简介
什么是Query
Query是一种查询方法,用于查找满足条件的数据,将结果以数据集的形式展现出来。
Query类别
SQL Query,使用类 %SQLQuery和 SQL SELECT 语句。- 自定义
Query,使用类 %Query 和自定义逻辑生成查询数据。
说明:在讲通用Query解决方案之前,我们先了解一下Query的基础和基础使用,有助于理解实现原理。如果读者了解Query基本使用,可跳过此章节,直接阅读“现状”。
Query基本使用
SQL Query基本使用
Query QueryPersonByName(name As %String = "") As %SQLQuery(COMPILEMODE = "IMMEDIATE", CONTAINID = 1, ROWSPEC = "id:%Integer:ID,MT_Name:%String:name,age:%String,no:%String", SELECTMODE = "RUNTIME") [ SqlName = QueryPersonByName, SqlProc ]
{
SELECT top 10 ID, MT_Age, MT_Name, MT_No
FROM M_T.Person
WHERE (MT_Name %STARTSWITH :name)
ORDER BY id
}
说明:
Query - 声明Query方法关键字。
QueryPersonByName - Query方法的名称。
name As %String = "" - Query方法的参数。
%SQLQuery - Query类型为%SQLQuery。
%SQLQuery为%Query的子类,使用Query的简单的形式,可在方法体内直接编写Select SQL语句。
COMPILEMODE - 为%SQLQuery的参数,表示编译方式。
IMMEDIATE - 立即编译,当检测当前SQL语句是否正确。DYNAMIC - 动态编译 ,在运行时在编译SQL语句。
CONTAINID - 置为返回 ID 的列的编号。
SELECTMODE - 表示显示方式。
RUNTIME - 无ODBC - 以ODBC方式显示数据。DISPLAY - 以显示方式显示数据。LOGICAL - 以逻辑方式显示数据。
ROWSPEC - 提供数据列名称、数据类型、描述。用引号和逗号分隔的变量名和数据类型列表。格式如下:
SqlProc - 表示该方法可作为存储过程调用。
SqlName - 调用的存储过程名称。
- 无声明调用方式 -
call M.Query_QueryPersonByName() - 声明调用方式 -
call M.QueryPersonByName()

- 运行
Query方法 - d ##class(%ResultSet).RunQuery(className, queryName, arg...)
USER>d ##class(%ResultSet).RunQuery("M.Query", "QueryPersonByName")
ID:age:name:no:
1:21:yaoxin:314629:
2:29:yx:685381:
3:18:Umansky,Josephine Q.:419268:
4:27:Pape,Ted F.:241661:
5:25:Russell,Howard T.:873214:
6:30:Xenia,Ashley U.:420471:
7:24:Rotterman,Martin O.:578867:
8:18:Drabek,Hannah X.:662167:
9:19:Eno,Mark U.:913628:
11:18:Tsatsulin,Dan Z.:920134:
自定义Query基本使用
在使用自定义Query时,一般都遵循固定的模版。在同一个类中定义以下类方法:
QueryName - 在Query方法类型指定 %Query。QueryNameExecute — 此方法主要编写获取数据的业务逻辑,得到数据集。QueryNameFetch — 此方法遍历数据集。QueryNameClose — 此方法删除临时数据或对象。
说明:下面示例展示常用“套路”的自定义Query模版,此模版仅仅是常用的一种,并非是固定写法。
定义QueryName
Query QueryPersonByAge(pAge As %String = "", count As %Integer = "10") As %Query(ROWSPEC = "id:%Integer:ID,MT_Name:%String:name,age:%String,no:%String")
{
}
定义名为QueryPersonByAge的Query类型指定为%Query。并将查询定义的主体留空。
定义QueryNameExecute
ClassMethod QueryPersonByAgeExecute(ByRef qHandle As %Binary, pAge As %String = "", count As %Integer = "10") As %Status
{
s pid = $i(^CacheTemp) // 注释1
s qHandle = $lb(0, pid, 0) // 注释2
s index = 1 // 注释3
/* 业务逻辑代码 注释4 */
s id = ""
for {
s id = $o(^M.T.PersonD(id))
q:(id = "")
q:(id > count)
s data = ^M.T.PersonD(id)
s i = 1
s name = $lg(data, $i(i))
s age = $lg(data, $i(i))
continue:(age < pAge)
s no = $lg(data, $i(i))
d output
}
/* 业务逻辑代码 */
q $$$OK
output
s ^CacheTemp(pid, index) = $lb(id, age, name, no) // 注释6
s index = index + 1 // 注释7
}
QueryNameExecute() 方法提供所有需要的业务逻辑。方法的名称必须是 QueryNameExecute() ,其中 QueryName是定义Query的名称。
其中:
qHandle - 用于与实现此查询的其他方法进行通信。qHandle 可以为任何类型。默认为%Binary。pAge As %String = "", count As %Integer = "10"为Query传入参数,可作为业务逻辑的条件使用。- 注释
1处代码,s pid = $i(^CacheTemp) - 获取pid。 - 注释
2处代码,s qHandle = $lb(0, pid, 0) - 数组内第一个元素0表示循环的开始,第二个元素pid用于获取^CacheTemp数据,第三个元素0用于遍历^CacheTemp起始节点。 - 业务逻辑代码 - 为获取数据集的主要实现逻辑。
- 注释
3处代码与注释7处代码,为^CacheTemp增加索引节点。 - 注释
6处代码,s ^CacheTemp(pid, index) = $lb(id, name, age, no) - 为^CacheTemp赋值为后续遍历使用。
- 这里数据格式为
%Library.List形式,这样Fetch方法就不用转类型了,否则Fetch方法还需要将数据转为内部列表格式。
定义QueryNameFetch
ClassMethod QueryPersonByAgeFetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ PlaceAfter = QueryPersonByAgeExecute ]
{
s end = $li(qHandle, 1) // 注释1
s pid = $li(qHandle, 2)
s index = $li(qHandle, 3)
s index = $o(^CacheTemp(pid, index)) // 注释2
if index = "" { // 注释3
s end = 1
s row = ""
} else {
s row = ^CacheTemp(pid, index)
}
s qHandle = $lb(end, pid, index) // 注释4
q $$$OK
}
QueryNameFetch() 方法必须以 %Library.List 格式返回单行数据。方法的名称必须是 QueryNameFetch,其中 QueryName是定义Query的名称。
其中:
qHandle - 用于与实现此查询的其他方法进行通信。它的值应该是Execute定义的值。row - 表示要返回的一行数据的值类型为 %Library.List,如果没有返回数据则为空字符串。end - 当到达最后一行数据时,end必须为 1。如果不指定为1,则会无限循环。PlaceAfter - PlaceAfter方法关键字控制此方法在生成代码中顺序。这里表示在方法QueryPersonByAgeExecute生成之后在生成QueryPersonByAgeFetch方法。- 注释
1处代码, 1~3 行,解析qHandle数组的值获取end、pid、index。 - 注释
2处代码,s index = $o(^CacheTemp(pid, index)) 根据解析到的pid,index开始遍历。 - 注释
3处代码,将遍历的^CacheTemp(pid, index)每行属于赋值给row,如果index为空,则一定要将end赋值为1。 - 注释
4处代码,s qHandle = $lb(end, pid, index)将取到的end、index重新复制给qHandle为取下一行数据做准备。
注:Fetch方法为多次执行,有多少行数据就遍历多少遍。Execute、Close方法为一次执行。
定义QueryNameClose
ClassMethod QueryPersonByAgeClose(ByRef qHandle As %Binary) As %Status [ PlaceAfter = QueryPersonByAgeExecute ]
{
s pid = $li(qHandle, 2) // 注释1
k ^CacheTemp(pid) // 注释2
q $$$OK
}
QueryNameClose() 方法在数据检索完成后删除清理临时数据或对象等结束收尾工作。方法的名称必须是 QueryNameClose() ,其中 QueryName是定义Query的名称。
qHandle - 用于与实现此查询的其他方法进行通信。- 注释
1处代码,获取qHandle 保存的pid。 - 注释
2处代码,清除临时生成的^CacheTemp。
调用自定义Query
USER> d ##class(%ResultSet).RunQuery("M.Query", "QueryPersonByAge","20")
ID:name:age:no:
1:yaoxin:21:314629:
2:yx:29:685381:
4:Pape,Ted F.:27:241661:
5:Russell,Howard T.:25:873214:
6:Xenia,Ashley U.:30:420471:
7:Rotterman,Martin O.:24:578867:
- 这里查询是年龄大于
20岁并且id小于10的所有人员信息。
现状
上面2个Query的基本使用示例,可能是大家最常用的两种方式。
但是经常写查询或者写报表的同学可能会面临如下几个问题:
- 每次写
Query都需要定义列头ROWSPEC很麻烦,是否可以自己指定列头ROWSPEC? - 现在很多方法返回的值是
JSON,如何将JSON方法快速转成Query? - 是否可以写一个通用
Query,只需要写Execute主要逻辑即可? - 是否可以优化现在的模版,例如
^CacheTemp替换成^||CacheTemp?
以上的问题,都是可以解决的,请继续阅读下面文章部分。
方案
如果想实现通用Query还得需要知道一个回调方法QueryNameGetInfo。
ClassMethod Json2QueryGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, extinfo As %List) As %Status
{
q $$$OK
}
其中:
colinfo - 此参数最关键用于定义ROWSPEC列头部分。为在 ROWSPEC 中声明的每一列包含一个列表元素。形式为 name:exttype:caption 。
name - 为列头名称。exttype - 为数据类型。caption - 为描述说明。
colinfo 类型必须是%Library.List,定义的列头的类型也是%Library.List。
例如:
ClassMethod QueryPersonByAgeGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef %qHandle As %Binary, extoption As %Integer = 0, extinfo As %List) As %Status
{
s colinfo = $lb($lb("id", "%Integer", "ID"), $lb("age", "%String", ""), $lb("MT_Name", "%String", "name"), $lb("no", "%String", ""))
s parminfo = ""
s idinfo = ""
q $$$OK
}
说明:Query执行顺序 Execute -> GetInfo -> Fetch(n) -> Close。
下面分别描述以下几种解决方案:
- 通过
Json数据或方法动态生成Query - 通过
Select Sql语句动态生成Query - 通过
Query动态生成Query - 支持传统的Query并通过参数形式生成Query列
- 定义通用
Query,只需要实现Exceute方法
通过Json数据或方法动态生成Query
定义Json方法
Json方法可任意定义,此示例仅为了测试使用。如下方法:查询当前电脑盘符以Json结果输出。
/// desc:查询盘符
ClassMethod QueryDrives(fullyQualified = 1, type = "D")
{
s array = []
s rs = ##class(%ResultSet).%New()
s rs.ClassName = "%File"
s rs.QueryName = "DriveList"
d rs.Execute(fullyQualified)
while (rs.Next()) {
s drive = rs.Get("Drive")
s drive = $zcvt(drive, "U")
s obj = {}
s obj.type = "D"
continue:(type '= "D")
s obj.drive = drive
d array.%Push(obj)
}
q array
}
运行:
USER> w ##class(M.Query).QueryDrives().%ToJSON()
[{"type":"D","drive":"C:\\"},{"type":"D","drive":"D:\\"},{"type":"D","drive":"E:\\"},{"type":"D","drive":"F:\\"},{"type":"D","drive":"G:\\"}]
定义QueryName
Query Json2Query(className As %String, methodName As %String, arg...) As %Query
{
}
其中:
className - 类名。methodName - 需要执行的Json方法名称。arg... - 需要执行的方法参数。
定义QueryNameExecute
ClassMethod Json2QueryExecute(ByRef qHandle As %Binary, className As %String, methodName As %String, arg...) As %Status
{
s array = $classmethod(className, methodName, arg...) // 注释1
if ('$isobject(array)) { // 注释2
s array = [].%FromJSON(array)
}
q:('array.%IsA("%Library.DynamicArray")) $$$ERROR($$$GeneralError, "不是数组对象") // 注释3
q:(array.%Size() = 0) $$$ERROR($$$GeneralError, "没有数据") // 注释4
s qHandle = array // 注释5
q $$$OK
}
- 注释
1代码,利用反射机制调用目标方法并获取返回值。 - 注释
2代码,判断如果返回的字符串则转成Json对象。 - 注释
3代码,判断该对象不是%Library.DynamicArray抛出错误信息。 - 注释
4代码,Json数组长度为0抛出错误信息。 - 注释
5代码,获取数组对象。
定义QueryNameGetInfo
ClassMethod Json2QueryGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, extinfo As %List) As %Status
{
s colinfo = $lb() // 注释1
s count = 1
s obj = qHandle.%GetIterator()
if obj.%GetNext(.key, .value) {
s obj = value.%GetIterator()
while obj.%GetNext(.objKey, .objValue) { // 注释2
s $li(colinfo, count) = $lb(objKey)
s count = $i(count)
}
}
s parminfo = "" // 注释3
s idinfo = "" // 注释4
s qHandle = qHandle.%GetIterator() // 注释5
q $$$OK
}
- 注释
1代码,初始化colinfo数组,将obj赋值qHandle.%GetIterator()迭代器对象。 - 注释
2代码,遍历Json对象获取Key,并通过$li给colinfo赋值。 - 注释
3代码,初始化parminfo,否则报错。 - 注释
4代码,初始化idinfo,否则报错。 - 注释
5代码,获取的迭代器对象
定义QueryNameFetch
ClassMethod Json2QueryFetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ PlaceAfter = Json2QueryExecute ]
{
s iter = qHandle
q:($g(iter) = "") $$$OK
if iter.%GetNext(.key, .value) { // 注释1
s row = ""
s obj = value.%GetIterator()
while obj.%GetNext(.objKey, .objValue) { // 注释2
if ( $g(row) = "" ) {
s row = $lb(objValue)
} else {
s row = row _ $lb(objValue)
}
}
s end = 0
} else {
s row = ""
s end = 1 // 注释3
}
q $$$OK
}
- 注释
1代码,获取当前迭代器Json数据行。 - 注释
2代码,遍历当前Json对象并把value与row进行$lb串联。 - 注释
3代码,如果没有数据设置end为1表示遍历结束。
定义QueryNameClose
ClassMethod Json2QueryClose(ByRef qHandle As %Binary) As %Status [ PlaceAfter = Json2QueryFetch ]
{
s qHandle = "" // 注释1
q $$$OK
}
注:其实M有相关回收机制,实际上Close方法不声明也可以。
调用Json2Query方法
USER>d ##class(%ResultSet).RunQuery("M.Query","Json2Query","M.Query","QueryDrives","0","D")
type:drive:
D:D::
D:E::
D:F::
D:G::
USER>d ##class(%ResultSet).RunQuery("M.Query","Json2Query","M.Query","QueryDrives","1","D")
type:drive:
D:D:\:
D:E:\:
D:F:\:
D:G:\:
通过Select Sql语句动态生成Query
定义QueryName
Query Sql2Query(sql As %String, mode As %String = 1) As %Query
{
}
sql - 表述需要写入SQL语句的变量。mode - 显示数据格式类型。
- 0 - 逻辑格式
- 1 -
OBDC 格式 - 2 - 显示格式
定义QueryNameExecute
ClassMethod Sql2QueryExecute(ByRef qHandle As %Binary, sql As %String, mode As %String = 1) As %Status
{
s sqlStatement = ##class(%SQL.Statement).%New()
s sqlStatement.%SelectMode = mode // 注释1
s sqlStatus = sqlStatement.%Prepare(.sql) // 注释2
q:$$$ISERR(sqlStatus) sqlStatus
s sqlResult = sqlStatement.%Execute()
s stateType = sqlStatement.%Metadata.statementType
q:('stateType = 1 ) $$$ERROR($$$GeneralError, "不是select语句") // 注释3
s qHandle = {}
s qHandle.sqlResult = sqlResult // 注释4
s qHandle.sqlStatement = sqlStatement
q $$$OK
}
- 注释
1代码,设置SQL的数据显示格式。 - 注释
2代码,传入SQL语句得到sqlStatement与sqlResult对象。 - 注释
3代码,传入的SQL非Select语句,抛出错误信息。 - 注释
4代码,将qHandle传入两个对象分别是sqlResult、sqlStatement。
sqlResult用于遍历数据使用。sqlStatement用于得到数据列头信息。
定义QueryNameGetInfo
ClassMethod Sql2QueryGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, extinfo As %List) As %Status
{
s colinfo = $lb()
s sqlStatement = qHandle.sqlStatement // 注释1
s count = 1
for i = 1 : 1 : sqlStatement.%Metadata.columnCount {
s data = sqlStatement.%Metadata.columns.GetAt(i).label
s $li(colinfo, count) = $lb(data) // 注释2
s count = $i(count)
}
s parminfo = ""
s idinfo = ""
q $$$OK
}
- 注释
1代码,通过qHandle得到sqlStatement对象。 - 注释
2代码,给colinfo列表进行循环赋值列头信息,
定义QueryNameFetch
ClassMethod Sql2QueryFetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ PlaceAfter = Sql2QueryExecute ]
{
s sqlStatement = qHandle.sqlStatement // 注释1
s sqlResult = qHandle.sqlResult
s colCount = sqlResult.%ResultColumnCount // 注释2
if (sqlResult.%Next()) {
for i = 1 : 1 : colCount{
s val = sqlResult.%GetData(i)
if ( $g(row) = "" ) { // 注释3
s row = $lb(val)
} else {
s row = row _ $lb(val)
}
}
s end = 0
} else {
s row = ""
s end = 1
}
s qHandle.sqlResult = sqlResult // 注释4
q $$$OK
}
- 注释
1代码,通过qHandle得到sqlStatement、sqlResult对象。 - 注释
2代码,得到列数,相当于得到一行数据有多少项。 - 注释
3代码,遍历数据给row赋值。 - 注释
4代码,将qHandle.sqlResult对象,赋值给循环当前对象。
定义QueryNameClose
此处省略。
注:其实M有相关回收机制,实际上Close方法不声明也可以。
调用Sql2Query方法
USER>d ##class(%ResultSet).RunQuery("M.Query","Sql2Query","select * from M_T.Person", 1)
id:MT_Age:MT_Name:MT_No:
1:21:yaoxin:314629:
2:29:yx:685381:
3:18:Umansky,Josephine Q.:419268:
4:27:Pape,Ted F.:241661:
5:25:Russell,Howard T.:873214:
6:30:Xenia,Ashley U.:420471:
7:24:Rotterman,Martin O.:578867:
8:18:Drabek,Hannah X.:662167:
9:19:Eno,Mark U.:913628:
...
100:24:Nathanson,Jocelyn A.:147578:
USER>d ##class(%ResultSet).RunQuery("M.Query","Sql2Query","select ID,MT_Name from M_T.Person")
id:MT_Name:
1:yaoxin:
2:yx:
3:Umansky,Josephine Q.:
4:Pape,Ted F.:
5:Russell,Howard T.:
6:Xenia,Ashley U.:
7:Rotterman,Martin O.:
...
100:Nathanson,Jocelyn A.:
USER>d ##class(%ResultSet).RunQuery("M.Query","Sql2Query","select top 10 ID as id from M_T.Person")
id:
1:
2:
3:
4:
5:
6:
7:
8:
9:
11:
通过Query生成动态Query
定义QueryName
Query Query2Query(className As %String, queryName As %String, arg...) As %Query
{
}
className - 类名。queryName - 需要执行的Query方法名称。arg... - 需要执行的Query方法参数。
定义QueryNameExecute
ClassMethod Query2QueryExecute(ByRef qHandle As %Binary, className As %String, queryName As %String, arg...) As %Status
{
s sqlStatement = ##class(%SQL.Statement).%New()
s sqlStatus = sqlStatement.%PrepareClassQuery(className, queryName)
q:$$$ISERR(sqlStatus) sqlStatus
s sqlResult = sqlStatement.%Execute()
s qHandle = {}
s qHandle.sqlResult = sqlResult
s qHandle.sqlStatement = sqlStatement
q $$$OK
}
定义QueryNameGetInfo
ClassMethod Query2QueryGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, extinfo As %List) As %Status
{
s colinfo = $lb()
s sqlStatement = qHandle.sqlStatement
s count = 1
s column = ""
for {
s column = $o(sqlStatement.%Metadata.columnIndex(column))
q:(column = "")
s data = sqlStatement.%Metadata.columnIndex(column)
s $li(colinfo, count) = $lb($lg(data, 2))
s count = $i(count)
}
s parminfo = ""
s idinfo = ""
q $$$OK
}
定义QueryNameFetch
ClassMethod Query2QueryFetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ PlaceAfter = Query2QueryExecute ]
{
s sqlStatement = qHandle.sqlStatement
s sqlResult = qHandle.sqlResult
s colCount = sqlResult.%ResultColumnCount
if (sqlResult.%Next()) {
for i = 1 : 1 : colCount{
s val = sqlResult.%GetData(i)
if ( $g(row) = "" ) {
s row = $lb(val)
} else {
s row = row _ $lb(val)
}
}
s end = 0
} else {
s row = ""
s end = 1
}
s qHandle.sqlResult = sqlResult
q $$$OK
}
调用Query2Query
USER>d ##class(%ResultSet).RunQuery("M.Query","Query2Query","M.Query","QueryPersonByName")
age:id:MT_Name:no:
1:21:yaoxin:314629:
2:29:yx:685381:
3:18:Umansky,Josephine Q.:419268:
4:27:Pape,Ted F.:241661:
5:25:Russell,Howard T.:873214:
6:30:Xenia,Ashley U.:420471:
7:24:Rotterman,Martin O.:578867:
8:18:Drabek,Hannah X.:662167:
9:19:Eno,Mark U.:913628:
11:18:Tsatsulin,Dan Z.:920134:
支持传统的Query并通过参数形式生成Query列
- 支持传统的
Query形式。 - 支持通过参数形式定义列,不需要指定
ROWSPEC参数。 - 优化将
^CacheTemp为^||CacheTemp。
定义M.CommonQuery
Class M.CommonQuery Extends %Query
{
ClassMethod Close(ByRef qHandle As %Binary) As %Status [ CodeMode = generator, PlaceAfter = Execute, ProcedureBlock = 1, ServerOnly = 1 ]
{
s %code($i(%code))= (" s pid = $li(qHandle, 2)")
s %code($i(%code))= (" k ^||GlobalTemp(pid)")
s %code($i(%code))= (" q $$$OK")
q $$$OK
}
ClassMethod Fetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ CodeMode = generator, PlaceAfter = Execute, ProcedureBlock = 1, ServerOnly = 1 ]
{
s %code($i(%code))= (" s end = $li(qHandle, 1)")
s %code($i(%code))= (" s pid = $li(qHandle, 2)")
s %code($i(%code))= (" s ind = $li(qHandle, 3)")
s %code($i(%code))= (" s ind = $o(^||GlobalTemp(pid, ind))")
s %code($i(%code))= (" if (ind = """") { ")
s %code($i(%code))= (" s end = 1")
s %code($i(%code))= (" s row = """"")
s %code($i(%code))= (" } else { ")
s %code($i(%code))= (" s row = ^||GlobalTemp(pid, ind)")
s %code($i(%code))= (" }")
s %code($i(%code))= (" s qHandle = $lb(end, pid, ind)")
s %code($i(%code))= (" q $$$OK")
q $$$OK
}
ClassMethod GetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, ByRef extinfo As %List) As %Status [ CodeMode = generator, ServerOnly = 1 ]
{
s %code($i(%code))= (" s colinfo = $lb()")
s %code($i(%code))= (" s column = $lg(qHandle, 4)")
s %code($i(%code))= (" if ($lv(column)) {")
s %code($i(%code))= (" for i = 1 : 1 : $ll(column) {")
s %code($i(%code))= (" s $li(colinfo, i) = $lb(""Column"" _ i )")
s %code($i(%code))= (" } ")
s %code($i(%code))= (" } else {")
s %code($i(%code))= (" s len = $l(column, "","")")
s %code($i(%code))= (" for i = 1 : 1 : len {")
s %code($i(%code))= (" s $li(colinfo, i) = $lb($p(column, "","", i))")
s %code($i(%code))= (" }")
s %code($i(%code))= (" }")
s %code($i(%code))= (" s parminfo = """"")
s %code($i(%code))= (" s idinfo = """"")
s %code($i(%code))= (" q $$$OK")
q $$$OK
}
}
定义QueryName
Query CustomColumnQuery(column As %String = "") As M.CommonQuery
{
}
column - 表示要自定义参数列的变量。M.CommonQuery - 自定义Query类型,不需要写GetInfo、Fetch、Close方法。
定义QueryNameExecute
QueryNameExecute 支持三种定义列头方式:
- 通过
column参数传入列头,实现如下:
ClassMethod CustomColumnQueryExecute(ByRef qHandle As %Binary, column As %List) As %Status
{
s pid = $i(^||GlobalTemp)
s qHandle = $lb(0, pid, 0)
s $li(qHandle, 4) = column // 方式1此位置必填
s ind = 1
s id = ""
for {
s id = $o(^M.T.PersonD(id))
q:(id = "")
s data = ^M.T.PersonD(id)
s i = 1
s name = $lg(data, $i(i))
s age = $lg(data, $i(i))
s no = $lg(data, $i(i))
d output
}
q $$$OK
output
s data = $lb(id, name)
s ^||GlobalTemp(pid, ind)=data
s ind = ind + 1
}
USER> d ##class(%ResultSet).RunQuery("M.Query","CustomColumnQuery","ID,Name")
ID:Name:
1:yaoxin:
2:yx:
3:Umansky,Josephine Q.:
4:Pape,Ted F.:
5:Russell,Howard T.:
- 不传入
column参数,自动根据列表数据数量生成列头,实现如下:
ClassMethod CustomColumnQueryExecute(ByRef qHandle As %Binary, column As %String = "") As %Status
{
s pid = $i(^||GlobalTemp)
s qHandle = $lb(0, pid, 0)
s ind = 1
s id = ""
for {
s id = $o(^M.T.PersonD(id))
q:(id = "")
s data = ^M.T.PersonD(id)
s i = 1
s name = $lg(data, $i(i))
s age = $lg(data, $i(i))
s no = $lg(data, $i(i))
s data = $lb(id, name, no)
q:(id > 5)
d output
}
s $li(qHandle, 4) = data // 方式2此位置必填
q $$$OK
output
s ^||GlobalTemp(pid, ind)=data
s ind = ind + 1
}
USER>d ##class(%ResultSet).RunQuery("M.Query","CustomColumnQuery")
Column1:Column2:Column3:
1:yaoxin:314629:
2:yx:685381:
3:Umansky,Josephine Q.:419268:
4:Pape,Ted F.:241661:
5:Russell,Howard T.:873214:
- 不传入
column参数,通过Execute方法自定义列头信息,实现如下:
ClassMethod CustomColumnQueryExecute0(ByRef qHandle As %Binary, column As %String = "") As %Status
{
s pid = $i(^||GlobalTemp)
s qHandle = $lb(0, pid, 0)
s ind = 1
s id = ""
for {
s id = $o(^M.T.PersonD(id))
q:(id = "")
s data = ^M.T.PersonD(id)
s i = 1
s name = $lg(data, $i(i))
s age = $lg(data, $i(i))
s no = $lg(data, $i(i))
s data = $lb(id, name, no)
q:(id > 5)
d output
}
s $li(qHandle, 4) = "id,name,age" // 方式3此位置必填
q $$$OK
output
s ^||GlobalTemp(pid, ind)=data
s ind = ind + 1
}
USER>d ##class(%ResultSet).RunQuery("M.Query","CustomColumnQuery")
id:name:age:
1:yaoxin:314629:
2:yx:685381:
3:Umansky,Josephine Q.:419268:
4:Pape,Ted F.:241661:
5:Russell,Howard T.:873214:
定义通用Query,只需要实现Exceute方法
实现通用Query,需要通过抽象方法,子类去重写的方式去实现。所以首先定义父类。
定义M.CommonQuery
Class M.BaseQuery Extends %RegisteredObject
{
/// d ##class(%ResultSet).RunQuery("M.BaseQuery","CustomQuery","id,name")
Query CustomQuery(column As %List, arg...) As %Query
{
}
ClassMethod CustomQueryExecute(ByRef qHandle As %Binary, column As %List, arg...) As %Status
{
s qHandle = $lb(0, 0) // 注释1
s $li(qHandle, 3) = column // 注释2
d ..QueryLogic(arg...) // 注释3
q $$$OK
}
ClassMethod CustomQueryGetInfo(ByRef colinfo As %List, ByRef parminfo As %List, ByRef idinfo As %List, ByRef qHandle As %Binary, extoption As %Integer = 0, ByRef extinfo As %List) As %Status
{
s colinfo = $lb()
s column = $lg(qHandle ,3)
s len = $l(column, ",")
for i = 1 : 1 : len {
s $li(colinfo, i) = $lb($p(column, ",", i)) // 注释5
}
s parminfo = ""
s idinfo = ""
q $$$OK
}
ClassMethod CustomQueryClose(ByRef qHandle As %Binary) As %Status [ PlaceAfter = CustomQueryExecute ]
{
k %zQueryList // 注释7
q $$$OK
}
ClassMethod CustomQueryFetch(ByRef qHandle As %Binary, ByRef row As %List, ByRef end As %Integer = 0) As %Status [ PlaceAfter = CustomQueryExecute ]
{
s end = $li(qHandle,1)
s index = $li(qHandle,2)
s index = $o(%zQueryList(index))
if index = "" { // 注释6
s end = 1
s row = ""
} else {
s row = %zQueryList(index)
}
s qHandle = $lb(end, index)
Quit $$$OK
}
ClassMethod QueryLogic(arg...) [ Abstract ]
{
// 注释4
}
}
column - 表示要自定义参数列的变量。arg... - 传入的参数。- 注释
1代码,这里做了一些改变,qHandle只记录了end与index。因为这里如果是全局变量或者进程私有Global只针对当前进程有效,所以pid可省略。 - 注释
2代码,将qHandle第三个位置传入列头名称。 - 注释
3代码,调用待实现的业务逻辑方法,此方法为抽象方法,需要子类去实现。 - 注释
4代码,子类需要实现的具体业务逻辑,得到数据集。 - 注释
5代码,获取到column动态设置列头。 - 注释
6代码,遍历全局变量。 - 注释
7代码,遍历结束后,将全局变量清空。
定义子类M.PersonQuery继承M.BaseQuery实现QueryLogic方法
- 这里只需要给
%zQueryList($i(count))全局变量赋值即可。固定模版已经抽象到父类。
ClassMethod QueryLogic(arg...)
{
s pName = arg(1)
s id = ""
for {
s id = $o(^M.T.PersonD(id))
q:(id = "")
s data = ^M.T.PersonD(id)
s i = 1
s name = $lg(data, $i(i))
continue:(pName '= "")&&(name '= pName)
s age = $lg(data, $i(i))
s no = $lg(data, $i(i))
s %zQueryList($i(count)) = $lb(id, name, age)
}
}
调用CustomQuery方法
USER>d ##class(%ResultSet).RunQuery("M.PersonQuery","CustomQuery","ID,Name,Age", "yaoxin")
ID:Name:Age:
1:yaoxin:21:
注:这里是用的是全局变量作为数据传递,如果数据过大,则可能会出现内存泄漏问题。改成进程私有Global即可。由读者基于此逻辑自行实现。
注:这种方式一个类只能声明一个Query,如果想一个类声明多个Query,则考虑换成支持传统的Query方式。
通过Query生成Json
ClassMethod Query2Json(className, queryName, arg...)
{
s array = []
s rs = ##class(%ResultSet).%New()
s rs.ClassName = className
s rs.QueryName = queryName
d rs.Execute(arg...)
s array = []
#; 属性值
while (rs.Next()) {
s valStr = ""
s obj = {}
for i = 1 : 1 : rs.GetColumnCount(){
s columnName = rs.GetColumnName(i)
s val = rs.Data(columnName)
d obj.%Set(columnName, val)
}
d array.%Push(obj)
}
q array.%ToJSON()
}
USER>w ##class(Util.JsonUtils).Query2Json("%SYSTEM.License","Summary")
[{"LicenseUnitUse":"当前使用的软件许可单元 ","Local":"1","Distributed":"1"},{"Li censeUnitUse":"使用的最大软件许可单元数 ","Local":"15","Distributed":"15"},{"Lic enseUnitUse":"授权的软件许可单元 ","Local":"300","Distributed":"300"},{"LicenseU nitUse":"当前连接 ","Local":"3","Distributed":"3"},{"LicenseUnitUse":"最大连接数 ","Local":"17","Distributed":"17"}]
通过Query生成Csv
ClassMethod Query2Csv(className, queryName, filePath, arg...)
{
s file = ##class(%FileCharacterStream).%New()
s file.Filename = filePath
s array = []
s rs = ##class(%ResultSet).%New()
s rs.ClassName = className
s rs.QueryName = queryName
d rs.Execute(arg...)
#; 列名
s colStr = ""
for i = 1 : 1 : rs.GetColumnCount(){
s columnName = rs.GetColumnName(i)
s colStr = $s(colStr = "" : columnName, 1 : colStr _ "," _ columnName)
}
d file.Write(colStr)
#; 属性值
while (rs.Next()) {
s valStr = ""
for i = 1 : 1 : rs.GetColumnCount(){
s columnName = rs.GetColumnName(i)
s val = rs.Data(columnName)
s valStr = $s(valStr = "" : val, 1 : valStr _ "," _ val)
}
d file.Write($c(10) _ valStr)
}
d file.%Save()
q $$$OK
}
USER>w ##class(Util.FileUtils).Query2Csv("%SYSTEM.License","Summary","E:\m\CsvFile2.csv")
1

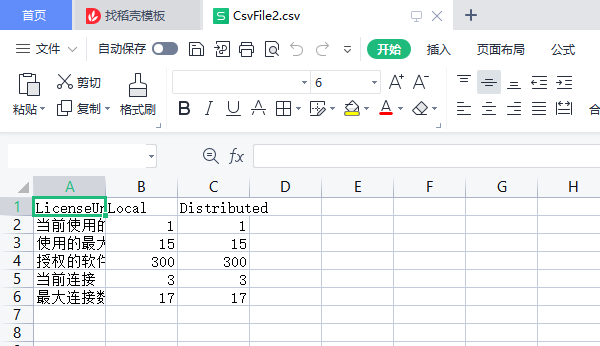
总结
- 理解
qHandle参数与GetInfo方法是实现通用Query的关键。 - 使用通用
Query可以提升开发效率。 - 使用通用
Query可以解决数据适配问题。
以上是个人对基于Query的一些理解,由于个人能力有限,欢迎大家提出意见,共同交流。
如果一个好点子,只是因为某个人先到想到就禁止后人使用,这会让整个人类社会多走很多弯路,这也是自由软件精神一直以来所表达的内容。
- 理查德·马修·斯托曼
.png)


.png)
.png)
