布局组合了所有组件,具有以下特点:

如简介中所述,建议使用 GCP 持久性磁盘,尤其 SSD 持久性磁盘类型。 之所以推荐 SSD 持久性磁盘,是由于其拥有更高的读写 IOPS 速率以及低的延迟,适合于事务性和分析性数据库工作负载。 在某些情况下,可使用本地 SSD,但值得注意的是,本地 SSD 的性能提升会在可用性、耐用性和灵活性方面做出一定的权衡。
可在此处找到本地 SSD 数据持久性方面的详细信息,您可了解何时保存本地 SSD 数据以及何时不保存它们。
与其他的云提供商一样,GCP 在每个虚拟机实例的 IOPS、空间容量和设备数量方面都施加了众多存储限制。 有关当前的限制,请查阅 GCP 文档,可在此处找到。
由于这些限制的存在,使用 LVM 条带化实现数据库实例的单个磁盘设备的 IOPS 最大化变得非常必要。 在提供的此示例虚拟机实例中,建议使用以下磁盘布局。 与 SSD 持久性磁盘相关的性能限制可在此处找到。

LVM 条带化的优势在于可以将随机的 IO 工作负载分散到更多的磁盘设备并继承磁盘队列。 以下是如何在 Linux 中将 LVM 条带化用于数据库卷组的示例。 本示例在一个 LVM PE 条带中使用 4 个磁盘,物理盘区 (PE) 大小为 4MB。 或者,如果需要,可以使用更大的 PE 容量。
使用上表,每个 InterSystems IRIS 服务器将具有以下配置:2 个 SYS 磁盘、4 个 DB 磁盘、2 个主日志磁盘、2 个备用日志磁盘。

为了增长,LVM 允许在需要的情况下不中断地扩展设备和逻辑卷。 有关持续管理和扩展 LVM 卷的最佳做法,请查阅 Linux 文档。
InterSystems IRIS 新增了 InterSystems Cloud Manager (ICM)。 ICM 执行众多任务,并提供许多用于配置 InterSystems IRIS 数据平台的选项。 ICM 作为 Docker 映像提供,其拥有配置强大的、基于 GCP 云的解决方案所需的一切。
ICM 当前支持以下平台上的配置:
ICM 和 Docker 可以从台式机/笔记本电脑工作站运行,也可以具有中央专用的适度“配置”服务器和中央存储库。
ICM 在应用程序生命周期中的作用是“定义->配置->部署->管理”
有关安装和使用 ICM 及 Docker 的详细信息,可在此处找到。
ICM 包含基本的监视工具,其使用 Weave Scope 进行基于容器的部署。 默认情况下不会部署该工具,需要在默认的文件中使用监视器字段指定它。
有关使用 ICM 进行监视、编排和调度的详细信息,可在此处找到。
有关 Weave Scope 的概述和该文档,可在此处找到。
InterSystems 数据库镜像可在任何云环境中提供最高级别的可用性。 有一些选项可以直接在实例级别提供虚拟机弹性。 有关 GCP 中可用的各种政策的详细信息,可在此处找到。
上文中已讨论了云负载均衡器如何通过数据库镜像为虚拟 IP(类 VIP)功能提供自动化 IP 地址故障转移。 云负载均衡器使用<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>健康检查状态页面,上文内部负载均衡器部分提到过该页面。 数据库镜像有两种模式——自动故障转移同步镜像、异步镜像。 在本示例中,将介绍同步故障转移镜像。 有关镜像的详细信息,可在此处找到。
最基本的镜像配置是仲裁器控制配置中的一对故障转移镜像成员。 仲裁器放置在同一区域内的第三个地区中,以防止潜在的地区中断影响仲裁器和其中一个镜像成员。
在网络配置中,有多种方法专供设置镜像。 在本示例中,我们将使用本文档前述网络网关和子网定义部分中定义的网络子网。 下一部分内容将提供 IP 地址方案示例,并且基于本部分内容,将仅描述网络接口和指定的子网。

InterSystems 数据库镜像将支持灾难恢复的高可用性功能扩展到另一个 GCP 地理区域,以在整个 GCP 区域万一脱机的情况下支持操作弹性。 应用程序如何耐受此类中断取决于恢复时间目标 (RTO) 和恢复点目标 (RPO)。 这些将为设计适当的灾难恢复计划进行的分析提供初始框架。 以下链接中的指南提供了您在为自己的应用程序制定灾难恢复计划时要考虑的事项。 https://cloud.google.com/solutions/designing-a-disaster-recovery-plan 和 https://cloud.google.com/solutions/disaster-recovery-cookbook
InterSystems IRIS 数据平台的数据库镜像提供强大的功能,可在 GCP 地区和区域之间异步复制数据,以帮助支持您的灾难恢复计划的 RTO 和 RPO 目标。 有关异步镜像成员的详细信息,可在此处找到。
与上述高可用性部分中讲述的内容相似,云负载均衡器也使用上文内部负载均衡器部分中提到过的<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>健康检查状态页面为虚拟 IP(类 VIP)功能提供自动化 IP 地址故障转移,以进行 DR 异步镜像。
在本示例中,将介绍 DR 异步故障转移镜像,并介绍 GCP 全局负载均衡服务,以便为上游系统和客户端工作站提供单个任播 IP 地址,不分您的 InterSystems IRIS 部署是否在哪个区域或地区中运行。
GCP 的其中一个发展就是负载均衡器的诞生,这是一种软件定义的全局资源,并且不受制于特定的区域。 由于其不是基于实例或设备的解决方案,因此它具有跨区域利用单个服务的独特功能。 有关通过单个任播 IP 进行 GCP 全局负载均衡的详细信息,可在此处找到。
.png)
在上述示例中,所有 3 个 InterSystems IRIS 实例的 IP 地址都提供给了 GCP 全局负载均衡器,它会将流量仅定向到承担主要镜像的镜像成员,而不论其位于哪个地区或区域。
InterSystems IRIS 拥有一系列全面的功能来缩放您的应用程序,您可以根据自己工作负载的性质以及所面临的特定性能挑战来单独或组合应用这些功能。 分片功能是这些功能中的一种,可跨多个服务器对数据及其关联的缓存进行分区,从而为查询和数据引入提供灵活、高性价比的性能扩展,同时通过高效的资源利用最大化基础架构的价值。 InterSystems IRIS 分片群集可以为各种应用提供显著的性能优势,尤其对于工作负载包括以下一项或多项的应用更是如此:
这些因素分别都会影响分片的潜在优势,但组合起来使用它们可能会增加优势。 例如,这 3 个因素的组合——快速引入大量数据、大型数据集、检索和处理大量数据的复杂查询——使得当今的许多分析性工作负载非常适合进行分片。
注意,这些特征都与数据有关;InterSystems IRIS 分片的主要功能是缩放数据量。 不过,当涉及某些或所有这些与数据相关的因素的工作负载也经历大量用户的超高查询量时,分片群集也能提供用户量缩放功能。 分片也可以与纵向缩放相结合。
分片架构的核心是跨多个系统对数据及其关联的缓存进行分区。 分片集群跨多个 InterSystems IRIS 实例以行方式(称为数据节点)对大型数据库表进行物理上的横向分区,同时允许应用通过任何节点透明地访问这些表,但仍将整个数据集看作一个逻辑并集。 该架构具有 3 个优点:
有关 InterSystems IRIS 分片集群的详细信息,可在此处找到。
分片集群包含至少一个数据节点,如果特定性能或工作负载有需要,则可添加一定数量的计算节点。 这两种节点类型提供简单的构建块,从而实现简单、透明和高效的调整模型。
数据节点存储数据。 在物质层面,分片表[1]数据分布在集群中的所有数据节点上,非分片表数据仅物理存储在第一个数据节点上。 这种区分对用户是透明的,唯一可能的例外是,第一个节点的存储消耗可能比其他节点略高,但是由于分片表数据通常会超出非分片表数据至少一个数量级,因此这种差异可以忽略不计。
需要时,可以跨集群重新均衡分片表数据,这通常发生在添加新的数据节点后。 这将在节点之间移动数据的“存储桶”,以实现数据的近似均匀分布。
在逻辑层面,未分片的表数据和所有分片的表数据的并集在任何节点上都可见,因此客户端会看到整个数据集,这与其连接哪个节点无关。 元数据和代码也会在所有数据节点之间共享。
分片集群的基本架构图仅由在集群中看起来统一的数据节点组成。 客户端应用程序可以连接到任何节点,并且可以像在本地一样体验数据。

对于要求低延迟(可能存在不断涌入数据的冲突)的高级方案,可以添加计算节点以提供用于服务查询的透明缓存层。
计算节点缓存数据。 每个计算节点都与一个数据节点关联,为其缓存相应的分片表数据,此外,它还根据需要缓存非分片表数据,以满足查询的需要。

由于计算节点物理上并不存储任何数据,其只是支持查询执行,因此可对其硬件配置文件进行调整以满足需求,例如通过强调内存和 CPU 并将存储空间保持在最低限度。 当“裸露”应用程序代码在计算节点上运行时,引入数据会被驱动程序 (xDBC, Spark) 直接或被分片管理器代码间接转发到数据节点。
分片集群部署有多种组合。 下列各图说明了最常见的部署模型。 These diagrams do not include the networking gateways and details and provide to focus only on the sharded cluster components.
下图是在一个区域和一个地区中部署了 4 个数据节点的最简单分片群集。 GCP 云负载均衡器用于将客户端连接分发到任何分片集群节点。

在此基本模型中,除了 GCP 为单个虚拟机及其连接的 SSD 持久性存储提供的弹性或高可用性外,没有其他弹性或高可用性。 建议使用两个单独的网络接口适配器,一则为入站客户端连接提供网络安全隔离,二则为客户端流量和分片集群通信之间提供带宽隔离。
下图是在一个区域中部署了 4 个镜像数据节点的最简单分片集群,每个节点的镜像在地区之间进行了划分。 GCP 云负载均衡器用于将客户端连接分发到任何分片集群节点。
InterSystems 数据库镜像的使用带来了高可用性,其会在该区域内的第二地区中维护一个同步复制的镜像。
建议使用 3 个单独的网络接口适配器,一方面为入站客户端连接提供网络安全隔离,另一方面为客户端流量、分片集群通信、节点对之间的同步镜像流量之间提供带宽隔离。

此部署模型也引入了本文前面所述的镜像仲裁器。
下图采用单独的计算节点和 4 个数据节点扩展了分片集群,以此来应对大量的用户/查询并发。 云负载均衡器服务器池仅包含计算节点的地址。 更新和数据引入将像以前一样继续直接更新到数据节点,以维持超低延迟性能,并避免由于实时数据引入而在查询/分析工作负载之间造成资源的干扰和拥挤。
使用此模型,可以根据计算/查询和数据引入的规模单独微调资源分配,从而在“适时”需要的地方提供最佳资源,实现经济而简单的解决方案,而非只是进行计算或数据的调整,浪费不必要的资源。
计算节点非常适合直接使用 GCP 自动缩放分组(亦称自动缩放),允许基于负载的增加或减少自动从托管实例组添加或删除实例。 自动缩放的工作原理为:负载增加时,将更多的实例添加到实例组(扩展);对实例的需求降低时将其删除(缩减)。
有关 GCP 自动缩放的详细信息,可在此处找到。

自动缩放可帮助基于云的应用程序轻松应对流量增加的情况,并在资源需求降低时降低成本。 只需简单地定义自动缩放策略,自动缩放器就会根据测得的负载执行自动缩放。
备份操作有多个选项。 以下 3 个选项可供您通过 InterSystems IRIS 进行 GCP 部署。
下面的前 2 个选项(下文详细说明)采用快照类型的过程,该过程会在创建快照之前将数据库写入操作挂起到磁盘上,然后在快照成功后恢复更新。
可采取以下高级别步骤通过任一快照方法来创建洁净的备份:
有关外部冻结/解冻 API 的详细信息,可在此处找到。
第三个选项是 InterSystems 在线备份。 这是小型部署的入门级方法,具有非常简单的用例和界面。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,因为其具有以下优势:备份外部文件、更快的恢复时间,以及企业范围的数据和管理工具。
可以定期添加诸如完整性检查之类的其他步骤,以确保洁净且一致的备份。
决定使用哪种选项取决于您组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
可以使用 GCP gcloud 命令行 API 以及 InterSystems 外部冻结/解冻 API 功能实现备份操作。 这允许实现真正的 24x7 全天候操作弹性,并确保洁净常规备份。 有关管理、创建和自动化 GCP 持久性磁盘快照的详细信息,可在此处找到。
或者,可以在 VM 本身中部署单个备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
该模型的主要优点之一是能够对基于 Windows 或 Linux 的 VM 进行文件级恢复。 此解决方案需要注意的几点是,由于 GCP 和大多数其他 IaaS 云提供商都不提供磁带媒体,因此所有的备份存储库对于短期归档均基于磁盘,并能够利用 Blob 或存储桶类型的低成本存储来进行长期保留 (LTR)。 强烈建议您使用此方法来使用支持重复数据删除技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。
对于小型部署,内置在线备份工具也是可行的选择。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。 有关在线备份的详细信息,可在此处找到。
在 GCP 中,在线备份完成后,必须将备份输出文件和系统正在使用的所有其他文件复制到该虚拟机实例之外的其他存储位置。 存储桶/对象存储是对其很好的命名。
使用 GCP 存储桶有两种选择。
有关装载云存储桶(使用云存储 FUSE )的详细信息,可在此处找到。
假设你想了解 InterSystems 在数据分析方面能提供什么。 你研究了理论,现在想要进行一些实践。 幸运的是,InterSystems 提供了一个项目:Samples BI,其中包含了一些很好的示例。 从 README 文件开始,跳过任何与 Docker 相关的内容,直接进行分步安装。 启动虚拟实例 安装 IRIS,按照说明安装 Samples BI,然后用漂亮的图表和表格让老板眼前一亮。 到目前为止还不错。
但是不可避免地,你需要进行更改。
事实证明,自己保留虚拟机存在一些缺点,交给云服务商保管是更好的选择。 Amazon 看起来很可靠,你只需创建一个 AWS 帐户(入门免费),了解到使用 root 用户身份执行日常任务是有害的,然后创建一个常规的具有管理员权限的 IAM 用户。
点击几下鼠标,就可以创建自己的 VPC 网络、子网和虚拟 EC2 实例,还可以添加安全组来为自己开放 IRIS Web端口 (52773) 和 ssh 端口 (22)。 重复 IRIS 和 Samples BI 的安装。 这次使用 Bash 脚本,如果你喜欢,也可以使用 Python。 再一次让老板刮目相看。
但是无处不在的 DevOps 运动让你开始了解基础架构即代码,并且你想要实现它。 你选择了 Terraform,因为它是众所周知的,而且它的方法非常通用,只需微小调整即可适合各种云提供商。 使用 HCL 语言描述基础架构,并将 IRIS 和 Samples BI 的安装步骤转换到 Ansible。 然后再创建一个 IAM 用户使 Terraform 正常工作。 全部运行一遍。 获得工作奖励。
渐渐地你会得出结论,在我们这个微服务时代,不使用 Docker 就太可惜了,尤其是 InterSystems 还会告诉你怎么做。 返回到 Samples BI 安装指南并阅读关于 Docker 的几行内容,似乎并不复杂:
将浏览器定向到 http://localhost:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER 后,再次去老板那里,因为做得好而获得一天假期。
然后你开始明白,“docker run”只是开始,至少需要使用 docker-compose。 没问题:
这样你使用 Ansible 安装了 Docker 和 docker-compose,然后运行了容器,如果机器上还没有映像,则会下载一个映像。 最后安装了 Samples BI。
你一定喜欢 Docker,因为它是各种内核素材的又酷又简单的接口。 你开始在其他地方使用 Docker,并且经常启动多个容器。 还发现容器必须经常互相通信,这就需要了解如何管理多个容器。
终于,你发现了 Kubernetes。
从 docker-compose 快速切换到 Kubernetes 的一个方法是使用 kompose。 我个人更喜欢简单地从手册中复制 Kubernetes 清单,然后自己编辑,但是 kompose 在完成小任务方面做得很好:
现在你有了可以发送到某个 Kubernetes 集群的部署和服务文件。 你发现可以安装 minikube,它允许你运行一个单节点 Kubernetes 集群,这正是你现阶段所需要的。 在摆弄一两天 minikube 沙盒之后,你已经准备好在 AWS 云中的某处使用真实的 Kubernetes 部署。
设置
我们一起来进行吧。 此时,我们做以下几个假设:
首先,我们假设你有一个 AWS 帐户,你知道其 ID,并且未使用 root 凭据。 你创建了一个具有管理员权限且只能以编程方式访问的 IAM 用户(我们称之为“my-user”),并存储了其凭据。 你还创建了另一个具有相同权限的 IAM 用户,名为“terraform”:

Terraform 将以它的名义进入你的 AWS 帐户,并创建和删除必要资源。 这两个用户的广泛权限将通过演示来说明。 你在本地保存了这两个 IAM 用户的凭据:
注意:不要复制和粘贴上面的凭据。 它们在这里作为示例提供,不再存在。 请编辑 ~/.aws/credentials 文件并引入你自己的记录。
其次,我们将在文中使用虚拟的 AWS 帐户 ID (01234567890) 和 AWS 区域“eu-west-1”。 可以随意使用其他区域。
第三,我们假设你知道 AWS 不是免费的,你需要为使用的资源付费。
接下来,您已经安装了 AWS CLI 实用程序,以便与 AWS 进行命令行通信。 你可以尝试使用 aws2,但你需要在 kube 配置文件中特别设置 aws2 的用法,如这里所述。
你还安装了 kubectl 实用程序来与 AWS Kubernetes 进行命令行通信。
并且你也针对 docker-compose.yml 安装了 kompose 实用程序,来转换 Kubernetes 清单。
最后,你创建了一个空的 GitHub 仓库,并将其克隆到主机上。 我们将其根目录引用为
请注意,所有相关代码都在 github-eks-samples-bi 仓库中复制,以简化拷贝和粘贴。
我们继续。
AWS EKS 预置
我们已经在文章使用 Amazon EKS 部署简单的基于 IRIS 的 Web 应用程序中知道了 EKS。 那时,我们以半自动方式创建了一个集群。 即,我们在一个文件中描述集群,然后从本地机器手动启动 eksctl 实用程序,该实用程序根据我们的描述创建集群。
eksctl 是为创建 EKS 集群而开发的,它非常适合概念验证实现,但对于日常使用来说,最好使用更通用的工具,例如 Terraform。 AWS EKS 简介是一个非常好的资源,其中介绍了创建 EKS 集群所需的 Terraform 配置。 花一两个小时熟悉一下,决不会是浪费时间。
你可以在本地操作 Terraform。 为此,你需要一个二进制文件(在撰写本文时,我们使用最新的 Linux 版本 0.12.20),并且 IAM 用户“terraform”需要有足够的权限才能让 Terraform 进入 AWS。 创建目录
你可以创建一个或多个 .tf 文件(它们会在启动时合并)。 只需复制并粘贴 AWS EKS 简介中的代码示例,然后运行如下命令:
你可能会遇到一些错误。 如果遇到的话,可以在调试模式下操作,但记得稍后关闭该模式:
这个经验会很有用,你很可能会启动一个 EKS 集群(使用“terraform apply”进行该操作)。 在 AWS 控制台中查看:

觉得厌烦时就清理掉:
然后进入下一阶段,开始使用 Terraform EKS 模块,尤其它也基于同一 EKS 简介。 在 examples/ 目录中,你将看到如何使用它。 你还会在那里找到其他示例。
我们对示例进行了一定的简化。 以下是主文件,其中调用了 VPC 创建和 EKS 创建模块:
provider "kubernetes" {
host = data.aws_eks_cluster.cluster.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.cluster.certificate_authority.0.data)
token = data.aws_eks_cluster_auth.cluster.token
load_config_file = false
version = "1.10.0"
}
locals {
vpc_name = "dev-vpc"
vpc_cidr = "10.42.0.0/16"
private_subnets = ["10.42.1.0/24", "10.42.2.0/24"]
public_subnets = ["10.42.11.0/24", "10.42.12.0/24"]
cluster_name = "dev-cluster"
cluster_version = "1.14"
worker_group_name = "worker-group-1"
instance_type = "t2.medium"
asg_desired_capacity = 1
}
data "aws_eks_cluster" "cluster" {
name = module.eks.cluster_id
}
data "aws_eks_cluster_auth" "cluster" {
name = module.eks.cluster_id
}
data "aws_availability_zones" "available" {
}
module "vpc" {
source = "git::https://github.com/terraform-aws-modules/terraform-aws-vpc?ref=master"
name = local.vpc_name
cidr = local.vpc_cidr
azs = data.aws_availability_zones.available.names
private_subnets = local.private_subnets
public_subnets = local.public_subnets
enable_nat_gateway = true
single_nat_gateway = true
enable_dns_hostnames = true
tags = {
"kubernetes.io/cluster/${local.cluster_name}" = "shared"
}
public_subnet_tags = {
"kubernetes.io/cluster/${local.cluster_name}" = "shared"
"kubernetes.io/role/elb" = "1"
}
private_subnet_tags = {
"kubernetes.io/cluster/${local.cluster_name}" = "shared"
"kubernetes.io/role/internal-elb" = "1"
}
}
module "eks" {
source = "git::https://github.com/terraform-aws-modules/terraform-aws-eks?ref=master"
cluster_name = local.cluster_name
cluster_version = local.cluster_version
vpc_id = module.vpc.vpc_id
subnets = module.vpc.private_subnets
write_kubeconfig = false
worker_groups = [
{
name = local.worker_group_name
instance_type = local.instance_type
asg_desired_capacity = local.asg_desired_capacity
}
]
map_accounts = var.map_accounts
map_roles = var.map_roles
map_users = var.map_users
}
我们再仔细看一下 main.tf 中的“terraform”块:
这里需要指出,我们将遵守不低于 Terraform 0.12 的语法(与早期版本相比有了很大变化),同时,Terraform 不应该将其状态存储在本地,而是远程存储在 S3 存储桶中。
不同的人可以从不同的地方更新 terraform 代码确实很方便,这意味着我们需要能够锁定用户的状态,因此我们使用 dynamodb 表添加了一个锁。 有关锁定的更多信息,请参见状态锁定页面。
由于存储桶的名称在整个 AWS 中应该是唯一的,因此你不能再使用名称“eks-github-actions-terraform”。 请想一个你自己的名称,并确保它没有被占用(应该收到 NoSuchBucket 错误):
想好一个名称,创建存储桶(我们这里使用 IAM 用户“terraform”。 它拥有管理员权限,因此可以创建存储桶),并为其启用版本管理(这在配置出错时能让你省心):
对于 DynamoDB,不需要唯一性,但你需要先创建一个表:

注意,如果 Terraform 操作失败,你可能需要从 AWS 控制台手动删除锁。 但这样做时要小心。
对于 main.tf 中的 eks/vpc 模块,引用 GitHub 上提供的模块很简单:
现在看一下另外两个 Terraform 文件(variables.tf 和 outputs.tf)。 第一个文件保存了 Terraform 变量:
variable "map_accounts" {
description = "Additional AWS account numbers to add to the aws-auth configmap. See examples/basic/variables.tf for example format."
type = list(string)
default = []
}
variable "map_roles" {
description = "Additional IAM roles to add to the aws-auth configmap."
type = list(object({
rolearn = string
username = string
groups = list(string)
}))
default = []
}
variable "map_users" {
description = "Additional IAM users to add to the aws-auth configmap."
type = list(object({
userarn = string
username = string
groups = list(string)
}))
default = [
{
userarn = "arn:aws:iam::01234567890:user/my-user"
username = "my-user"
groups = ["system:masters"]
}
]
}
这里最重要的部分是将 IAM 用户“my-user”添加到 map_users 变量中,但你应该使用自己的帐户 ID 替换 01234567890。
这有什么用? 当通过本地 kubectl 客户端与 EKS 通信时,它会向 Kubernetes API 服务器发送请求,每个请求都要经过身份验证和授权过程,这样 Kubernetes 就可以知道谁发送了请求,以及它们可以做什么。 因此 Kubernetes 的 EKS 版本会要求 AWS IAM 帮助进行用户身份验证。 如果发送请求的用户列在 AWS IAM 中(这里我们指向其 ARN),请求将进入授权阶段,该阶段将由 EKS 自己处理,但要依据我们的设置。 这里要指出的是,IAM 用户“my-user”非常酷(组“system: masters”)。
最后,output.tf 文件描述了 Terraform 在完成工作后应该打印的内容:
output "cluster_security_group_id" {
description = "Security group ids attached to the cluster control plane."
value = module.eks.cluster_security_group_id
}
output "config_map_aws_auth" {
description = "A kubernetes configuration to authenticate to this EKS cluster."
value = module.eks.config_map_aws_auth
}
Terraform 部分的描述完成。 我们很快就会回来,看看如何启动这些文件。
Kubernetes 清单
到目前为止,我们已经解决了在哪里启动应用程序的问题。 现在我们来看看要运行什么。
回想一下 /k8s/ 目录中的 docker-compose.yml(我们重命名了服务,添加了几个不久就会被 kompose 用到的标签)
运行 kompose,然后添加下面突出显示的内容。 删除注释(使内容更容易理解):
我们使用 Recreate 更新策略,这意味着先删除 pod,然后重新创建。 这对于演示目的是允许的,让我们可以使用更少的资源。
我们还添加了 postStart 挂钩,该挂钩在 pod 启动后立即触发。 我们等待至 IRIS 启动,然后从默认的 zpm-repository 安装 samples-bi 包。
现在我们添加 Kubernetes 服务(同样没有注释):
是的,我们将在“默认”命名空间中部署,该命名空间适合演示。
好了,现在我们知道了运行_位置_和_内容_。 还剩下_方式_需要了解。
GitHub Actions 工作流程
我们不需要每件事都从头开始做,而是创建一个工作流程,类似于使用 GitHub Actions 在 GKE 上部署 InterSystems IRIS 解决方案中所述的工作流程。 这次,我们不必担心构建容器。 GKE 特定的部分已替换为特定于 EKS。 粗体部分与接收提交消息和在条件步骤中使用它有关:
# Environment variables.
# ${{ secrets }} are taken from GitHub -> Settings -> Secrets
# ${{ github.sha }} is the commit hash
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_REGION: ${{ secrets.AWS_REGION }}
CLUSTER_NAME: dev-cluster
DEPLOYMENT_NAME: samples-bi
jobs:
eks-provisioner:
# Inspired by:
## https://www.terraform.io/docs/github-actions/getting-started.html
## https://github.com/hashicorp/terraform-github-actions
name: Provision EKS cluster
runs-on: ubuntu-18.04
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Get commit message
run: |
echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message
run: echo $commit_msg
- name: Terraform init
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'init'
tf_actions_working_dir: 'terraform'
- name: Terraform validate
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'validate'
tf_actions_working_dir: 'terraform'
- name: Terraform plan
if: "!contains(env.commit_msg, '[destroy eks]')"
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'plan'
tf_actions_working_dir: 'terraform'
- name: Terraform plan for destroy
if: "contains(env.commit_msg, '[destroy eks]')"
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'plan'
args: '-destroy -out=./destroy-plan'
tf_actions_working_dir: 'terraform'
- name: Terraform apply
if: "!contains(env.commit_msg, '[destroy eks]')"
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'apply'
tf_actions_working_dir: 'terraform'
- name: Terraform apply for destroy
if: "contains(env.commit_msg, '[destroy eks]')"
uses: hashicorp/terraform-github-actions@master
with:
tf_actions_version: 0.12.20
tf_actions_subcommand: 'apply'
args: './destroy-plan'
tf_actions_working_dir: 'terraform'
kubernetes-deploy:
name: Deploy Kubernetes manifests to EKS
needs:
- eks-provisioner
runs-on: ubuntu-18.04
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Get commit message
run: |
echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message
run: echo $commit_msg
- name: Configure AWS Credentials
if: "!contains(env.commit_msg, '[destroy eks]')"
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Apply Kubernetes manifests
if: "!contains(env.commit_msg, '[destroy eks]')"
working-directory: ./k8s/
run: |
aws eks update-kubeconfig --name ${CLUSTER_NAME}
kubectl apply -f samples-bi-service.yaml
kubectl apply -f samples-bi-deployment.yaml
kubectl rollout status deployment/${DEPLOYMENT_NAME}
当然,我们需要设置“terraform”用户的凭据(从 ~/.aws/credentials 文件中获取),让 Github 使用它的机密:

注意工作流程的突出显示部分。 我们可以通过推送包含短语“[destroy eks]”的提交消息来销毁 EKS 集群。 请注意,我们不会使用这样的提交消息来运行“kubernetes apply”。
运行管道,但首先要创建一个 .gitignore 文件:
在 GitHub 仓库页面的“Actions”选项卡上监视部署过程。 请等待成功完成。
第一次运行工作流程时,“Terraform apply”步骤需要 15 分钟左右,大约与创建集群的时间一样长。 下次启动时(如果未删除集群),工作流程会快很多。 你可以将此签出:
当然,最好检查一下我们做了什么。 这次可以在你的笔记本电脑上使用 IAM“my-user”的凭据:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-42-1-125.eu-west-1.compute.internal Ready
$ kubectl get po
NAME READY STATUS RESTARTS AGE
samples-bi-756dddffdb-zd9nw 1/1 Running 0 6m16s
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 172.20.0.1
samples-bi LoadBalancer 172.20.33.235 a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com 52773:31047/TCP 6m33s
访问 _http://a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER _(将链接替换为你的外部 IP),然后输入“_system”、“SYS”并更改默认密码。 您应该看到一系列 BI 仪表板:

点击每个仪表板的箭头可以深入了解:

记住,如果重启 samples-bi pod,所有更改都将丢失。 这是有意的行为,因为这是演示。 如果你需要保留更改,我在 github-gke-zpm-registry/k8s/statefulset.tpl 仓库中创建了一个示例。
完成后,删除你创建的所有内容:
结论
在本文中,我们将 eksctl 实用程序替换成 Terraform 来创建 EKS 集群。 这是向“编纂”您的所有 AWS 基础架构迈出的一步。
我们展示了如何使用 Github Actions 和 Terraform 通过 git push 轻松部署演示应用程序。
我们还向工具箱中添加了 kompose 和 pod 的 postStart 挂钩。
这次我们没有展示 TLS 启用。 我们将在不久的将来完成这项任务。