我们刚刚结束了第二天的专题会议,会议内容精彩纷呈!虽然大家无法同时观看多个平行会议,但是线上会议有一个优势,那就是您可以根据自己的需要回看错过的内容!
在昨天的博客文章(第一天会议亮点)中,我介绍了大部分值得关注的公告,如 InterSystems IRIS Adaptive Analytics 和FHIR加速器服务等。所以,今天我想更宽泛地讨论一些战略主题。
运营和系统管理
现在,越来越多的客户业务已经运行在云端,也有越来越多的人开始在本地部署现代部署策略。Mark Bolinsky今天主持了两场背靠背会议:CL003 云存储策略和CL004 云备份策略,为使用云端生产工作的用户带来了很多技术细节。我们新推出的系统警报和监控(SAM)模块也得到了不错的反馈。相关内容请查看DEV007 系统警报和监控和CL005 分布式部署。另一个另广大开发者兴奋的消息是,集群监控现在可以轻松实现。在此感谢所有参与并提出问题的与会者!
安全性
IRIS 中支持的四种方式:
SQL、Objects、REST 和 GraphQL

卡济米尔·马列维奇,《运动员》(1932)
>
> “你当然无法理解! 习惯了坐马车旅行的人怎么可能理解乘坐火车或者飞机旅行的人的感受和印象?”
>
> >
> 卡济米尔·马列维奇 (1916)
>
## 引言
我们已经讨论过为什么在主题领域建模使用对象类型优于使用 SQL。 当时得出的结论和总结的事实如今依然适用。 那么,我们为什么要退后到对象和类型之前的时代,讨论将对象的操作拖回到使用global的技术? 我们又为什么要鼓励面条式代码?难道是为了用它难以跟踪的错误考验开发者的技能熟练度?
目前有几种观点支持通过基于 SQL/REST/GraphQL 的 API 传输数据,而不是将其表示为类型/对象:
- 这些技术经过深入研究,相当易于部署。
- 知名度非常高,已在便捷的开源软件中广泛实现。
- 您通常别无选择,只能使用这些技术,尤其是在网络和数据库中。
- 最重要的是,API 仍然使用对象,因为它们提供了在代码中实现 API 的最适途径。
在讨论实现 API 之前,我们先来看一下底层的抽象层。 下图显示了数据在永久存储位置与处理并向应用程序用户呈现的位置之间的移动方式。
InterSystems IRIS 下使用 DataOps .png)
Gartner 对 DataOps 的定义是:“DataOps 是一种协作式的数据管理方法,侧重于改善整个组织中数据管理者和数据消费者之间数据流的沟通、整合与自动化。 DataOps 的目标是创建可预测的数据、数据模型和相关项目的交付和变更管理,从而更快地交付价值。 DataOps 采取特殊技术手段和相应治理水平自动化数据交付的设计、部署和管理,以元数据提高动态环境中数据的易用性和价值。”
2014 年 6 月 19 日,InformationWeek 特约编辑 Lenny Liebmann 发表于 IBM Big Data & Analytics Hub 的题为“3 reasons why DataOps is essential for big data success”的文章中首次提出 DataOps 这一概念。 DataOps 一词后被 Andy Palmer 推广到 Tamr。 DataOps 是“数据运营”的专属名称。 2017 年对 DataOps 来说是意义重大的一年,生态系统取得巨大发展,分析师覆盖范围进一步扩张,关键字搜索量以及调查、出版物和开源项目数均有所提升。 Gartner 在 2018 年的 Hype Cycle for Data Management 中添加了 DataOps 。 (资料来源:https://en.wikipedia.org/wiki/DataOps)
DataOps 宣言确立了以下 DataOps 原则:(https://www.dataopsmanifesto.org/dataops-manifesto.html)
- 持续满足客户需求:我们的首要任务是在几分钟到几周内及尽早并持续交付有价值的内容给客户,并以此满足客户的需求。
- 有价值工作的分析:我们认为评价工作效率的主要度量指标是,提交了多少深度分析的内容、产出多少高准确度的数据以及在顶层框架和系统中贡献了多少。
- 拥抱变化:我们并不抗拒客户需求的变化,事实上,我们欣然接受这些变化,并以此产生竞争优势。 我们相信,与客户直接交谈是最高效、最实用、最敏捷的沟通方式。
- 这是一项团队运动:分析团队将始终具有各种角色、技能、偏好工具和头衔。 多元化的背景和意见可以提高创新力和生产力。
- 日常互动:客户、分析团队和运营必须每天都在整个项目中协同工作。
- 自发组织:我们相信,最好的分析见解、算法、架构、需求和设计都来自于自发组织的团队。
- 减少英雄主义:对于分析的深度和广度,需求正在加速扩大,我们认为分析团队应尽力减少英雄主义,创建可持续且可扩展的数据分析团队和流程。
- 反思:分析团队应定期根据客户、自身和运营统计提供的反馈意见开展自我反思,优化运营绩效。
- 分析即代码:分析团队使用各种工具对数据进行访问、集成、建模和可视化。 从根本上讲,每种工具都会生成代码和配置,这些都会对数据进行操作,从而为进一步理解数据提供帮助。
- 编排:从头到尾编排数据、工具、代码、环境以配合分析团队的工作,这是分析成功的关键因素。
- 使其可复现:结果需要可复现,我们对所有内容进行版本控制:包括数据、底层硬件、软件配置以及特定于工具链中各工具的代码和配置。
- 一次性的工作环境:我们认为,必须为分析团队成员提供易于创建、隔离、安全并能反映其生产环境的一次性工作环境,从而最大程度地降低分析团队的实验成本。
- 简洁性:我们认为,持续关注卓越的技术和良好的设计不仅可以提高敏捷性,也可以提高简洁性,特别是突出显示未完成的工作量。
- 分析即生产:分析管道类似于精益生产线。 我们认为,DataOps 的一个基本概念是注重过程思维,提升分析及生产的效率。
- 质量至上:分析管道在基础上应该有能力自动检测代码、配置和数据中的异常 (jidoka) 与安全问题,并应向操作员提供持续反馈以避免错误 (poka yoke)。
- 监视质量和性能:我们的目标是对性能、安全和质量措施进行持续监视,及时发现意外变化并生成运营统计信息。
- 重用:我们认为,提升分析及生产效率的一个基本方面是避免个人或团队重复以前的工作。
- 缩短周期时间:从将客户需求转化为分析思路,到在开发中创建、并作为可重复生产的流程发布,再到最后的重构和重用产品,我们应尽全力将这一周期耗费的时间和精力降到最低。
当您分析这些原则时,也许会发现 InterSystems IRIS 能够在某些方面起到作用:
- 持续满足客户需求:您可以通过冲刺或迭代创建新的短集成产品、编排、IRIS 多维数据集、报告、BI 可视化和 ML 模型。
- 有价值工作的分析:IRIS 帮助您提供高质量的数据(在持久化类中使用production、适配器和类方法),并使您能够在 IRIS BI 数据透视表(分析设计器)和 IRIS NLP(文本分析)中进行数据探索。
- 自组织:IRIS 简化了自组织,借助统一的数据平台,您只需一个工具即可收集、处理、分析和发布见解。
- 反思:您可以通过此用户门户与用户互动并收集反馈,以改进交付的产品。
- 分析即代码:在 IRIS 数据模型中,多维数据集、仪表板都是代码,具有版本控制和治理功能。
- 编排:IRIS 数据平台可在单个工具中编排数据的引入、扩充、分析工作、数据可视化和 ML。
- 使其可复现:IRIS 支持使用 Docker、Kubernetes (IKO) 和 DevOps 复现结果。
- 一次性环境:IRIS 支持为集成、数据模型、BI 多维数据集和可视化创建 Docker 一次性环境。
- 简洁性:IRIS 数据多维数据集的创建非常简单,无需创建 ETL 脚本,分析器、多维数据集、仪表板的创建均实现可视化和网络化,并且可由用户而不仅是开发者团队完成。 同时,IntegratedML 允许在没有源代码开发的情况下针对常见场景创建 ML。
- 监视质量和性能:IRIS 使用 SAM 监视性能并具有 Web 管理门户。
- 重用:在 IRIS 中,DataOps 项目是类,这些类默认可扩展、可重用。
- 缩短周期时间:用户可以通过自助服务创建仪表板、分析、报告,以及发布和共享工作。
ODSC (https://opendatascience.com/maximize-upstream-dataops-efficiency-through-ai-and-ml-to-accelerate-analytics/) 指出以下 DataOps 策略:

InterSystems IRIS 对以上几点均有所帮助:
- 自助服务配置:用户可以创建和发布多维数据集与仪表板。
- 共享、标记、注解:用户门户可用于共享仪表板,IRIS Analytical Web Portal 允许用户创建、记录、整理到文件夹并标记您的工作。
- 扩充:BPL 可用于扩充数据。
- 准备:BPL、DTL、适配器和 ObjectScript 逻辑可以帮助准备数据。
- 数据市场:数据资产可以发布到 REST API 并通过 IRIS API Manager 获利。
- 数据目录:IRIS 中的数据被组织成类,这些类被存储在类目录系统 (%Dictonary) 中
- 配置文件与分类:可在用户门户和管理门户中为分析项目创建组、文件夹。
- 质量:IRIS 具有实用工具类,可生成示例数据和进行单元测试。
- 沿袭:在 IRIS 中,所有数据资产都相互连接,您可以从数据模型构建多维数据集,再从多维数据集构建仪表板,所有数据资产均可由数据管理者(IRIS 权限系统)控制。
- 掌控:通过管理门户,您可以掌控分析项目的各个方面。
- 数据库数据、文件数据、SaaS API、流:IRIS 为多模型,支持持久性以及数据和文本分析 (NLP)。 以 IRIS API Manager 支持 SaaS API,以 Integration Adapters 和 PEX(带有 Kafka)与 Streams 结合使用。
- 应用程序、BI 工具、分析沙盒:通过 IRIS,您可以使用您喜欢的语言(Java、Python、.NET、Node.js、ObjectScript)创建 DataOps 应用。 虽然 IRIS 是 BI 工具,但是在这个工具中,您可以将连接器与 Power BI 或 MDX 桥结合使用,将 IRIS 作为分析沙盒。
参见我反映 IRIS 和 DataOps 的汇总:
在创建ODBC的SQL网关连接时,需要选择一个系统中已有的DSN才能够正常的连接到数据库去,那如果想要手动的在代码中获取到系统的DSN应该如何进行操作呢,获取到如下图中所示的DSN列表,期待各位的答复,谢谢
我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 3 天的提示:
1. 您可以使用 %Dictionary 类查看类目录,并在 INFORMATION_SCHEMA 表中查看 sql 对象。
2. 可以在 ObjectScript 方法中以动态 SQL 或嵌入式 SQL 使用 SQL。
3. 您可以使用 ?(例如:where country = ?)将参数传递到动态 SQL 字符串, 使用冒号(例如:where country = :variable)将参数传递到嵌入式 SQL。
4. 动态 SQL 示例(来自 Intersystems 文档):
我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 4 天的提示:
1. 所有数据都存储在global中,global名称以 ^ 开头。 global示例:^animal。 global可以有多个数据位置(“子数据”)。 示例:^animal("大象","吃草")。
2. 可从任意系统范围(命名空间)访问 ^%* global。
3. global使 IRIS 能够支持多模型数据(对象、关系、文档、多维等)。
4. 要查看global,请转到 Management Portal > Explorer > Globals > Select Global > View,或者在终端中输入 do ^%G 或 zwrite ^global。
5. 在持久类和 SQL 表之间有自动对应关系:
- 包对应于是 SQL Schema;
- 类是Table;
- 属性是列;
- 方法是存储过程(使用 sqlProc 时);
- 类之间的关系是 SQL 外键约束(必须为双向)。
- 对象是行。
6. 一个表可以对应多个类,但序列类serial是持久类表的一部分(没有特定的表)。
7. 一个类可以对应多个表。
8. 我们有一些类类型:
原文在这里
我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 2 天的提示:
1. 您可以创建持久类(在数据库中具有对应表的类,用于保持类属性)。
2. 持久类示例:
Class dc.Person extends (%Persistent)
{
Property Name As %String;
Property BirthDate As %Date;
}3. 扩展 %Persistent 时,您将获得 %New() 以在内存中创建新实例,获得 %Save() 以保存到数据库,获得 %Id() 以获取该实例在数据库中的唯一 ID,以及获得 %OpenId() 以使用数据库值加载实例。
4. 持久类允许您调用 %Deleteid() 以从数据库中删除一个实例,调用 %DeleteExtent() 以删除所有保存的对象(没有 where 时删除!),调用 %ValidateObject() 以验证保存前传递的数据(验证是否必需、大小等)。
5. 持久类具有 %IsModified() 和 %Reload(),前者用于检查内存中的数据变化(参见评论中 joel 的提示),后者用于获取这些变化。
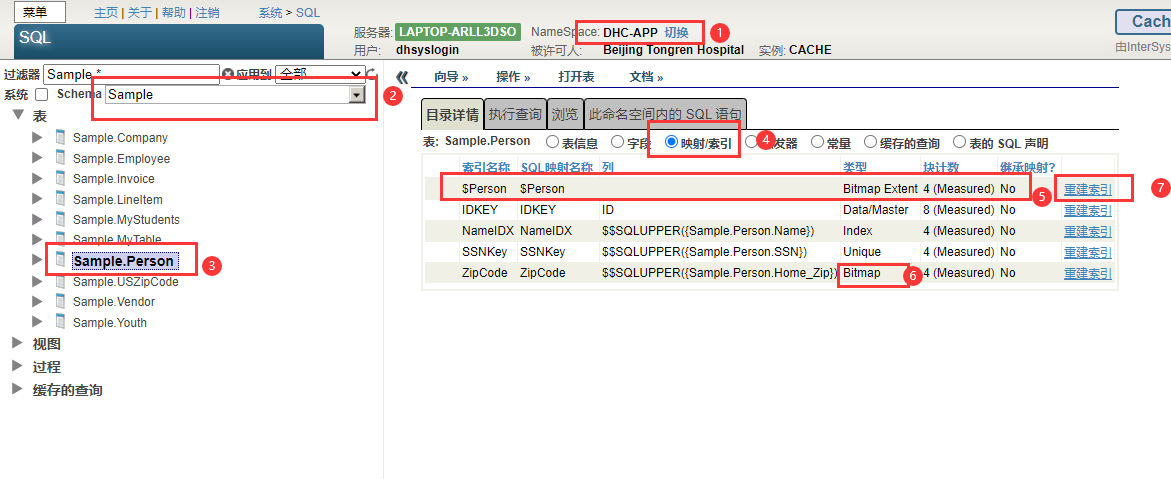
第二章 定义和构建索引(一)
定义索引
使用带有索引的Unique、PrimaryKey和IdKey关键字
与典型的SQL一样,InterSystems IRIS支持惟一键和主键的概念。
InterSystems IRIS还能够定义IdKey,它是类实例(表中的行)的唯一记录ID。
这些特性是通过Unique、PrimaryKey和IdKey关键字实现的:
Unique-在索引的属性列表中列出的属性上定义一个唯一的约束。 也就是说,只有这个属性(字段)的唯一数据值可以被索引。 唯一性是根据属性的排序来确定的。 例如,如果属性排序是精确的,则字母大小写不同的值是唯一的; 如果属性排序是SQLUPPER,则字母大小写不同的值不是唯一的。 但是,请注意,对于未定义的属性,不会检查索引的惟一性。 根据SQL标准,未定义的属性总是被视为唯一的。PrimaryKey-在索引的属性列表中列出的属性上定义一个主键约束。IdKey-定义一个唯一的约束,并指定哪些属性用于定义实例(行)的唯一标识。IdKey总是具有精确的排序规则,即使是数据类型为string时也是如此。
这些关键字的语法出现在下面的例子中:
Class MyApp.SampleTable Extends %Persistent [DdlAllowed]
{
Property Prop1 As %String;
Property Prop2 As %String;
Property Prop3 As %String;
Index Prop1IDX on Prop1 [ Unique ];
Index Prop2IDX on Prop2 [ PrimaryKey ];
Index Prop3IDX on Prop3 [ IdKey ];
}
注意:IdKey、PrimaryKey和Unique关键字只在标准索引下有效。
不能将它们与位图或位片索引一起使用。
同时指定IdKey和PrimaryKey关键字也是有效的语法,例如:
Index IDPKIDX on Prop4 [ IdKey, PrimaryKey ];
这个语法指定IDPKIDX索引既是类(表)的IdKey,也是它的主键。
这些关键字的所有其他组合都是多余的。
对于使用这些关键字之一定义的任何索引,都有一个方法允许打开类的实例,其中与索引关联的属性有特定的值;
定义SQL搜索索引
可以在表类定义中定义SQL搜索索引,如下所示:
Class Sample.TextBooks Extends %Persistent [DdlAllowed]
{
Property BookName As %String;
Property SampleText As %String(MAXLEN=5000);
Index NameIDX On BookName [ IdKey ];
Index SQLSrchIDXB On (SampleText) As %iFind.Index.Basic;
Index SQLSrchIDXS On (SampleText) As %iFind.Index.Semantic;
Index SQLSrchIDXA On (SampleText) As %iFind.Index.Analytic;
}
用索引存储数据
可以使用index Data关键字指定一个或多个数据值的副本存储在一个索引中:
Class Sample.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property SSN As %String(MAXLEN=20);
Index NameIDX On Name [Data = Name];
}
在本例中,索引NameIDX的下标是各种Name值的排序(大写)值。名称的实际值的副本存储在索引中。当通过SQL更改Sample.Person表或通过对象更改对应的Sample.Person类或其实例时,将维护这些副本。
在经常执行选择性(从许多行中选择一些行)或有序搜索(从许多列中返回一些列)的情况下,在索引中维护数据副本会很有帮助。
例如,考虑以下针对Sample.Person表的查询:
SQL引擎可以通过读取NameIDX而从不读取表的主数据来决定完全满足此请求。

注意:不能使用位图索引存储数据值。
索引null
如果一个索引字段的数据为NULL(没有数据存在),相应的索引使用索引NULL标记来表示这个值。
默认情况下,索引空标记值为-1E14。
使用索引空标记可以使空值排序在所有非空值之前。
%Library.BigInt数据类型存储小于-1E14的小负数。默认情况下,%BigInt索引空标记值为-1E14,因此与现有BigInt索引兼容。如果索引的%BigInt数据值可能包括这些极小的负数,则可以使用INDEXNULLMARKER属性参数更改特定字段的索引NULL标记值,作为特性定义的一部分,如下例所示:
Property ExtremeNums As %Library.BigInt(INDEXNULLMARKER = "-1E19");
还可以在数据类型类定义中更改索引NULL标记的默认值。
此参数属性在IRIS里有,Cache里没有。
索引集合
为属性编制索引时,放在索引中的值是整个已整理属性值。对于集合,可以通过将(Elements)或(Key)附加到属性名称来定义与集合的元素和键值相对应的索引属性。(元素)和(键)允许指定从单个属性值生成多个值,并对每个子值进行索引。当属性是集合时,Elements令牌通过值引用集合的元素,Key令牌通过位置引用它们。当元素和键都出现在单个索引定义中时,索引键值包括键和关联的元素值。
例如,假设有一个基于Sample.Person类的FavoriteColors属性的索引。对此属性集合中的项进行索引的最简单形式是以下任一种:
INDEX fcIDX1 ON (FavoriteColors(ELEMENTS));
或
INDEX fcIDX2 ON (FavoriteColors(KEYS));
其中,FavoriteColor(Elements)是指FavoriteColors属性的元素,因为它是一个集合。一般形式是PropertyName(元素)或PropertyName(键),其中该集合的内容是定义为某个数据类型的列表或数组的属性中包含的一组元素)。
若要索引文本属性,可以创建一个由PropertyNameBuildValueArray()方法生成的索引值数组(在下一节中介绍)。与集合本身一样,(Elements)和(Key)语法对索引值数组有效。
如果属性集合被投影为数组,则索引必须遵守以下限制才能被投影到集合表。索引必须包括(键)。索引不能引用集合本身和对象ID值以外的任何属性。如果投影索引还定义了要存储在索引中的数据,则存储的数据属性也必须限制为集合和ID。否则,不会投影索引。此限制适用于投影为数组的集合属性上的索引;不适用于投影为列表的集合上的索引。
与集合的元素或键值对应的索引还可以具有所有标准索引功能,例如将数据与索引一起存储、特定于索引的排序规则等。
InterSystems SQL可以通过指定FOR SOME%ELEMENT谓词来使用集合索引。
使用(Elements)和(Key)索引数据类型属性
为了索引数据类型属性,还可以使用BuildValueArray()方法创建索引值数组。此方法将属性值解析为键和元素的数组;它通过生成从与其关联的属性的值派生的元素值集合来实现这一点。使用BuildValueArray()创建索引值数组时,其结构适合索引。
BuildValueArray()方法的名称为PropertyNameBuildValueArray(),其签名为:
ClassMethod propertynameBuildValueArray(value, ByRef valueArray As %Library.String) As %Status
BuildValueArray()方法的名称以组合方法的典型方式派生于属性名。- 第一个参数是属性值。
- 第二个参数是通过引用传递的数组。 这是一个包含键-元素对的数组,键下标的数组等于元素。
- 该方法返回一
%Status值。
这个例子:
/// DescriptiveWords是一个以逗号分隔的单词字符串
Property DescriptiveWords As %String;
/// 基于描述词的索引
Index dwIDX On DescriptiveWords(ELEMENTS);
/// 方法的作用是:演示如何在属性的子值上建立索引。
///
/// (如果DescriptiveWords被定义为一个集合,则不需要此方法。)
ClassMethod DescriptiveWordsBuildValueArray(
Words As %Library.String = "",
ByRef wordArray As %Library.String)
As %Status {
If Words '= "" {
For tPointer = 1:1:$Length(Words,",") {
Set tWord = $Piece(Words,",",tPointer)
If tWord '= "" {
Set wordArray(tPointer) = tWord
}
}
}
Else {
Set wordArray("TODO") = "Enter keywords for this person"
}
Quit $$$OK
}
在本例中,dwIDX索引基于DescriptiveWords属性。
DescriptiveWordsBuildValueArray()方法接受由Words参数指定的值,基于该值创建一个索引值数组,并将其存储在wordArray中。
InterSystems IRIS在内部使用BuildValueArray()实现;
不调用此方法。
注意:没有必要将任何元素/键值建立在属性值的基础上。 唯一的建议是,每次向该方法传递给定值时,都创建相同的元素和键数组。
为各种实例的描述性词所属性设置值和检查这些值的属性涉及活动(如以下):
SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(3)
SAMPLES>SET empsalesoref.DescriptiveWords = "Creative"
SAMPLES>WRITE empsalesoref.%Save()
1
SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(4)
SAMPLES>SET empsalesoref.DescriptiveWords = "Logical,Tall"
SAMPLES>WRITE empsalesoref.%Save()
1
这 sample index内容,例如:
| DescriptiveWords(ELEMENTS) | ID | Data |
|---|---|---|
| " CREATIVE" | 3 | "" |
| " ENTER KEYWORDS FOR THIS PERSON" | 1 | "" |
| " ENTER KEYWORDS FOR THIS PERSON" | 2 | "" |
| " LOGICAL" | 4 | "" |
| " TALL" | 4 | "" |
注意:此表显示抽象中的索引内容。磁盘上的实际存储形式可能会有所变化。
将数组(元素)上的索引投影到子表
要在嵌入式对象中索引属性,需要在引用该嵌入式对象的持久化类中创建索引。
属性名必须指定表(%Persistent类)中的引用字段的名称和嵌入对象(%SerialObject)中的属性的名称,如下面的示例所示:
Class Sample.Person Extends (%Persistent) [ DdlAllowed ]
{ Property Name As %String(MAXLEN=50);
Property Home As Sample.Address;
Index StateInx On Home.State;
}
此处Home是Sample.Person中引用嵌入对象Sample.Address的属性,该对象包含State属性,如下例所示:
Class Sample.Address Extends (%SerialObject)
{ Property Street As %String;
Property City As %String;
Property State As %String;
Property PostalCode As %String;
}
只有与持久类属性引用相关联的嵌入对象的实例中的数据值被索引。不能直接索引%SerialObject属性。%Library.SerialObject(以及%SerialObject的所有未显式定义SqlCategory的子类)的SqlCategory为字符串。
还可以使用SQL CREATE INDEX语句在嵌入式对象属性上定义索引,如下例所示:
CREATE INDEX StateIdx ON TABLE Sample.Person (Home_State)
类中定义的索引注释
当在类定义中使用索引时,需要记住以下几点:
- 索引定义仅从主(第一个)超类继承。
- 如果使用Studio添加(或删除)数据库中存储数据的类的索引定义,则必须使用“构建索引”中描述的过程之一来手动填充索引。
使用DDL定义索引
如果你使用DDL语句来定义表,也可以使用以下DDL命令来创建和删除索引:
CREATE INDEXDROP INDEX
DDL index命令执行以下操作:
- 它们更新在其上添加或删除索引的相应类和表定义。 重新编译修改后的类定义。
- 它们根据需要在数据库中添加或删除索引数据:
CREATE index命令使用当前存储在数据库中的数据填充索引。 类似地,DROP INDEX命令从数据库中删除索引数据(即实际索引)。
什么是分布式人工智能 (DAI)?
试图找到一个“无懈可击”的定义是徒劳的:这个术语似乎有些“超前”。 但是,我们仍然可以从语义上分析该术语本身,推导出分布式人工智能也是人工智能(请参见我们为提出一个“实用”定义所做的努力),只是它分布在多台没有聚合在一起(既不在数据方面,也不通过应用程序聚合,原则上不提供对特定计算机的访问)的计算机上。 即,在理想情况下,分布式人工智能的安排方式是:参与该“分布”的任何计算机都不能直接访问其他计算机的数据和应用程序,唯一的替代方案是通过“透明的”消息传递来传输数据样本和可执行脚本。 与该理想情况的任何偏差都会导致出现“部分分布式人工智能”- 一个示例是通过中央应用程序服务器分发数据, 或者其反向操作。 不管怎样,我们都会得到一组“联合”模型(即,在各自数据源上训练的模型,或者按自己的算法训练的模型,或者同时以这两种方式训练的模型)。
“面向大众”的分布式人工智能方案
我们不会讨论边缘计算、机密数据操作员、分散的移动搜索,或者类似的引人入胜但又不是最有意识和最广泛应用(目前不是)的方案。 我们将更“贴近于生活”,例如,如果考虑以下方案(其详细演示应该可以在此处观看):一家公司运行一个生产级 AI/ML 解决方案,其运行质量正在由一名外部数据科学家(即,不是该公司员工的专家)系统地进行检查。 由于种种原因,该公司无法授予数据科学家访问该解决方案的权限,但可以按照时间表或在特定事件(例如,解决方案终止一个或多个模型的训练会话)后向其发送所需表中的记录样本。 我们据此假定,该数据科学家拥有某个版本的 AI/ML 机制,且这些机制已经集成在公司正在运行的生产级解决方案中,而且数据科学家本人很可能正在开发、改进和调整这些机制,以适应该具体公司的具体用例。 将这些机制部署到正在运行的解决方案中、监控机制的运行以及其他生命周期方面的工作由一名数据工程师(公司员工)负责。
我们在这篇文章中提供了一个在 InterSystems IRIS 平台上部署生产级 AI/ML 解决方案的示例,该解决方案可自主处理来自设备的数据流。 上一段提供的链接下的演示中也运行了相同的解决方案。 您可以使用我们的仓库 Convergent Analytics 中的内容(免费且无时间限制,请访问 Links to Required Downloads 和 Root Resources 部分)在 InterSystems IRIS 上构建您自己的解决方案原型。
通过这样的方案,我们可获得“分布程度”如何的人工智能? 在我们看来,此方案相当接近理想情况,因为数据科学家与公司的数据和算法均保持“切割”(只是传输了有限的样本,但在某个时间点前很重要;而且数据科学家自己的“样本”永远不会与作为实时生产级解决方案的一部分部署和运行的“活跃”机制 100% 同步),他完全不能访问公司的 IT 基础架构。 因此,数据科学家的作用变为在他的本地计算资源上部分重放该公司生产级 AI/ML 解决方案的运行片段,获得可接受置信级别的运行质量评估,并向公司返回反馈(在我们的具体方案中,以“审核”结果表示,可能还加上该公司解决方案涉及的 AI/ML 机制的改进版本)。

图 1 分布式人工智能方案表示
我们知道,在人类执行人工智能项目交换的过程中,不一定需要表示和传输反馈,这源于有关现代方法的出版物以及已有的分布式人工智能实现经验。 但是,InterSystems IRIS 平台的优势在于,它允许同样高效地开发和启动“混合”(人类和机器串联)且完全自动化的人工智能用例,因此,我们将继续根据上述“混合”示例进行分析,同时为读者留下自行阐述其完全自动化的可能性。
如何在 InterSystems IRIS 平台上运行具体的分布式人工智能方案
本文上一节提到的带有方案演示的视频介绍对作为实时 AI/ML 平台的 InterSystems IRIS 进行了总体概述,并解释了其对 DevOps 宏机制的支持。 在演示中,没有明确覆盖负责定期将训练数据集传输给外部数据科学家的“公司侧”业务流程,因此,我们将从该业务流程及其步骤的简介开始。
发送方业务流程的一个主要“引擎”是 while 循环(使用 InterSystems IRIS 可视业务流程编辑器实现,该编辑器基于平台解释的 BPL 表示法),负责将训练数据集系统地发送给外部数据科学家。 该“引擎”内部执行以下操作(参见下图,跳过数据一致性操作):

图 2“发送方”业务流程的主要部分
(a) 负载分析器 – 将训练数据集表中的当前记录集加载到业务流程中,并基于它在 Python 会话中形成一个数据框架。 调用操作会触发对 InterSystems IRIS DBMS 的 SQL 查询,并触发对 Python 接口的调用以将 SQL 结果传输给它,以便形成数据框架;
(b) Azure 分析器 – 另一个调用操作,触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从而在 Azure 中构建所需的基础架构,并在该基础架构上部署前一个操作中形成的数据框架数据;
作为执行上述业务流程操作的结果,我们在 Azure 中获得一个存储对象(一个 .csv 文件),其中包含公司的生产级解决方案用于模型训练的最近数据集的导出:

图 3 训练数据集“到达”Azure ML
这样,发送方业务流程的主要部分已经结束,但是我们还需要再执行一个操作,同时请记住,我们在 Azure ML 中创建的任何计算资源都是可计费的(参见下图,跳过数据一致性操作):

图 4“发送方”业务流程的最后部分
(c) 资源清理 – 触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从 Azure 中删除上一个操作中构建的计算基础架构。
数据科学家所需的数据已经传输完毕(数据集现在在 Azure 中),因此我们可以继续启动将访问数据集的“外部”业务流程,运行至少一次替代模型训练(从算法上讲,替代模型不同于作为生产级解决方案一部分运行的模型),并向数据科学家返回得到的模型质量指标及可视化,从而表示有关公司生产级解决方案运行效率的“审核结果”。
我们现在看一下接收方业务流程:与发送方业务流程(在包含公司自主 AI/ML 解决方案的其他业务流程中运行)不同,它不需要 while 循环,而是包含与在 Azure ML 和 IntegratedML(InterSystems IRIS 中用于自动 ML 框架的加速器)中训练替代模型有关的一系列操作,并将训练结果提取到 InterSystems IRIS 中(该平台也被认为在数据科学家处本地安装):

图 5“接收方”业务流程
(a) 导入 Python 模块 – 触发对 Python 接口的调用,以向其传输一组指令,导入进一步操作所需的 Python 模块;
(b) 设置 AUDITOR 参数 – 触发对 Python 接口的调用,以向其传输一组指令,为进一步操作所需的变量指定默认值;
(c) Azure ML 审核 –(我们将跳过任何对 Python 接口触发的进一步引用)将“审核任务”提交到 Azure ML;
(d) 解释 Azure ML – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起获取到本地 Python 会话中(此外,在 Python 会话中创建“审核”结果的可视化);
(e) 流式传输到 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从本地 Python 会话中提取到 IRIS 中的业务流程变量;
(f) 填充 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从 IRIS 中的业务流程变量写入 IRIS 中的表;
(g) IntegratedML 审核 – 使用 IntegratedML 加速器“审核”从 Azure ML 接收的数据以及上一个操作中写入 IRIS 的 Azure ML“审核”结果(在此特定情况下,该加速器处理 H2O auto-ML 框架);
(h) 对 Python 进行查询 – 将数据和 IntegratedML“审核”结果传输到 Python 会话中;
(i) 解释 IntegratedML – 在 Python 会话中,创建 IntegratedML“审核”结果的可视化;
(j) 资源清理 – 从 Azure 中删除先前的操作中创建的计算基础架构。

图 6 Azure ML“审核”结果的可视化

图 7 IntegratedML“审核”结果的可视化
分布式人工智能一般如何在 InterSystems IRIS 平台上实现
InterSystems IRIS 平台实现分布式人工智能有三种基本方法:
· 根据用户定义的规则和算法,直接交换人工智能项目,并对其进行本地和中央处理
· 人工智能项目处理委托给专门的框架(例如:TensorFlow、PyTorch),交换的编排和各个准备步骤由用户在 InterSystems IRIS 的本地和中央实例上配置
· 人工智能项目的交换和处理都通过云提供商(Azure、AWS、GCP)来完成,本地和中央实例只向云提供商发送输入数据并接收最终结果

图 8 在 InterSystems IRIS 平台上实现分布式人工智能的基本方法
这些基本方法可以修改/组合使用:尤其是,在本文的上一节(“审核”)所描述的具体方案中,使用了第三种方法“以云为中心”,将“审核员”部分划分到云端,而在数据科学家一侧执行本地部分(作为“中央实例”)。
目前,在我们生活的现实中,“分布式人工智能”学科的理论和应用要素正在不断积累,但还没有形成“规范形式”,这使得创新实现具有巨大潜力。 我们的专家团队密切关注分布式人工智能作为一门学科的发展,并为其在 InterSystems IRIS 平台上的实现设计加速器。 我们乐于分享我们的内容,并帮助每一个认为这里讨论的领域有用的人开始分布式人工智能机制的原型设计。 您可以使用以下电子邮件地址联系我们的 AI/ML 专家团队 – MLToolkit@intersystems.com。
Hi 社区开发者们,告诉大家一个好消息!InterSystems IRIS®数据平台已入驻AWS Quick Start,今后可在AWS上快速部署高可用的生产环境。
第二章 定义和构建索引(一)
概述
索引是由持久类维护的结构,InterSystems IRIS®数据平台可以使用它来优化查询和其他操作。
可以在表中的字段值或类中的相应属性上定义索引。(还可以在多个字段/属性的组合值上定义索引。)。无论是使用SQL字段和表语法还是类属性语法定义相同的索引,都会创建相同的索引。当定义了某些类型的字段(属性)时,InterSystems IRIS会自动定义索引。可以在存储数据或可以可靠派生数据的任何字段上定义附加索引。InterSystems IRIS提供了几种类型的索引。可以为同一字段(属性)定义多个索引,为不同的目的提供不同类型的索引。
无论是使用SQL字段和表语法,还是使用类属性语法,只要对数据库执行数据插入、更新或删除操作,InterSystems IRIS就会填充和维护索引(默认情况下)。可以覆盖此默认值(通过使用%NOINDEX关键字)来快速更改数据,然后作为单独的操作生成或重新生成相应的索引。可以在用数据填充表之前定义索引。还可以为已经填充了数据的表定义索引,然后作为单独的操作填充(构建)索引。
InterSystems IRIS在准备和执行SQL查询时使用可用的索引。默认情况下,它选择使用哪些索引来优化查询性能。 可以根据需要覆盖此默认值,以防止对特定查询或所有查询使用一个或多个索引。
索引属性
每个索引都有一个唯一的名称。此名称用于数据库管理目的(报告、索引构建、删除索引等)。与其他SQL实体一样,索引同时具有SQL索引名和相应的索引属性名;这些名称在允许的字符、区分大小写和最大长度方面有所不同。如果使用SQL CREATE INDEX命令定义,系统将生成相应的索引属性名称。如果使用持久类定义进行定义,则SqlName关键字允许用户指定不同的SQL索引名(SQL映射名称)。 Management Portal SQL界面的Catalog Details显示每个索引的SQL索引名称(SQL映射名称)和相应的索引属性名称(索引名称)。
索引类型由两个索引类关键字Type和Extent定义。IRIS提供的索引类型包括:
- 标准索引(
Type = index)——一个持久数组,它将索引值与包含该值的行的 RowID相关联。 任何没有明确定义为位图索引、位片索引或区段索引的索引都是标准索引。 - 位图索引(
Type = Bitmap)——一种特殊的索引,使用一系列位字符串来表示与给定索引值对应的RowID值集; InterSystems IRIS包括许多位图索引的性能优化。 - 位片索引(
Type = Bitslice)——一种特殊的索引,能够非常快速地计算某些表达式,例如总和数和范围条件。 某些SQL查询自动使用位片索引。 - 区段索引(
Extent Indices)——一个区段中所有对象的索引。 有关更多信息,请参阅类定义参考中的区段索引关键字页。 - 范围索引-范围中所有对象的索引。
表(类)的最大索引数为400。
存储类型和索引
这里描述的索引功能适用于存储在持久化类中的数据。
InterSystems SQL支持使用InterSystems IRIS默认存储结构存储的数据的索引功能:%Storage.Persistent(%Storage.Persistent映射类)。
InterSystems SQL还支持使用%Storage.SQL(%Storage.SQL映射的类)存储的数据的索引功能。可以使用函数索引类型为%Storage.SQL映射的类定义索引。索引的定义方式与使用默认存储的类中的索引相同,但有以下特殊注意事项:
- 如果
IdKey函数索引不是系统自动分配的,则该类必须定义IdKey函数索引。 - 此功能索引必须定义为索引。
请注意,不应直接调用%Storage.Persistent和%Storage.SQL类方法。相反,应该使用%Persistent类方法和本章中描述的操作调用索引功能。
索引全局名称
使用以下两种策略之一生成用于存储索引数据的下标全局:
%CLASSPARAMETER USEEXTENTSET=0使用全局命名策略创建由用户指定的名称、附加的字母代码和索引名称组成的“传统”全局名称。用户可以理解这些全局名称,但它们可能很长,并且效率低于散列的全局名称。- 如果
USEEXTENTSET=0且未指定DEFAULTGLOBAL,则以下示例将描述生成的全局名称:Sample.MyTest持久类将定义名为^Sample.MyTestD的master map全局名^Sample.MyTestD位图范围索引全局名^Sample.MyTestI(“$MyTest”)(或^Sample.MyTestI(“DDLBEIndex”)),并且对于定义的索引NameIDX,它将定义名为^Sample.MyTestI(“DDLBEIndex”)的全局名。请注意,这些全局变量指定的是持久性类名(区分大小写),而不是SQL表名。 - 如果
USEEXTENTSET=0并指定了DEFAULTGLOBAL,则指定的全局名称将替换永久类名。这允许指定一个比持久类名称更短或更清晰的名称。例如,如果DEFAULTGLOBAL=“MyGlobal”,则全局变量的名称如下:^MyGlobalD和^MyGlobalI(“NameIDX”)。
- 如果
%CLASSPARAMETER USEEXTENTSET=1使用创建哈希全局名称的全局命名策略。这包括对包名进行散列,对类名进行散列,然后追加一个点和一个标识索引的连续整数后缀。这些全局名称对用户来说不太容易理解,但往往更短、效率更高。
整数后缀仅作为索引名的关键字;与索引名和索引类型相关联的字段对整数编号没有影响。例如,^EW3K.CgZk.1 是 Master Map,^EW3K.CgZk.2是位图范围(Bitmap Extent),^EW3K.CgZk.3是LastName字段的已定义标准索引NameIDX,^EW3K.CgZk.4是已定义索引WorkIdIDX。如果删除NameIDX,则全局^EW3K.CgZk.3也会被删除,从而在整数序列中产生间隙。如果为LastName字段定义LNameIDX,则会创建全局^EW3K.CgZk.5;但是,如果稍后为FullName字段创建位图索引NameIDX,则全局索引将再次为^EW3K.CgZk.3。
- 如果
USEEXTENTSET=1并且未指定DEFAULTGLOBAL,则包名和类名将被散列,如上所述。将追加连续的整数后缀。 - 如果
USEEXTENTSET=1并指定了DEFAULTGLOBAL,则使用DEFAULTGLOBAL名称,而不是散列的包名和类名。将追加连续的整数后缀。例如,如果DEFAULTGLOBAL="MyGlobal",则全局变量的名称如下:^MyGlobal.1和^MyGlobal.3
如果使用CREATE TABLE命令定义表,则USEEXTENTSET默认为1。因此,默认情况下,CREATE TABLE创建散列全局名称。可以使用%CLASSPARAMETER关键字以及USEEXTENTSET和DEFAULTGLOBAL参数更改此默认行为。可以使用$SYSTEM.SQL.Util.SetOption()方法在系统范围内更改此默认设置。
SET status=$SYSTEM.SQL.Util.SetOption("DDLUseExtentSet",0,.oldval).
如果定义投影到表的持久类,则USEEXTENTSET默认为0。因此,默认情况下,使用传统的全局名称。
DEFAULTGLOBAL(如果已定义)将作为默认值。如果定义了ExtentLocation、DataLocation或IndexLocation存储关键字,则使用这些值,而不是上述默认值。
可以向ZWRITE提供全局名称以显示索引数据。
Master Map
系统自动为每个表定义一个主图(Data/Master)。Master Map不是索引,它是使用其Map下标字段直接访问数据本身的Map。默认情况下,Master Map下标字段是系统定义的RowID字段。默认情况下,使用RowID字段进行的这种直接数据访问由SQL映射名称(SQL索引名称)IDKEY表示。
默认情况下,用户定义的主键不是IDKEY。这是因为使用RowID整数查找 Master Map总是比使用主键值查找效率更高。 但是,如果指定主键为IDKEY,则主键索引被定义为表的主映射,SQL映射名称为主键SQL索引名。
对于单字段key/IDKEY,,主键索引是主映射,但主映射数据访问列仍然是RowID。这是因为在记录的唯一主键字段值和其RowID值之间存在一对一的匹配,而RowID被认为是更高效的查找。对于多字段主键/IDKEY,会为Master Map指定主键索引名称,并且Master Map Data Access列是主键字段。
可以通过Management Portal SQL Catalog Details(管理门户SQL目录详细信息)选项卡查看主图定义。除其他项目外,它还显示存储Master Map数据的全局名称。对于SQL和默认存储,此主映射全局默认为^Package.classnameD,并记录命名空间以防止歧义。对于自定义存储,未定义主地图数据存储全局名称;可以使用DATALOCATIONGLOBAL类参数指定数据存储全局名称。
对于SQL和默认存储,主映射数据存储在下标全局名为^package.classnameD 或 ^hashpackage.hashclass.1。请注意,全局名指定持久类名,而不是相应的SQL表名,并且全局名区分大小写。可以向ZWRITE提供全局名称以显示Master Map数据。
使用Master Map访问数据效率很低,尤其是对于大型表。因此,建议用户定义可用于访问WHERE条件、联接操作和其他操作中指定的数据字段的索引。
自动定义的索引
定义表时,系统会自动定义某些索引。在为表格定义并在添加或修改表数据时,自动生成以下索引。如果定义:
- 不是
IDKEY的主键,则系统会生成唯一类型的相应索引。主键索引的名称可以是用户指定的,也可以是从表名派生的。例如,如果定义一个未命名的主键,则相应的索引将命名为tablenamePKEY#,其中#是每个UNIQUE和PRIMARY KEY约束的顺序整数。 - 唯一的字段,Intersystems Iris为每个唯一字段生成索引,其中名称T
ableNameUnique#,其中#是每个唯一和主键约束的顺序整数。 - 唯一约束,系统为每个具有指定名称的唯一约束生成索引,为共同定义唯一值的字段编制索引。
- shard key,系统在shard key字段上生成一个索引,命名为
ShardKey。
可以通过Management Portal SQL Catalog Details选项卡查看这些索引。CREATE INDEX命令可用于添加唯一字段约束;DROP INDEX命令可用于删除唯一字段约束。
默认情况下,系统在RowID字段上生成IDKEY索引。定义身份字段不会生成索引。但是,如果定义标识字段并将该字段作为主键,则InterSystems IRIS将在标识字段上定义IDKEY索引并将其作为主键索引。下面的示例显示了这一点:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentPK PRIMARY KEY (StudentID) )
同样,如果定义标识字段并为该字段提供唯一约束,则InterSystems IRIS将在标识字段上显式定义IdKey/Unique索引。下面的示例显示了这一点:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentU UNIQUE (StudentID) )
这些标识索引操作仅在没有明确定义的idkey索引时出现,并且表不包含任何数据。
位图范围索引
位图范围索引是表的行的位图索引,而不是针对表的任何指定字段。在位图范围索引中,每个位表示顺序ROWID整数值,并且每个位的值指定相应的行是否存在。
SQL使用此索引来提高Count(*)的性能,返回表中的记录数(行)。
一个表最多可以有一个位图区段索引。创建多个位图范围索引导致SQLCode -400错误。 其中 ERROR #5445: Multiple Extent indices defined:DDLBEIndex.
所有使用CREATE TABLE定义的表都会自动定义位图区段索引。
将此自动生成的索引分配索引名称(索引属性名称)DDLBEIndex和SQL MapName (SQL索引名称)%%DDLBEIndex。
定义为类的表可以有一个位图区索引,索引名和$ClassName的SQL MapName(其中ClassName是表的持久化类的名称)。
可以使用带有BITMAPEXTENT关键字的CREATE INDEX命令将位图区段索引添加到表中,或者重命名自动生成的位图区段索引。
可以通过管理门户SQL Catalog详细选项卡查看表的位图范围索引。虽然表只有一个位图范围索引,但是从另一个表中继承的表在其自身位图范围索引和它从其扩展的表中的位图范围索引中列出。例如,Sample.employee表扩展了Sample.person表;在目录详细信息映射 Sample.Employee列出$Employee 和 $Person Bitmap范围索引。
在经历许多删除操作的表格中,位图范围索引的存储可以逐渐变得效率较低。可以通过选择表的“目录详细信息”选项卡,“映射”选项和选择重建索引来重建从管理门户中重建位图范围索引。
%SYS.Maint.Bitmap实用程序方法压缩位图范围索引,以及位图指数和bitslice索引。
在以下任何情况下,调用%BuildIndices()方法都会构建现有的位图范围索引:未指定%BuildIndices() pIndexList参数(构建所有定义的索引);pIndexList按名称指定位图范围索引;或pIndexList指定任何定义的位图索引。
定义索引
使用类定义定义索引
在Studio中,可以使用新建索引向导或通过编辑类定义的文本将索引定义添加到%Persistent类定义。索引在一个或多个索引属性表达式上定义,后跟一个或多个可选索引关键字(可选)。它采用以下形式:
INDEX index_name ON index_property_expression_list [index_keyword_list];
index_name是有效的标识符。index_property_expression_list是一个或多个以逗号分隔的属性表达式的列表,它们作为索引的基础。index_keyword_list是一个可选的索引关键字列表,用逗号分隔,用方括号括起来。 用于指定位图或位片索引的索引类型。 也用于指定唯一的、IdKey或PrimaryKey索引。 (根据定义,IdKey或PrimaryKey索引也是唯一索引。) 索引关键字的完整列表出现在类定义引用中。
index_property_expression_list参数由一个或多个索引属性表达式组成。
索引属性表达式包括:
- 要建立索引的属性的名称。
- 可选(元素)或(键)表达式,提供对集合子值进行索引的方法。
如果
index属性不是一个集合,用户可以使用BuildValueArray()方法生成一个包含键和元素的数组。 - 可选的排序规则表达式。
它包含一个排序规则名称,后面可选地跟着一个或多个以逗号分隔的排序规则参数列表。
不能为惟一索引、
IdKey索引或PrimaryKey索引指定索引排序规则。 唯一索引或PrimaryKey索引从正在建立索引的属性(字段)中获取其排序规则。IdKey索引总是精确(EXACT)的排序。
例如,下面的类定义定义了两个属性和一个基于它们的索引:
Class MyApp.Student Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property GPA As %Decimal;
Index NameIDX On Name;
Index GPAIDX On GPA;
}
更复杂的索引定义是:
Index Index1 On (Property1 As SQLUPPER(77), Property2 AS EXACT);
可以建立索引的属性
唯一可以被索引的属性是:
- 那些存储在数据库中的
- 那些可以从存储的属性可靠地派生出来的
必须使用SQLComputed关键字定义可以可靠地派生(并且未存储)的属性; SQLComputeCode指定的代码必须是导出属性值的唯一方法,并且无法直接设置属性。
如果可以直接设置一个派生属性的值,比如是一个简单的情况下(non-collection)属性定义为瞬态和不也定义为计算,然后直接设置属性的值将覆盖SQLComputeCode中定义的计算和存储的值不能可靠地来自属性;
这种类型的派生属性称为不确定性。(计算的关键字实际上意味着没有分配实例内存。)
一般规则是,只有定义为calculate和SQLComputed的派生属性才能被索引。
但是,派生集合有一个例外:派生的(SQLComputed)集合是暂时的(没有存储)集合,也没有定义为计算的集合(意味着没有实例内存)可以被索引。
注意:IdKey索引所使用的任何属性的值内都不能有连续的一对竖条(||),除非该属性是对持久类实例的有效引用。
这个限制是InterSystems SQL内部机制所要求的。
在IdKey属性中使用||会导致不可预知的行为。
多个属性的索引
可以在两个或多个属性(字段)的组合上定义索引。在类定义中,使用索引定义的ON子句指定属性列表,例如:
Class MyApp.Employee Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Salary As %Integer;
Property State As %String(MAXLEN=2);
Index MainIDX On(State,Salary);
}
如果需要执行使用字段值组合的查询,例如:
SELECT Name,State,Salary
FROM Employee
ORDER BY State,Salary
索引排序
唯一索引、PrimaryKey索引或IdKey索引不能指定排序规则类型。
对于其他类型的索引,索引定义中指定的每个属性都可以有一个排序规则类型。
应用索引时,索引排序类型应与属性(字段)排序类型匹配。
- 如果索引定义包含为属性显式指定的排序规则,则索引使用该排序规则。
- 如果索引定义不包括为属性显式指定的排序规则,则索引使用属性定义中显式指定的排序规则。
- 如果属性定义不包括显式指定的排序规则,则索引使用属性数据类型的默认排序规则。
例如,Name属性被定义为字符串,因此在默认情况下具有SQLUPPER排序规则。
如果在Name上定义一个索引,默认情况下,它接受属性的排序规则,索引也将使用SQLUPPER定义。
属性排序和索引排序匹配。
但是,如果比较应用不同的排序规则,例如,WHERE %EXACT(Name)=%EXACT(:invar),则此用法中的属性排序规则类型不再与索引排序规则类型匹配。属性比较排序规则类型与索引排序规则类型之间的不匹配可能会导致不使用索引。因此,在这种情况下,可能希望为具有精确(EXACT)排序规则的Name属性定义索引。如果JOIN语句的ON子句指定了排序规则类型,例如,FROM Table1 LEFT JOIN Table2 ON %EXACT(Table1.Name) = %EXACT(Table2.Name),此处指定的属性排序类型与索引排序类型不匹配可能导致InterSystems IRIS不使用该索引。
以下规则控制索引和属性之间的排序规则匹配:
- 匹配的排序规则类型总是最大限度地使用索引。
- 排序规则类型不匹配,其中属性指定为精确的排序规则(如上所示),并且索引有一些其他的排序规则,允许使用索引,但是它的使用不如匹配排序类型有效。
- 排序规则类型不匹配,其中属性排序规则不准确,属性排序规则不匹配索引排序规则,这将导致不使用索引。
要在索引定义中显式地为属性指定排序规则,语法如下:
Index IndexName On PropertyName As CollationName;
IndexName是索引的名称PropertyName是被索引的属性CollationName是用于索引的排序规则的类型
例如:
Index NameIDX On Name As Exact;
不同的属性可以有不同的排序规则类型。
例如,在下面的例子中,F1属性使用SQLUPPER排序,而F2使用EXACT排序:
Index Index1 On (F1 As SQLUPPER, F2 As EXACT);
注意:指定为Unique、PrimaryKey或IdKey的索引不能指定索引排序规则。
索引从属性collations中获取其collation。
第一章 SQL性能优化简介
InterSystems SQL支持几个特性来优化InterSystems IRIS®数据平台的SQL性能。
表定义优化
SQL性能从根本上取决于良好的数据架构。 将数据划分为多个表并在这些表之间建立关系对于高效的SQL是必不可少的。
描述了以下优化表定义的操作。 这些操作要求定义表,但不要求用数据填充表:
- 数据存储策略:可以选择使用
%Storage.Persistent、%Storage.SQL或自定义存储来存储数据。 - 全局变量命名策略:可以使用
USEEXTENTSET参数为数据和索引查找操作指定更短、更高效的散列全局名称。 - 索引:可以为一个表字段或一组字段定义索引。可以定义几种不同类型的索引:标准索引、位图索引、位图索引和位图范围索引。SQL优化使用定义的索引而不是数据值本身来访问查询、更新或删除操作的特定记录。
表数据优化
根据对表中典型数据的分析,可以执行以下操作来优化表访问:
- Tune Table:检查典型的表数据并生成
ExtentSize(行数)、选择性(具有特定值的行的百分比)和BlockCount元数据。查询优化器使用此信息来确定最有效的查询执行计划。 - 选择性和异常值选择性:确定某个字段具有特定值的行的百分比,以及某个值是否为异常值,该值明显比该字段的其他值更常见。
查询优化
在几乎所有情况下,用嵌入式SQL编写的查询的执行速度都比用动态SQL编写的查询快。还要注意,由于存在缓存查询,对于嵌入式SQL和动态SQL,重新执行查询的速度都比初始执行快得多。
可以执行以下操作来优化特定查询的执行。这些查询优化使用现有的表定义和表数据优化:
- 运行时统计:用于衡量系统上查询执行的性能。
- 显示计划显示查询的执行计划。
- 缓存查询和文字替换:维护最近动态查询的缓存,允许重新执行查询,而不会重复准备查询的开销。
- SQL语句和冻结计划允许保留查询执行计划,从而允许在不降低现有查询性能的情况下更改表。
- 索引配置和使用:用于指定如何使用现有索引。
- 索引优化提示:
%ALLINDEX、%IGNOREINDEX - 联接优化提示:
%FIRSTTABLE、%FULL、%INORDER、%STARTTABLE - 子查询优化提示:
%NOFLATTEN、%NOMERGE、%NOREDUCE、%NOSVSO - 并行查询执行:
%Parallel - 联合优化:
UNION %PARALLEL,UNION/OR
还可以通过使用数据分片来提高对大型数据库表的查询性能。
配置优化
默认情况下,内存和启动设置默认为自动配置,每个进程的最大内存默认为262144 kb。要优化在生产系统上运行的SQL,应该将默认值更改为手动配置,并增加每进程的最大内存设置。
分片
分片是跨多个系统对数据及其关联缓存进行分区。分片集群跨多个InterSystems IRIS实例(称为碎片数据服务器)水平(即按行)对大型数据库表进行分区,同时允许应用程序通过单个实例(称为碎片主数据服务器)透明地访问这些表。
必须将表定义为分片。分片表只能在分片环境中使用;非分片表可以在分片或非分片环境中使用。并不是所有的表都适合进行分片。分片环境中的最佳性能通常是通过组合使用分片表(通常非常大的表)和非分片表来实现的
快速命令
InterSystems SQL支持快速选择、快速插入和快速截断表。“快速”意味着这些SQL命令的标准调用是使用高效的内部代码执行的。这些快速操作“就是工作”;没有使用特殊语法,也没有提供优化选项。
通过ODBC或JDBC的SELECT查询支持快速选择。JDBC上的插入操作支持快速插入。对于不涉及参照完整性的截断表操作,支持快速截断表。
并不是所有的表都支持快速操作,也不是所有的命令语法都可以使用快速执行来执行。InterSystems SQL在可能的情况下执行快速执行;如果无法执行快速执行,InterSystems SQL将执行指定命令的标准执行。
人月神话
焦油坑
- 编程系统产品开发的工作量是供个人使用的,独立开发的构件程序的9倍。我估计软件构件产品化引起了3倍工作量,将软件构件整合成完成系统所需要的设计,集成和测试又强加了3倍工作量,这些高成本的构件在根本上是互相独立的。
- 编程行业“满足我们内心深处的创造渴望和愉悦所有人的共有情感”,其提供了五种乐趣:
- 创建事物的快乐
- 开发对其他人有用的东西的乐趣
- 将可以活动,相互啮合的零部件组装成类似迷宫的东西,这个过程所体现出令人神魂颠倒的魅力。
- 面对不重复的任务,不断学习的乐趣。
- 纯粹的思维活动。
- 同样,这个行业具有一些内在固有的苦恼:
- 将做事方式调正到追求完美是学习编程的最困难的部分。
- 由其他人设定目标,并且必须依靠自己无法控制的事物,权威不等同于责任
- 任何创造性活动都伴随着枯燥艰苦的劳动,编程也不例外
- 人们通常期望项目在接近结束时,软件项目能收敛得快一些,然后,情况却是越接近完成,收敛得越慢。
- 产品在完成前总面临着陈旧过时的威胁;只有实际需要时,才会用到最新的设想。
人月神话
- 缺乏合理的时间进度是造成项目滞后的主要原因,它比其他所有因素的总和影响还大。
- 所有的编程人员都是乐观主义者“一切都将运作良好”
- 由于编程人员通过纯粹的思维活动来开发,我们期待在实现过程中不会碰到困难。
- 但是,我们的构思本身是有缺陷的,因此总会有bug。
- 围绕着成本合算的估计技术,混淆了工作量和项目进度。人月是危险和带有欺骗性的神话,因为它暗示了人员数量和时间可以互相替换的。
- 在若干人员中分解任务会引发额外的沟通工作量-培训和相互沟通。
- 关于进度安排,我的经验是1/3计划,1/6编码,1/4构件测试以及1/4系统测试。
- 作为一门学科,我们缺乏数据估计。
- 我们对自己的估计技术不确定,因为在管理和客户的压力下,我们常常缺乏坚持的勇气。
- Brooks法则:为进度落后的项目增加人手,只会使进度更加落后。
- 向软件项目中增派人手三个方面增加了项目必要的总体工作量:任务重新分配本身和所造成的工作中断:培训新人员:额外的互相沟通。
外科手术队伍
- 同样有两年讲演而且在收到同样培训的情况下,优秀的专业程序员的生产率是较差的程序员的10倍。
- 小型,精干队伍是最好的-思绪尽可能少。
- 实际上,绝大数大型编程系统的经验显示,一拥而上的开发方法是高成本,速度缓慢,低效的,开发出的产品无法进行概念上的集成。
- 一位首席程序员,类似于外科手术队伍的团队架构提供了一种方法-既能获得由少数头脑产生的产品完整性,又能得到多位协助人员的总体生产率,还彻底减少了沟通的工作量。
贵族专制,民主政治和系统设计
- “概念完整性是系统设计中最重要的考虑因素。”
- “功能与理解上的复杂程度的比值才是系统设计的最终测试标准”,而不是丰富的功能。
- 为了获得概念完整性,设计必须由一个人或者具有共识的小型团队来完成。
- 将体系结构方面与具体实现相分离是获得概念完整性的强有力方法。
- 如果要得到系统概念上的完整性,就必须有人控制这些概念。实际上是一种无序任何歉意的贵族专制统治。
- 概念上统一的系统能更快地开发和测试。
- 体系结构,设计实现,物理实现的许多工作可以并行。
画蛇添足
- 尽早交流和持续沟通能使结构师有较好的成本意识,使开发人员获得对设计的信心,并且不会混淆各自的责任分工。
- 结构师如何成功地影响实现:
- 牢记开发人员承担创造性的实现责任;结构师只能提出建议。
- 时刻准备着所指定的说明建议一种实现的方法,准备接受任何其他可行的方法
- 对上述建议保持低调和平静。
- 准备对所建议的改进放弃坚持。
- 听取开发人员在体系结构上改进的建议。
- 第二个系统是人们所设计的最危险的系统,通常的倾向是过分地进行设计。
贯彻执行
- 即使是大型的设计团队,设计结果也必须由一个或两个人来完成,以确保这些决定是一致的。
- 必须明确定义体系结构与先前定义不同的地方。
- 处于精确性的考虑,我们需要形式化地设计定义,同样,我们需要记叙性定义来加深理解。
为什么巴比伦塔会失败
- 巴比伦塔项目的失败是因为缺乏交流以及交流的结果 - 组织。
- “因为左手不知道右手在做什么,从而进度灾难,功能的不合理和系统缺陷纷纷出现。”由于存在对其他人的各种假设,团队成员之间的理解开始出现偏差。
- 团队应该以尽可能多的方式进行互相之间交流,非正式地进行简要技术陈述的常规项目会议,共享的正式项目工作手册。
- 项目工作手册“不是独立的一篇文档”它是对项目必须产生的一系列文档进行组织的一种结构。
- 项目所有的文档都必须是该结构的一部分。
- 需要尽早和仔细地设计工作手册结构。
- 事先制定良好结构的工作手册“可将后来书写的文字放置在合适的章节中”并且可以提高产品手册的质量。
- 每一个团队成员称该了解所有的材料。
- 实时更新是至关重要的。
- 共享的电子手册是能达到所有这些目标的,更好的,更加低廉的,更加简单的机制。
- 团队组织的目标是为了减少必须的交流和协作量。
- 组织中的交流是网状么,而不是树状结构, 因此所有的特殊组织机制(往往体现为组织结构中的虚线部分)都是为了进行调整,以克服树状组织结构中交流缺乏的困难。
- 每个子项目具有里那个领导角色 - 产品负责任,技术主管或结构师。这两个角色的职能有很大的区别,需要不同的技能。
- 两个角色的任意组合都可以是非常有效的。
胸有成竹
- 仅仅通过对编码部分时间的估计,然后乘以其他部分的相对系数,是无法得出对整项工作的精确估计的。
- 构建独立小程序的数据不适用于编程系统项目。
- 当使用适当的高级语言时,程序编制的生产率可以提高五倍。
削足适履
- 除了运行时间意外,程序所占据的内存空间也是主要的开销。
- 从系统整体出发以及面相用户的态度是软件编程管理人员最重要的职能。
- 为了取的良好的空间- 时间折中,开发队伍需要得到特定的某种语言或机型的编程技能培训,特别是在使用新语言或者新机器时。
- 编程需要技术积累,每个项目需要自己的标准组件库。
- 精炼,充分和快速的程序往往是战略性突破的结果,而不仅仅是技巧上的提高。
- 这种突破常常是一种新型算法。
提纲挈领
- 在一片文件的汪洋中,少数文档成为了关键的枢纽,每个项目管理的工作都围绕着他们运转。
- 对于计算机硬件开发项目,关键文档是目标,手册,进度,预算,组织结构图,空间分配以及机器本身的报价,预测和价格。
- 对文档进行规范化。
- 项目经理的基本职责是使每个人都向着相同的方向进行。
- 项目经历的主要日常工作是沟通,而不是做出决定,文档使各项计划和决策在整个团队范围内得到交流。
未雨绸缪
- 第一个开发的系统对于大多数项目并合用。它可能太慢,太大,而且难以使用,或者三者兼而有之。
- 系统的丢弃和重新设计可以一步完成,也可以一块块地实现,但这是必须完成的步骤。
- 开发人员交付的是用户满意陈谷,而不仅仅是实际的产品。
- 用户的实际需要和用户感觉会随着程序的构建,测试和使用而变化。
- 软件产品易于掌握的特性和不可见性,导致它的构建人员面临着永恒的需求变更。
- 目标上的一些正常变化无可避免,事先为他们做准备总比假设他们不会出现要好的多。
- 高级语言的使用,编译时操作,通过引用的声明整合和自文档技术能减少变更引起的错误。
- 程序员不愿意为设计书写闻到那股,不仅仅是因为惰性,更多的是源于设计人员的踌躇 - 要为自己尝试性的设计决策进行辩解。
- 为变更组建团队比为变更进行设计更加困难。
- 只要管理人员和技术人才的天赋允许,老板必须对他们的能力培养给予极大的关注,使管理人员和技术人才具有互换性,特别是希望在技术和管理角色之间自由地分配人手的时候。
- 对于一个广泛使用的程序,其维护总成本通常是开发成本的40%或更多。
- 维护成本受用户数目的影响。用户越多,所发现的错误也越多。
- 缺陷修复总会以20%-50%的几率引入新的bug。
- 每次修复之后,必须重新运行先前所有的测试用例,确保系统不会以更隐蔽的方式被破坏。
- 所有修改都倾向与破坏系统的架构,增加了系统的混乱程度。即使是最熟练的软件维护工作,也只是延缓了系统退化到不可修复的混乱状态的进程,以致必须要重新进行设计。
干将莫邪
- 抛开理论不谈,一次分配给某个小组的连续的目标时间快被证明是最好的安排方法,比不同小组的穿插使用更为有效。
- 主程序库应划分为 1 一系列独立的私有开发库 2 正处在系统测试下的系统集成子库 3 发布版本。正式的分离和进度提供了控制。
- 高级语言不仅提高了生产率,还改进了调试,bug更少,而且更容易寻找。
整体部分
- 许许多多的失败完全源于那些产品未精确定义的地方。
- 有时必须回退,推翻顶层设计,重新开始。
- 系统调试所花费的时间会比预料的更长。
- 系统调试的困难程度证明了需要一种完备系统化和可计划的方法。
- 开发大量的辅助调试平台和测试代码是很值得的,代码量甚至可能有测试对象的一半。
- 必须有人对变更和版本进行控制和文档化。
祸起萧墙
- 一天一天的进度落后比起重大灾难更难以识别,更不容易防范和更加难以拟补。
- 李成碧必须是具体的,特定的和可度量的事件,能进行 清晰的定义。
- 慢性进度偏离是士气杀手。
- 进取对于杰出的软件开发团队是不可缺乏的必要品德。
- PERT饿准备工作是PERT图使用中最有价值的部分。
- 第一份PERT图总是很恐怖。
- 每个老板同时需要采取行动的异常信息以及用来进行分析和早期预警的状态数据。
- 状态的获取是困难的,因为下属经理有充分的理由不提供信息共享。
- 老板的不良反应肯定会对信息的完全公开造成压制,相反,仔细区分状态报告,毫无惊慌地接收报告,决不越俎代庖,将能鼓励诚实的汇报。
另外一面
- 对于软件编程产品来说,程序向用户所呈现的面貌- 闻到那股,与提供给机器识别的内容同样重要。
- 即使是完全开发给自己使用的程序,描述性文字也是必须的,因为他们会被用户-作者所遗忘。
- 培训和管理人员基本上没有向编程人员成功地灌输对待闻到那股的积极态度 - 文档能在整个生命周期对客服懒惰和进度的压力起促进和激励作用。
- 大多数闻到那股只提供了很少的总结性内容。必须放慢脚步,稳妥地进行。
- 流程图是被吹捧的最过分的一种程序文档。
- 如果这样,很少有程序需要一页纸以上的流程图
- 程序员改人员所使用的文档中,除了描述事件如何,还应阐述它为什么那样,对于加深理解,目的是非常关键的,即使是高级语言的语法,也不能表达目的。
- 软件系统可能是人类创造中最错综复杂的事物。
- 软件工程的焦油坑在将来很长一段事件内仍然会使人们举步维艰,无法自拔。
- 从程序到编程产品至少是开发程序时间的三倍,需要有完备的文档,每个人都可加已使用,修复和扩展。
职业的乐趣
- 这种快乐是一种创造事物的纯粹快乐,特别是自己进行设计。
- 其次,这种快乐来自于开发对他人有用的东西。内心深处。我们期望我们的劳动成果能够被他人使用,并能对他们有所帮助。
- 第三,快乐来自于整体过程体现出的一股强大的而魅力,并收到了预期的效果。
- 持续学习的快乐,来自于这项工作的非重复特性,人们所面临的问题总有这样那样的不同,因而解决问题的人可以从中学习新的事物。
- 程序员就像诗人一样,几乎仅仅在单纯的思考中工作。程序员凭空地运用自己的想象,来建造自己的“城堡”。
职业的苦恼
- 苦恼来自于追求完美。我认为,学习编程最困难的部分,是将做事的方式向追求完美的方向调整。
- 其次,苦恼来自由他人来设定目标,供给资源和提供信息。
- 对于系统编程人员而言,对其他人的依赖是一件非常痛苦的事情。他依靠其他人的程序,而这些程序往往设计的并不合理,实现出拙劣,发布不完成整,文档记录很糟糕。
- 寻找琐碎的bug是一项重复行的劳动,往往枯燥沉闷。
人月
- 用人月作为衡量工作的规模是一个危险和带有欺骗性的神话。
- 人数和时间的互换仅仅适用于,他们之间不需要相互交流。
- 沟通所增加的负担:培训和相互交流。在一个不可分解的任务时,人数的增加反而会使得项目时间增加。
- 软件开发本质是一项系统工作 - 错综复杂关系下的一种实践,沟通,交流的工作量非常大,添加更多的人手,实际上延长了而不是缩短了时间进度。
系统测试
- 软件任务的进度安排。1/3计划,1/6编码,1/4构件测试和早期系统测试,1/4系统测试,所有的构件完成。
- 不为系统测试安排足够的时间,简直就是一场灾难。
进度灾难
- 向进度落后的项目增加人手,只会使得进度更加落后。
- 项目的时间依赖于顺序上的限制
- 人员的最大数量依赖于独立子任务的数量
问题
- 一流人才组成的小型,精干的队伍,而不是那些几百人大型团队,这里的“人”当然暗指平庸的程序员
- 优秀的程序员和较差的程序员之间生产率的差异,实际测量出的差异领人吃惊,最好的和最差的表现在生产率上平局能为10:1,在编程速度和空间上具有5:1的惊人差异
- 简言之,20000美元/年的程序员的生产率可能是10000美元/年的程序员10倍。
- 实际上,绝大多数大型编程系统的经验显示出,一拥而上的开发方法是高成本的,速度缓慢的,低效的,开发出的是无法在概念上集成的产品。
组织架构
- 我认为产品负责任作为管理者是更合适的安排。
控制规模
- 更深刻的教训体现在以上的经验中,项目规模本身很大,缺乏管理和沟通,以至于每个团队成员认为自己是争取小红花的学生,而不是勾践系统软件产品的人员。为了满足目标,每个人都在局部优化自己的程序,很少会有人听再来,考虑一下对客户的整体影响。
文档
- 技术,周边组织机构,行业传统等若干因素凑在一起,定义了项目必须准备的一些文书供祖宗。对于一个刚从技术人员中任命的项目经历来说,这减脂是一件彻头彻尾,令人生厌的事情。
- 慢慢地,他逐渐认识到这些文档的某些部分包含和表达了一些管理 方面的工作。每分文档的准备工作是集中考虑,并使各种讨论意见明细化的主要时刻。如果不这样,项目往往会处于无休止的混乱状态中,文档的跟踪维护是项目监督和预警的机制。文档本身可以作为检查列表,状态控制,也可以作为回报的数据基础。
未雨绸缪
- 对于大多数项目,第一个开发的系统并不合用。它可能太慢,太大,而且难以使用,或者三者兼而有之。要解决所有的问题,除了重新开始以外,没有其他的办法。即开始一个更灵巧或更好的系统,系统的丢弃和重新设计可以一步完成,也可以一块块地实现,所有大型系统的经验都显示,这是必须完成的步骤。而且,新的系统概念或新技术会不断出现,必须构建一个用来抛弃的系统,因为即使是最优秀的项目经历,也不能无所不知地在最开始解决这些问题。
- 我从不建议顾客所有的目标和需求的变更必须,能够或者应该整合到设计中,项目开始时建立的基准,肯定会随着开发的进行越来越高,甚至开发不出任何产品。
- 程序员不愿意为设计书写文档的原因,不仅仅是因为惰性或者时间的压力。相反,设计人员通常不愿意提交尝试行的设计决策,再为他们进行辩解。“通过设计文档化,设计人员讲自己暴露在每个人的批评之吓,他必须能够为他书写的一切进行辩护。如果团队加固因此收到任何形式的威胁,则没有任何东西会被文档化,除非架构是完全受到保护的。”
- 对于一个广泛使用的程序,其维护总成本通常是开发成本的40%或更多。令人吃惊的是,该成本受用户数目的影响很大。用户越多,所发现的错误就越多。
- 一个有趣的循环,上一个版本中被发现和修复的bug,在新的版本中仍会出现,新版本中的新功能会产生新的bug。解决了这些问题以后,程序会正常运行几个月,接着,错误率会重新攀升,这是因为用户的使用达到了新的熟练水平,开始运用新的功能,这种高强度的考验查处了新功能中很多不易察觉的问题。
- 用在修复原有设计上瑕疵的工作量越来越少,而早期维护活动本身所引起的漏洞的修复工作越来越多,随着时间的推移,系统变得越来越无序,修复工作迟早会失去根基。每一步前进都伴随着一步后退,尽管系统在理论上一直可用,但实际上,整个系统已经面目全非。
- 系统软件开发是减少混乱度的过程,所以它本身是处于亚稳态的,软件维护是提高混乱度的过程。即使是熟练的软件维护工作,也只是放缓了系统退化到非稳态的过程。此时就需要大规模重构。
工具
- 就工具而言,即使是现在,很多软件项目仍然像经营一家五金店。每个骨干人员都仔细地保管自己工作生涯的一套工具集,这些工具成为个人技能的直观证明,正式如此,每个编程人员也保留着编辑器,排序,内存信息转储和磁盘空间使用程序的巩固。
- 所以在前面关于软件开发队伍的讨论中,我建议为每个团队配备一个工具管理人员。这个角色管理所有通用工具,能知道他的客户和老板如何使用工具。同时,他还能编制老板需要的专业工具。
文档
- 面对那些文档“简约”的程序,我们中的大多数人都不免曾经暗骂那些远在他方的匿名作者。因为,一些视图向新人慢慢地灌输文档的重要性,旨在延长软件的生命期,克服惰性和进度的压力。但是,很多次尝试都失败了,我想可能是由于我们使用了错误的方法。
- 每个用户都需要一段对程序进行描述的文字。可是太多数文档只提供了很少的总结性内容,无法达到用户要求,就像是描绘了树木,形容了树皮和树叶,但确没有一幅森林的图案,为了得到一份有用的文字描述,就必须放慢脚步,稳妥前行
- 流程图是被吹捧的最过分的一种程序文档,事实上,很多程序甚至不需要流程图,很少有程序需要一页纸以上的流程图。
- 现实中,我从来没有看过一个有经验的编程人员,在开始编写程序之前,会例行公事地绘制详尽的流程图。在一些要求流程图的组织中,流程图总是事后才补上的。
如何培养杰出的设计人员
- 尽可能早地,有系统地识别顶级的设计人员,最好的通常不是最有经验的人员
- 为设计人员指派一位职业导师,负责他们技术方面的成长,仔细地为他们规划职业生涯。
- 为每个方面指定和维护一份职业计划,包括与设计大师的,经过仔细挑选的学习过程,正式的高级教育和短期的课程,所有这些穿插在设计和技术领导能力的培养安排中。
- 为成长中的设计人员提供交流和激励的机会。
面向对象
- 因为OO和各种复杂语言的联系已经很紧密,人们并没有被告诉OO是一种设计方式,并xang他们讲授设计方法和原理,大家只是被告知OO是一种设计方法,并向他们讲授设计方法和原理,大家只是被告知OO是这一种特殊工具,而我们可以用任何工具写出优质或低劣的代码。除非我们给人们讲解无任何设计,否则语言所起的所用非常小,结果人们使用这种语言做出不好的设计,没有从中获得多少价值。而一旦获得的价值太少,它就不会流行。
- 面相对象技术包含了很多方法学上的进步,OO的前期投入很多 ,主要是重新培训程序员用很新的方法进行思考。面相对象在整个开发周期中得到了应用,但是真正的获益只有在后续开发,拓展和维护活动中才能体现出来。Coggin说:面相对象技术不会加快首次或第二次的开发,产品族群中第五个项目的开发将会异乎寻常的循序。
- 为了预期中的,但有写不确定的收益,冒着风险投入资金是投资人每天在做的事情。不过,在很多软件工资,这需要真正的管理勇气,一种比技术竞争力或者优秀管理能力更少有的精神。我认为极度的前期投入和收益的推后是使OO技术应用迟缓的最大原因。
重用的情况
- 大多数的丰富经验的程序员都拥有自己的私人开发库,使用大约30%的重用代码来开发软件。公司级别的重用能提供70%的重用代码量,它需要特殊的开发库和管理支持。公司级别的重用代码意味着需要对项目中的变更进行统计和度量,从而提高重用的可信程度。
IRIS RAD Studio 是一个低代码解决方案,使开发更简单。任何人都可以基于一个简单的类定义乃至一个CSV文件来创建CRUD..
https://openexchange.intersystems.com/package/iris-rad-studio
GSP Gateway 在linux中,通过 Apache 响应 Web 请求;在windows中,通过 IIS Web Server响应 Web 请求。但是,应用中发现当Apache崩溃时,镜像无法自动切换,从而影响到医院业务,关于此类情况,请求各位有没有对应解决方案?
第十三章 使用动态SQL(五)
从结果集中返回特定的值
要从查询结果集中返回特定的值,必须一次一行遍历结果集。
要遍历结果集,请使用%Next()实例方法。
(对于单一值,结果对象中没有行,因此%Next()返回0,而不是错误。)
然后,可以使用%Print()方法显示整个当前行的结果,或者检索当前行的指定列的值。
%Next()方法获取查询结果中下一行的数据,并将该数据放入结果集对象的data属性中。
%Next()返回1,表示它位于查询结果中的某一行上。
%Next()返回0,表示它位于最后一行(结果集的末尾)之后。
每次调用%Next()返回1个增量%ROWCOUNT;
如果游标定位在最后一行之后(%Next()返回0),%ROWCOUNT表示结果集中的行数。
如果SELECT查询只返回聚合函数,每个%Next()设置%ROWCOUNT=1。
第一个%Next()返回1并设置%SQLCODE=0和%ROWCOUNT=1,即使表中没有数据;
任何随后的%Next()返回0,并设置%SQLCODE=100和%ROWCOUNT=1。
从结果集中获取一行后,可以使用以下任何一种方式显示该行的数据:
rset.%Print()返回查询结果集中当前行的所有数据值。rset.%GetRow()和rset.getrows()以编码列表结构的元素形式从查询结果集中返回一行的数据值。rset.name按查询结果集中的属性名称、字段名称、别名属性名称或别名字段名称返回数据值。rset.%Get("fieldname")通过字段名或别名从查询结果集中或存储的查询返回一个数据值。rset.%GetData(n)按列号从查询结果集中或存储的查询中返回一个数据值。
%Print()方法
%Print()实例方法从结果集中检索当前记录。默认情况下,%Print()在数据字段值之间插入空白空格分隔符。
%Print()不会在记录的第一个字段值之前或最后一个字段值之后插入空白;
它在记录的末尾发出一个行返回。
如果数据字段值已经包含空格,则将该字段值括在引号中,以将其与分隔符区分开来。
例如,如果%Print()返回城市名称,它将按如下方式返回它们: "New York" Boston Atlanta "Los Angeles" "Salt Lake City" Washington.
引用包含分隔符作为数据值一部分的字段值,即使从未使用过%Print()分隔符;
例如,如果结果集中只有一个字段。
可以选择指定%Print()参数,该参数提供在字段值之间放置的另一个定界符。指定其他定界符将覆盖包含空格的数据字符串的引用。此%Print()分隔符可以是一个或多个字符。它指定为带引号的字符串。通常,%Print()分隔符最好是在结果集数据中找不到的字符或字符串。但是,如果结果集中的字段值包含%Print()分隔符(或字符串),则该字段值将用引号引起来,以将其与分隔符区分开。
如果结果集中的字段值包含换行符,则该字段值将以引号引起来。
以下ObjectScript示例使用%Print()遍历查询结果集以显示每个结果集记录,并使用 "^|^" 定界符分隔值。请注意%Print()如何显示FavoriteColors字段中的数据,该字段是元素的编码列表:
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint()
ClassMethod ROWCOUNTPrint()
{
SET q1="SELECT TOP 5 Name,DOB,Home_State,FavoriteColors "
SET q2="FROM Sample.Person WHERE FavoriteColors IS NOT NULL"
SET myquery = q1_q2
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
DO rset.%Print("^|^")
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
DHC-APP> d ##class(PHA.TEST.SQL).ROWCOUNTPrint()
Row count 1
yaoxin^|^54536^|^WI^|^$lb("Red","Orange","Yellow")
Row count 2
姚鑫^|^^|^^|^$lb("Red","Orange","Yellow","Green")
Row count 3
姚鑫^|^^|^^|^$lb("Red","Orange","Yellow","Green","Green")
Row count 4
Isaacs,Roberta Z.^|^^|^^|^$lb("Red","Orange","Yellow","Green","Yellow")
Row count 5
Chadwick,Zelda S.^|^50066^|^WI^|^$lb("White")
End of data
Total row count=5
下面的示例显示如何将包含定界符的字段值括在引号中。在此示例中,大写字母A用作字段定界符;因此,任何包含大写字母A的字段值(名称,街道地址或州缩写)都将以引号引起来。
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint2()
ClassMethod ROWCOUNTPrint2()
{
SET myquery = "SELECT TOP 25 Name,Home_Street,Home_State,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
DO rset.%Print("A")
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
DHC-APP>d ##class(PHA.TEST.SQL).ROWCOUNTPrint2()
yaoxinA889 Clinton DriveAWIA30
xiaoliAAA
姚鑫AAA7
姚鑫AAA7
姚鑫AAA43
姚鑫AAA
姚鑫AAA
Isaacs,Roberta Z.AAA
Chadwick,Zelda S.A9889 Clinton DriveAWIA43
Fives,James D.A2091 Washington BlvdANDA88
Vonnegut,Jose P.A3660 Main PlaceAWIA47
Chadbourne,Barb B.A1174 Second StreetA"VA"A93
"Quigley,Barb A."A"6501 Ash Avenue"AKYA73
%GetRow()和%GetRows()方法
%GetRow()实例方法从结果集中检索当前行(记录),作为字段值元素的编码列表:
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint3()
ClassMethod ROWCOUNTPrint3()
{
SET myquery = "SELECT TOP 17 %ID,Name,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
FOR {
SET x=rset.%GetRow(.row,.status)
IF x=1 {
WRITE $LISTTOSTRING(row," | "),!
} ELSE {
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
RETURN
}
}
}
%GetRows()实例方法从结果集中检索指定大小的一组行(记录)。每行作为字段值元素的编码列表返回。
下面的示例返回结果集中的第1、6和11行。在此示例中,%GetRows()第一个参数(5)指定%GetRows()应该检索五行的连续组。如果成功检索到一组五行,%GetRows()将返回1。 .rows参数通过引用传递这五行的下标数组,因此,rows(1)返回每五组中的第一行:第1、6和11行。指定rows(2)将返回第2、7行和12。
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint4()
ClassMethod ROWCOUNTPrint4()
{
SET myquery = "SELECT TOP 17 %ID,Name,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
FOR {
SET x=rset.%GetRows(5,.rows,.status)
IF x=1 {
WRITE $LISTTOSTRING(rows(1)," | "),!
} ELSE {
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
RETURN
}
}
}
可以使用ZWRITE rows命令返回检索到的数组中的所有下标,而不是按下标检索单个行。请注意,上面的示例ZWRITE行不会返回结果集中的第16行和第17行,因为在检索到最后一组五行之后,这些行是余数。
rset.name属性
当InterSystems IRIS生成结果集时,它将创建一个结果集类,其中包含一个与该结果集中的每个字段名称和字段名称别名相对应的唯一属性。
可以使用rset.name属性按属性名称,字段名称,属性名称别名或字段名称别名返回数据值。
- 属性名称:如果未定义字段别名,则将字段属性名称指定为
rset.PropName。结果集字段属性名称取自表定义类中的相应属性名称。 - 字段名称:如果没有定义字段别名,请将字段名称(或属性名称)指定为
rset。“fieldname”。这是表定义中指定的SQLFIELDNAME。 Intersystems Iris使用此字段名称来查找相应的属性名称。在许多情况下,属性名称和字段名称(SQLFieldName)是相同的。 - 别名属性名称:如果定义了字段别名,则将别名属性名称指定为
rset.AliasProp。别名属性名称是根据SELECT语句中的列名称别名生成的。不能为具有已定义别名的字段指定字段属性名称。 - 别名:如果定义了字段别名,则将此别名(或别名属性名称)指定为
rset。“ alias”。这是SELECT语句中的列名别名。您不能为具有已定义别名的字段指定字段名称。 - 集合,表达式或子查询:InterSystems IRIS为这些选择项分配一个字段名称
Aggregate_n,Expression_n或Subquery_n(其中整数n对应于查询中指定的选择项列表的顺序)。可以使用字段名称(rset。“ SubQuery_7”不区分大小写),相应的属性名称(rset.Subquery7区分大小写)或用户定义的字段名称别名来检索这些select-item值。也可以只使用rset。%GetData(n)指定选择项的序列号。
指定属性名称时,必须使用正确的字母大小写;指定字段名称时,不需要正确的字母大小写。
使用属性名称对rset.name的调用具有以下后果:
- 字母大小写:属性名称区分大小写。字段名称不区分大小写。 Dynamic SQL可以自动解决指定字段或别名与相应属性名称之间的字母大小写差异。但是,解决字母大小写需要时间。为了最大限度地提高性能,应该指定属性名称或别名的确切字母大小写。
- 非字母数字字符:属性名称只能包含字母数字字符(起始的
%字符除外)。如果相应的SQL字段名称或字段名称别名包含非字母数字字符(例如Last_Name),则可以执行以下任一操作:- 指定用引号分隔的字段名称。例如,
rset。“ Last_Name”)。分隔符的这种使用不需要启用分隔符。执行大写字母解析。 - 指定相应的属性名称,以消除非字母数字字符。例如,
rset.LastName(或rset。“ LastName”)。必须为属性名称指定正确的字母大小写。 %属性名称:通常,以%字符开头的属性名称保留供系统使用。如果字段属性名称或别名以%字符开头,并且该名称与系统定义的属性冲突,则返回系统定义的属性。例如,对于SELECT Notes AS%Message,调用rset。%Message将不返回Notes字段值。它返回为语句结果类定义的%Message属性。可以使用rset。%Get(“%Message”)返回字段值。- 列别名:如果指定了别名,则Dynamic SQL始终匹配该别名,而不匹配字段名称或字段属性名称。例如,对于
SELECT Name AS Last_Name,只能使用rset.LastName或rset。“ Last_Name”来检索数据,而不能使用rset.Name。 - 重复名称:如果名称解析为相同的属性名称,则它们是重复的。重复名称可以是对表中同一字段的多个引用,对表中不同字段的别名引用或对不同表中字段的引用。例如,
SELECT p.DOB,e.DOB指定两个重复的名称,即使这些名称引用了不同表中的字段。
- 指定用引号分隔的字段名称。例如,
如果SELECT语句包含相同字段名称或字段名称别名的多个实例,则rset.propname或rset。“fieldname”始终返回SELECT语句中指定的第一个。例如,对于SELECT C.NAME,P.NAME来自Sample.person as p,sample.company使用rset.name检索公司名称字段数据;选择C.Name,P.Name作为来自Sample.person的名称,As P,Sample.com本文使用RSET。“name”还检索公司名称字段数据。如果查询中存在重复的名称字段,则字段名称(名称)的最后一个字符由字符(或字符)替换为创建唯一属性名称。因此,查询中的重复名称字段名称具有相应的唯一属性名称,以NAM0(第一个重复)通过NAM9开始,并通过NAMZ继续大写字母NAMA。
对于使用%Prepare()准备的用户指定的查询,可以单独使用属性名称。对于使用%PrepareClassQuery()准备的存储查询,必须使用%Get(“ fieldname”)方法。
下面的示例返回由属性名称指定的三个字段的值:两个属性值分别由属性名称和第三个属性值由别名属性名称。在这些情况下,指定的属性名称与字段名称或字段别名相同:
/// d ##class(PHA.TEST.SQL).PropSQL()
ClassMethod PropSQL()
{
SET myquery = "SELECT TOP 5 Name,DOB AS bdate,FavoriteColors FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New(1)
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
WRITE rset.Name
WRITE " prefers ",rset.FavoriteColors
WRITE " birth date ",rset.bdate,!!
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
DHC-APP>d ##class(PHA.TEST.SQL).PropSQL()
Row count 1
yaoxin prefers Red,Orange,Yellow birth date 1990-04-25
Row count 2
xiaoli prefers birth date
Row count 3
姚鑫 prefers birth date 2014-01-02
Row count 4
姚鑫 prefers birth date 2014-01-02
Row count 5
姚鑫 prefers birth date 1978-01-28
End of data
Total row count=5
在上面的示例中,返回的字段之一是FavoriteColors字段,其中包含%List数据。若要显示此数据,%New(1)类方法将%SelectMode属性参数设置为1(ODBC),从而导致该程序将%List数据显示为逗号分隔的字符串,并以ODBC格式显示出生日期:
下面的示例返回Home_State字段。因为属性名称不能包含下划线字符,所以本示例指定用引号(“ Home_State”)分隔的字段名称(SqlFieldName)。还可以指定不带引号的相应生成的属性名称(HomeState)。请注意,定界字段名称(“ Home_State”)不区分大小写,但是生成的属性名称(HomeState)是区分大小写的:
/// d ##class(PHA.TEST.SQL).PropSQL1()
ClassMethod PropSQL1()
{
SET myquery = "SELECT TOP 5 Name,Home_State FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New(2)
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
WRITE rset.Name
WRITE " lives in ",rset."Home_State",!
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
DHC-APP>d ##class(PHA.TEST.SQL).PropSQL1()
Row count 1
yaoxin lives in WI
Row count 2
xiaoli lives in
Row count 3
姚鑫 lives in
Row count 4
姚鑫 lives in
Row count 5
姚鑫 lives in
End of data
Total row count=5
第二十一章 导入和导出SQL数据
在InterSystems IRIS®Data Platform Management Portal中,有用于导入和导出数据的工具:
- 从文本文件导入数据
- 将数据导出到文本文件
这些工具使用动态SQL,这意味着查询是在运行时准备和执行的。可以导入或导出的行的最大大小为3,641,144个字符。
还可以使用%SQL.Import.Mgr类导入数据,使用%SQL.Export.Mgr类导出数据。
从文本文件导入数据
可以将数据从文本文件导入到合适的InterSystems IRIS类中。执行此操作时,系统将在表中为该类创建并保存新行。该类必须已经存在并且必须编译。要将数据导入到此类中,请执行以下操作:
从管理门户中选择系统资源管理器,然后选择SQL。使用页面顶部的切换选项选择一个命名空间;这将显示可用命名空间的列表。
在页面顶部,单击向导下拉列表,然后选择数据导入。
在向导的第一页上,从指定外部文件的位置开始。对于导入文件所在的位置,请单击要使用的服务器的名称。
然后输入文件的完整路径和文件名。
对于选择架构名称,单击要向其中导入数据的InterSystems IRIS包。
对于选择表名,单击将包含新创建的对象的类。
然后单击下一步。
在向导的第二页上,单击将包含导入数据的列。
然后单击下一步。
在向导的第三页上,描述外部文件的格式。
- 有关用什么分隔符分隔您的列?,请单击与此文件中的分隔符对应的选项。
- 单击第一行是否包含列标题?如果文件的第一行不包含数据,则选中此复选框。
- 对于字符串引号,单击指示此文件用于开始和结束字符串数据的引号分隔符字符的选项。
- 对于日期格式,请单击指示此文件中日期格式的选项。
- 对于时间格式,请单击指示此文件中的时间格式的选项。
- 对于时间戳格式,请单击指示此文件中的时间戳格式的选项。
- 单击禁用验证?如果不希望向导在导入时验证数据,请选中此复选框。
- 使用%SortBegin/%SortEnd?如果不希望向导在导入期间重新生成索引,请选中此复选框。如果选中延迟索引生成,向导将在将导入的数据插入到表中之前为该类调用%SortBegin方法。导入完成后,向导将调用%SortEnd方法。不执行任何验证(与使用%NOCHECK的INSERT相同)。这是因为当使用%SortBegin/%SortEnd时,在SQL INSERT期间不能检查索引的唯一性。如果选中延迟索引构建,则假定导入的数据有效,不会检查其有效性。
- 或者,单击“预览数据”以查看向导将如何分析此文件中的数据。
- 单击“下一步”。
- 检查条目,然后单击Finish。向导将显示“数据导入结果”对话框。
- 单击关闭。或者单击给定的链接以查看后台任务页面。
在任何一种情况下,向导都会启动一个后台任务来完成工作。
将数据导出到文本文件
可以将给定类的数据导出到文本文件。为此:
从管理门户中选择系统资源管理器,然后选择SQL。使用页面顶部的切换选项选择一个命名空间;这将显示可用命名空间的列表。
在页面顶部,单击向导下拉列表,然后选择数据导出。
在向导的第一页上:
- 输入要创建以保存导出数据的文件的完整路径和文件名。
- 从下拉列表中,选择要从中导出数据的命名空间、方案名和表名。
- 或者,从Charset下拉列表中选择一个字符集;默认值为Device Default。
- 然后单击下一步。
在向导的第二页上,选择要导出的列。然后单击下一步。
在向导的第三页上,描述外部文件的格式。
- 有关用什么分隔符分隔的列?,请单击与此文件中的分隔符对应的选项。
- 单击导出列标题?如果要将列标题导出为文件的第一行,请选中此复选框。
- 对于字符串引号,单击一个选项以指示如何开始和结束此文件中的字符串数据。
- 对于日期格式,单击一个选项以指示要在此文件中使用的日期格式。
- (可选)单击“预览数据”以查看结果的外观。然后单击下一步。
检查条目,然后单击Finish。该向导将显示“数据输出结果”对话框。
单击关闭。或单击给定的链接以查看后台任务页面。
在任何一种情况下,向导都启动后台任务来完成工作。
如果看了前一篇InterSystems IRIS医疗行业版创建FHIR服务器,应该您已经搭建好了FHIR服务器和FHIR资源仓库。除了使用FHIR REST API来操作这个FHIR服务器,您还可以更直观地看看它的价值 - 使用SMART on FHIR应用。这次,基于上次建好的FHIR服务器,我们用10分钟把一个SMART on FHIR运行起来。
SMART on FHIR背景
SMART是Substitutable Medical Applications and Reusable Technology的缩写,它的目标是创建可以被替换、可以复用的医疗应用,简单说就是希望医疗应用可以像我们的手机应用一样:不喜欢当前的天气应用,那么就换一个。SMART,这个起于2011年的哈佛和波士顿儿童医院的合作项目,在2013年注意到并快速采用了FHIR,成就了今天的SMART on FHIR。
InterSystems IRIS,IRIS for Health和IRIS Studio的2020.4版本现已正式发布。
InterSystems IRIS Data Platform 2020.4使开发、部署和管理增强型应用和业务流程变得更加容易,从而弥合了数据和应用孤岛。它具有许多新功能,包括
增强了应用程序和接口开发人员的能力,包括:
- 支持Java SE 11 LTS,在使用Oracle OpenJDK和AdoptOpenJDK时均可支持
- 支持JDBC的连接池
- 分段式虚拟文档路由规则中新的 "foreach "组件
增强了数据库和系统管理员的能力,包括:
- ICM现在支持部署系统警报和监测(SAM)和InterSystems API Manager(IAM)
- 对常见管理任务的SQL语法的扩展
- 简化InterSystems报表的部署
InterSystems IRIS for Health 2020.4包含了InterSystems IRIS 2020.4的所有增强功能。此外,这个版本还包
- 增强对FHIR的支持,包括对FHIR配置文件的支持
- 支持RMD IHE 的Profile
- HL7迁移工具中的DataGate支持
关于这些功能的更多细节可以在产品文档中找到:
2021年4月18日,Caché 系统运维培训线上实操课,此次培训的主题包括, Intersystems Caché 架构,Intersystems Caché 备份与恢复,Intersystems Caché 高可用与数据库镜像,Intersystems Caché 安全,Intersystems Caché 监控和性能采集。 欢迎大家报名参加!

亲爱的开发者们!
现在你可以在InterSystems开发者社区找工作啦!在开发者社区发帖,你可以为自己找一份心仪的工作,也可以为你的公司寻找合适的人才!

那么,具体怎么操作呢?
第十九章 存储和使用流数据(BLOBs和CLOBs)
Intersystems SQL支持将流数据存储为Intersystems Iris ®DataPlatform数据库中的 BLOBs(二进制大对象)或 CLOBs(字符大对象)的功能。
流字段和SQL
Intersystems SQL支持两种流字段:
- 字符流
Character streams,用于大量文本。 - 二进制流
Binary streams,用于图像,音频或视频。
BLOBs and CLOBs
Intersystems SQL支持将BLOBs(二进制大对象)和CLOBs(字符大对象)存储为流对象的功能。 BLOBs用于存储二进制信息,例如图像,而CLOBs用于存储字符信息。 BLOBs和CLOBs可以存储多达4千兆字节的数据(JDBC和ODBC规范所强加的限制)。
在各种方面,诸多方面的操作在通过ODBC或JDBC客户端访问时处理字符编码转换(例如Unicode到多字节):BLOB中的数据被视为二进制数据,从未转换为二进制数据另一个编码,而CLOB中的数据被视为字符数据并根据需要转换。
如果二进制流文件(BLOB)包含单个非打印字符$CHAR(0),则被认为是空二进制流。它相当于""空二进制流程值:它存在(不是null),但长度为0。
定义流数据字段
Intersystems SQL支持流字段的各种数据类型名称。这些Intersystems数据类型名称是与以下内容对应的同义词:
- 字符流:数据类型
LONGVARCHAR,映射到%stream.globalcharacter类和ODBC / JDBC数据类型-1。 - 字符流:数据类型
LONGVARBINARY,映射到%Stream.GlobalBinary类和ODBC / JDBC数据类型-4。
某些Intersystems流数据类型允许指定数据精度值。此值是no-op,对流数据的允许大小没有影响。提供它以允许用户记录预期的未来数据大小。
以下示例定义包含两个流字段的表:
CREATE TABLE Sample.MyTable (
Name VARCHAR(50) NOT NULL,
Notes LONGVARCHAR,
Photo LONGVARBINARY)
分片表不能包含流数据类型字段。
流字段约束
Stream字段的定义符合以下字段数据约束:
流字段可以定义为 NOT NULL。
流字段可以占用默认值,更新值或计算码值。
流字段不能定义为唯一,主键字段或idkey。试图这样做导致SQLCode -400致命错误,其中%MSG如下: ERROR #5414: Invalid index attribute: Sample.MyTable::MYTABLEUNIQUE2::Notes, Stream property is not allowed in a unique/primary key/idkey index > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.
无法使用指定的COLLATE 值定义流字段。试图这样做导致SQLCode -400致命错误,其中%MSG如下: ERROR #5480: Property parameter not declared: Sample.MyTable:Photo:COLLATION > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.
将数据插入流数据字段
将数据插入流字段有三种方法:
%Stream.Globalcharacter字段:可以直接插入字符流数据。例如,
INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred','These are extensive notes about Fred')

Class Sample.MyTable Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {yx}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = MyTable ]
{
Property Name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property Notes As %Stream.GlobalCharacter [ SqlColumnNumber = 3 ];
Property Photo As %Stream.GlobalBinary [ SqlColumnNumber = 4 ];
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
<Data name="MyTableDefaultData">
<Value name="1">
<Value>Name</Value>
</Value>
<Value name="2">
<Value>Notes</Value>
</Value>
<Value name="3">
<Value>Photo</Value>
</Value>
</Data>
<DataLocation>^Sample.MyTableD</DataLocation>
<DefaultData>MyTableDefaultData</DefaultData>
<IdFunction>sequence</IdFunction>
<IdLocation>^Sample.MyTableD</IdLocation>
<IndexLocation>^Sample.MyTableI</IndexLocation>
<StreamLocation>^Sample.MyTableS</StreamLocation>
<Type>%Library.CacheStorage</Type>
}
}
%stream.globalcharacter和%stream.globalbinary字段:可以使用oref插入流数据。可以使用Write()方法将字符串附加到字符流,或者写入的方法,以将具有行终结器的字符串附加到字符流。默认情况下,行终结器是$CHAR(13,10)(回车返回/线路);可以通过设置LineTerminator属性来更改行终结器。在以下示例中,示例的第一部分创建由两个字符串和其终端组组成的字符流,然后使用嵌入的SQL将其插入流字段。示例的第二部分返回字符流长度,并显示显示终结器的字符流数据:
/// d ##class(PHA.TEST.SQL).StreamField()
ClassMethod StreamField()
{
CreateAndInsertCharacterStream
SET gcoref=##class(%Stream.GlobalCharacter).%New()
DO gcoref.WriteLine("First Line")
DO gcoref.WriteLine("Second Line")
&sql(INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred',:gcoref))
IF SQLCODE<0 {
WRITE "SQLCODE ERROR:"_SQLCODE_" "_%msg QUIT
} ELSE {
WRITE "插入成功",!
}
DisplayTheCharacterStream
KILL ^CacheStream
WRITE gcoref.%Save(),!
ZWRITE ^CacheStream
}
DHC-APP>d ##class(PHA.TEST.SQL).StreamField()
插入成功
1
^CacheStream=1
^CacheStream(1)=1
^CacheStream(1,0)=25
^CacheStream(1,1)="First Line"_$c(13,10)_"Second Line"_$c(13,10)

%stream.globalcharacter和%stream.globalbinary字段:可以通过从文件读取它来插入流数据。例如,
/// d ##class(PHA.TEST.SQL).StreamField1()
ClassMethod StreamField1()
{
SET myf="E:\temp\game.jpg"
OPEN myf:("RF"):10
USE myf:0
READ x(1):10
&sql(INSERT INTO Sample.MyTable (Name,Photo) VALUES ('George',:x(1)))
IF SQLCODE<0 {
WRITE "SQLCODE ERROR:"_SQLCODE_" "_%msg QUIT
} ELSE {
WRITE "插入成功",!
}
CLOSE myf
}
DHC-APP>d ##class(PHA.TEST.SQL).StreamField1()
WRITE "插入成功",!
^
<WRITE>zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
WRITE "插入成功",!
^
<WRITE>zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
DHC-APP>

作为默认值或计算值插入的字符串数据以适合于流字段的格式存储。
查询流字段数据
选择流字段的查询选择项返回流对象的完全形成的OID(对象ID)值,如下例所示:
SELECT Name,Photo,Notes
FROM Sample.MyTable WHERE Photo IS NOT NULL

OID是一个 %List 格式化数据地址,如以下内容:$lb("1","%Stream.GlobalCharacter","^EW3K.Cn9X.S")。
OID的第一个元素是一个连续的正整数(从1开始),它被分配给每个插入到表中的流数据值。 例如,如果第1行插入流字段
Photo和Notes的值,则将它们赋值为1和2。 如果第2行插入了一个Notes值,则将该值赋给3。 如果用Photo和Notes的值插入第3行,则将它们赋值为4和5。 分配顺序是表定义中列出字段的顺序,而不是INSERT命令中指定字段的顺序。 默认情况下,使用单个整数序列,它对应于流位置全局计数器。 然而,一个表可能有多个流计数器,如下所述。更新操作不会改变初始整数值。
DELETE操作可以在整型序列中创建空白,但不会改变这些整型值。 使用DELETE删除所有记录不会重置此整数计数器。 如果所有表流字段都使用默认的StreamLocation值,则使用TRUNCATE TABLE删除所有记录将重置此整数计数器。 不能使用TRUNCATE表为嵌入式对象(%SerialObject)类重置流整数计数器。OID的第二个元素是流数据类型,可以是
%Stream.GlobalCharacter或%Stream.GlobalBinary。OID的第三个元素是一个全局变量。 默认情况下,它的名称是从与表对应的包名和持久类名生成的。 一个
“S”(用于流)被追加。- 如果表是使用SQL
CREATE TABLE命令创建的,这些包和持久化类名称将被散列为每个4个字符(例如,^EW3K.Cn9X.S)。 这个全局变量包含流数据插入计数器最近分配的值。 如果没有插入流字段数据,或者使用TRUNCATE TABLE删除所有表数据,那么这个全局变量是未定义的。 - 如果表是作为一个持久化类创建的,那么这些包和持久化类名不会被散列(例如
^Sample.MyTableS)。 默认情况下,这是StreamLocation存储关键字<StreamLocation>^Sample.MyTableS</StreamLocation>价值。
- 如果表是使用SQL
默认流位置是全局位置,如^Sample.MyTableS。此全局变量用于计算插入到没有自定义位置的所有流属性(字段)的次数。例如,如果Sample.MyTable中的所有流属性都使用默认流位置,则在Sample.MyTable的流属性中插入了10个流数据值时,^Sample.MyTableS全局变量包含值10。此全局变量包含最近分配的流数据插入计数器的值。如果没有插入流字段数据,或者使用截断表删除了所有表数据,则此全局变量未定义。
定义流字段属性时,可以定义自定义位置,如下所示:Property Note2 As %Stream.GlobalCharacter (LOCATION="^MyCustomGlobalS");。在这种情况下,^MyCustomGlobalS全局用作指定此位置的流属性(或多个属性)的流数据插入计数器;未指定位置的流属性使用默认流位置全局(^Sample.MyTableS)作为流数据插入计数器。每个全局计数与该位置相关联的流属性的插入。如果没有插入流场数据,则位置GLOBAL是未定义的。如果一个或多个流属性定义了位置,则截断表不重置流计数器。
这些流位置全局变量的下标包含每个流字段的数据。例如,^EW3K.Cn9X.S(3)表示第三个插入的流数据项。^EW3K.Cn9X.S(3,0)是数据的长度。^EW3K.Cn9X.S(3,1)是实际的流数据值。
注意:流字段的OID与RowID或Reference字段返回的OID不同。%OID函数返回RowID或引用字段的OID;%OID不能与流字段一起使用。试图将流字段用作%OID的参数会导致SQLCODE-37错误。
在查询的WHERE子句或HAVING子句中使用流字段受到严格限制。不能将相等条件或其他关系运算符(=, !=, <, >)或包含运算符(])或跟随运算符([)与流字段一起使用。尝试将这些运算符与流字段一起使用会导致SQLCODE-313错误。
Result Set Display
- 从程序执行的动态SQL以
$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S").格式返回OID。 - SQL Shell作为动态SQL执行,并以
$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S")格式返回OID。 - 嵌入式SQL返回相同的
OID,但以编码%LIST的形式返回。可以使用$LISTTOSTRING函数将OID显示为元素以逗号分隔的字符串:6,%Stream.GlobalBinary,^EW3K.Cn9X.S。
从管理门户SQL执行界面运行查询时,不返回OID。取而代之的是:
- 字符流字段返回字符流数据的前100个字符。如果字符流数据超过100个字符,则用省略号(
...)表示。在第100个字符之后。这等效于SUBSTRING(cstream field,1,100)。 - 二进制流字段返回字符串
<binary>。
在表数据的管理门户SQL界面打开表显示中显示相同的值。
要从管理门户SQL执行界面显示OID值,请将空字符串连接到流值,如下所示:SELECT Name, ''||Photo, ''||Notes FROM Sample.MyTable。

DISTINCT, GROUP BY, and ORDER BY
每个流数据字段的OID值是唯一的,即使数据本身包含重复。
这些SELECT子句操作的是流的OID值,而不是数据值。
因此,当应用到查询中的流字段时:
- 不同的子句对重复的流数据值没有影响。
DISTINCT子句将流字段为NULL的记录数减少为一个NULL记录。 GROUP BY子句对重复的流数据值没有影响。GROUP BY子句将流字段为空的记录数量减少为一个空记录。ORDER BY子句根据数据流的OID值来排序数据,而不是数据值。ORDER BY子句列出流字段为空的记录,然后列出带有流字段数据值的记录。
谓词条件和流
IS [NOT] NULL谓词可以应用于流字段的数据值,示例如下:
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes IS NOT NULL
BETWEEN, EXISTS, IN, %INLIST, LIKE, %MATCHES, and %PATTERN 谓词可以应用于流对象的OID值,示例如下:
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes %MATCHES '*1[0-9]*GlobalChar*'
尝试在流字段上使用任何其他谓词条件会导致SQLCODE -313错误。
聚合函数和流
COUNT聚合函数接受一个流字段,并对该字段中包含非空值的行进行计数,示例如下:
SELECT COUNT(Photo) AS PicRows,COUNT(Notes) AS NoteRows
FROM Sample.MyTable

但是,流字段不支持COUNT(DISTINCT)。
对于流字段不支持其他聚合函数。
尝试将流字段与任何其他聚合函数一起使用会导致SQLCODE -37错误。
标量函数和流
除了%OBJECT、CHARACTER_LENGTH(或CHAR_LENGTH或DATALENGTH)、SUBSTRING、CONVERT、XMLCONCAT、XMLELEMENT、XMLFOREST和%INTERNAL函数外,InterSystems SQL不能对流字段应用任何函数。
尝试使用流字段作为任何其他SQL函数的参数会导致SQLCODE -37错误。
尝试使用流字段作为任何其他SQL函数的参数会导致SQLCODE -37错误。
%OBJECT函数打开一个流对象(接受一个OID)并返回oref(对象引用),示例如下:
SELECT Name,Notes,%OBJECT(Notes) AS NotesOref
FROM Sample.MyTable WHERE Notes IS NOT NULL
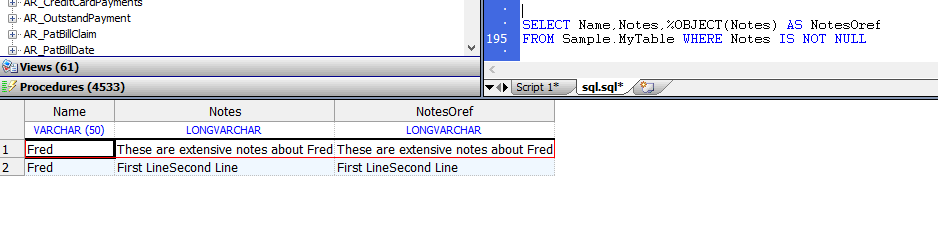
CHARACTER_LENGTH、CHAR_LENGTH和DATALENGTH函数接受流字段并返回实际的数据长度,如下面的示例所示:
SELECT Name,DATALENGTH(Notes) AS NotesNumChars,DATALENGTH(Photo) AS PhotoNumChars
FROM Sample.MyTable

SUBSTRING函数接受一个流字段,并返回流字段的实际数据值的指定子字符串,如下面的示例所示:
SELECT Name,SUBSTRING(Notes,1,10) AS Notes1st10Chars
FROM Sample.MyTable WHERE Notes IS NOT NULL
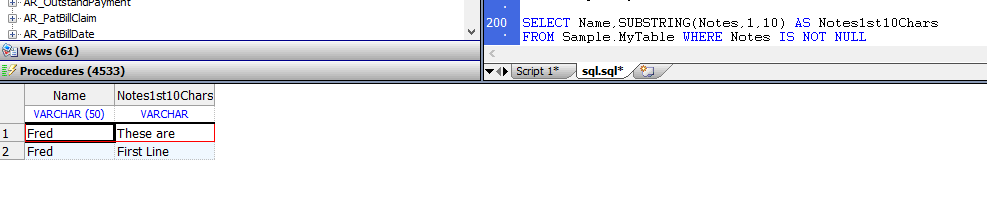
当从管理门户SQL Execute接口发出时,子字符串函数返回流字段数据最多100个字符的子字符串。
如果流数据的指定子字符串大于100个字符,则在第100个字符后用省略号(…)表示。
CONVERT函数可用于将流数据类型转换为VARCHAR,示例如下:
SELECT Name,CONVERT(VARCHAR(100),Notes) AS NotesTextAsStr
FROM Sample.MyTable WHERE Notes IS NOT NULL

CONVERT(datatype,expression)语法支持流数据转换。
如果VARCHAR精度小于实际流数据的长度,则将返回值截断为VARCHAR精度。
如果VARCHAR精度大于实际流数据的长度,则返回值为实际流数据的长度。
不执行填充。
{fn CONVERT(expression,datatype)}语法不支持流数据转换;
它发出一个SQLCODE -37错误。
%INTERNAL函数可以用于流字段,但不执行任何操作。
流字段并发锁
InterSystems IRIS通过取出流数据上的锁来保护流数据值不被另一个进程并发操作。
InterSystems IRIS在执行写操作之前取出一个排他锁。 排他锁在写操作完成后立即释放。
当第一个读操作发生时,InterSystems IRIS取出共享锁。 只有当流实际被读取时才会获取共享锁,并且在整个流从磁盘读取到内部临时输入缓冲区后立即释放共享锁。
在Intersystems中使用流字段IRIS方法
不能在Intersystems Iris方法中直接使用嵌入式SQL或动态SQL使用BLOB或CLOB值;相反,使用SQL来查找Blob或Clob的流标识符,然后创建%AbstractStream对象的实例以访问数据。
使用来自ODBC的流字段
ODBC规范不提供对BLOB和CLOB字段的任何识别或特殊处理。
InterSystems SQL将ODBC中的CLOB字段表示为具有LONGVARCHAR(-1)类型。
BLOB字段表示为类型为LONGVARBINARY(-4)。
对于流数据类型的ODBC/JDBC数据类型映射,请参考InterSystems SQL reference中的数据类型引用页中的数据类型整数代码。
ODBC驱动程序/服务器使用一种特殊协议来访问BLOB和CLOB字段。
通常,必须在ODBC应用程序中编写特殊的代码来使用CLOB和BLOB字段;
标准的报告工具通常不支持它们。
使用来自JDBC的流字段
在Java程序中,可以使用标准的JDBC BLOB和CLOB接口从BLOB或CLOB检索或设置数据。
例如:
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT MyCLOB,MyBLOB FROM MyTable");
rs.next(); // fetch the Blob/Clob
java.sql.Clob clob = rs.getClob(1);
java.sql.Blob blob = rs.getBlob(2);
// Length
System.out.println("Clob length = " + clob.length());
System.out.println("Blob length = " + blob.length());
// ...
注意:当使用BLOB或CLOB结束时,必须显式调用free()方法来关闭Java中的对象,并向服务器发送消息以释放流资源(对象和锁)。
仅仅让Java对象超出范围并不会发送清理服务器资源的消息。
在linux服务器上如何建立ODBC连接IRIS来进行查询数据库的操作
第十八章 定义和使用存储过程
本章介绍如何在IntersystemsIRIS®数据平台上定义和使用Intersystems SQL中的存储过程。它讨论了以下内容:
- 存储过程类型的概述
- 如何定义存储过程
- 如何使用存储过程如
- 何列出存储过程及其参数。
概述
SQL例程是可执行的代码单元,可以由SQL查询处理器调用。 SQL例程有两种类型:功能和存储过程。从支持FunctionName()语法的任何SQL语句中调用函数。存储过程只能由CALL语句调用。函数接受某些输入定向参数并返回单个结果值。存储过程接受某些输入,输入输出和输出参数。存储过程可以是用户定义的函数,返回单个值。 CALL语句也可以调用函数。
与大多数关系数据库系统一样,Intersystems Iris允许创建SQL存储过程。存储过程(SP)提供存储在数据库中的可调用可调用的程序,并且可以在SQL上下文中调用(例如,通过使用呼叫语句或通过ODBC或JDBC)。
与关系数据库不同,Intersystems Iris使可以将存储过程定义为类的方法。实际上,存储过程只不过是SQL可用的类方法。在存储过程中,可以使用基于对象的全系列Intersystems的功能。
- 可以通过查询数据库将存储过程定义为返回单个结果集数据集的查询。
- 可以将存储过程定义为可以用作用户定义函数的函数过程,返回单个值。
- 可以将存储过程定义为可以修改数据库数据并返回单个值或一个或多个结果集的方法。
可以确定使用 $SYSTEM.SQL.Schema.ProcedureExists()方法是否已存在该过程。此方法还返回过程类型:“函数function”或“查询query”。
定义存储过程
与Intersystems SQL的大多数方面一样,有两种方法可以定义存储过程:使用DDL和使用类。这些在以下部分中描述。
使用DDL定义存储过程
Intersystems SQL支持以下命令来创建查询:
CREATE PROCEDURE可以创建始终作为存储过程投影的查询。 查询可以返回单个结果集。CREATE QUERY创建一个查询,该查询可以选择性地投影为存储过程。 查询可以返回单个结果集。
InterSystems SQL支持以下命令来创建方法或函数:
CREATE PROCEDURE可以创建始终作为存储过程投影的方法。 方法可以返回单个值,也可以返回一个或多个结果集。CREATE METHOD可以创建一个方法,该方法可以选择投影为存储过程。 方法可以返回单个值,也可以返回一个或多个结果集。CREATE FUNCTION可以创建一个函数过程,该函数过程可以选择投影为存储过程。 函数可以返回单个值。
这些命令中指定的可执行代码块可以用InterSystems SQL或ObjectScript编写。 可以在ObjectScript代码块中包含嵌入式SQL。
SQL到类名转换
使用DDL创建存储过程时,指定的名称将转换为类名。 如果类不存在,系统将创建它。
- 如果名称是不限定的,并且没有提供FOR子句:使用系统范围的默认模式名作为包名,后跟一个点,后跟一个生成的类名,由字符串
‘func’,‘meth’,‘proc’, or‘query’组成,后跟去掉标点字符的SQL名。 例如,未限定的过程名Store_Name会产生如下类名User.procStoreName: 这个过程类包含方法StoreName()。 - 如果名称是限定的,并且没有提供
FOR子句:模式名被转换为包名,后跟一个点,后跟字符串‘func’,‘meth’,‘proc’, or‘query’,后跟去掉标点字符的SQL名。 如果需要,将指定的包名转换为有效的包名。
如果名称是限定的,并且提供了FOR子句:在FOR子句中指定的限定类名将覆盖在函数、方法、过程或查询名称中指定的模式名。
- SQL存储过程名称遵循标识符命名约定。 InterSystems IRIS从SQL名称中去除标点字符,从而为过程类及其类方法生成唯一的类实体名称。
下面的规则管理模式名到有效包名的转换:
- 如果架构名称包含下划线,则此字符将转换为点,表示子包。例如,合格的名称
myprocs.myname创建包myprocs。限定名称my_procs.myname创建了包含子包procs的包。
以下示例显示了标点符号在类名和SQL调用中的不同之处。它定义了一个包含包含两个点的类名的方法。从SQL中调用时,示例将第一个点替换为下划线字符:
Class Sample.ProcTest Extends %RegisteredObject
{
ClassMethod myfunc(dummy As %String) As %String [ SqlProc ]
{
/* method code */
Quit "abc"
}
}
SELECT Sample.ProcTest_myfunc(Name)
FROM Sample.Person
使用类定义方法存储过程
类方法可以公开为存储过程。
这些是不返回数据的操作的理想选择,例如计算值并将其存储在数据库中的存储过程。
几乎所有类都可以将方法公开为存储过程;
例外是生成器类,比如数据类型类([ClassType = datatype])。
生成器类没有运行时上下文。
只有在其他实体(如属性)的运行时中使用数据类型上下文才有效。
要定义方法存储过程,只需定义一个类方法并设置其SqlProc关键字:
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// This procedure finds total sales for a territory
ClassMethod FindTotal(territory As %String) As %Integer [SqlProc]
{
// use embedded sql to find total sales
&sql(SELECT SUM(SalesAmount) INTO :total
FROM Sales
WHERE Territory = :territory
)
Quit total
}
}
编译这个类之后,FindTotal()方法将作为存储过程MyApp.Person_FindTotal()投影到SQL中。
可以使用方法的SqlName关键字更改SQL对过程使用的名称。
该方法使用过程上下文处理程序在过程及其调用者(例如,ODBC服务器)之间来回传递过程上下文。
这个过程上下文处理程序是由InterSystems IRIS(作为%qHandle:%SQLProcContext)使用%sqlcontext对象自动生成的。
%sqlcontext由SQLCODE错误状态、SQL行数、错误消息等属性组成,使用相应的SQL变量设置,如下所示:
SET %sqlcontext.%SQLCode=SQLCODE
SET %sqlcontext.%ROWCOUNT=%ROWCOUNT
SET %sqlcontext.%Message=%msg
不需要对这些值做任何事情,但是它们的值将由客户机解释。
在每次执行之前都会重置%sqlcontext对象。
该方法不应该返回任何值。
一个类的用户定义方法的最大数目是2000个。
例如,假设有一个CalcAvgScore()方法:
ClassMethod CalcAvgScore(firstname As %String,lastname As %String) [sqlproc]
{
New SQLCODE,%ROWID
&sql(UPDATE students SET avgscore =
(SELECT AVG(sc.score)
FROM scores sc, students st
WHERE sc.student_id=st.student_id
AND st.lastname=:lastname
AND st.firstname=:firstname)
WHERE students.lastname=:lastname
AND students.firstname=:firstname)
IF ($GET(%sqlcontext)'= "") {
SET %sqlcontext.%SQLCODE = SQLCODE
SET %sqlcontext.%ROWCOUNT = %ROWCOUNT
}
QUIT
}
使用类定义查询存储过程
许多从数据库返回数据的存储过程可以通过标准查询接口实现。
只要可以用嵌入式SQL编写过程,这种方法就可以很好地工作。
注意,在以下示例中,使用了嵌入式SQL host变量为WHERE子句提供一个值:
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// This procedure result set is the persons in a specified Home_State, ordered by Name
Query ListPersons(state As %String = "") As %SQLQuery [ SqlProc ]
{
SELECT ID,Name,Home_State
FROM Sample.Person
WHERE Home_State = :state
ORDER BY Name
}
}
要将查询公开为存储过程,可以将Studio Inspector条目中的SQLProc字段的值更改为True,或者在查询定义中添加以下“[SQLProc]”字符串:
Query QueryName() As %SQLQuery( ... query definition ... )
[ SqlProc ]
编译这个类之后,ListPersons查询将作为存储过程MyApp.Person_ListPersons投影到SQL中。
可以使用查询的SqlName关键字更改SQL用于该过程的名称。
当MyApp。
从SQL调用Person_ListPersons,它将自动返回由查询的SQL语句定义的结果集。
下面是一个使用结果集的存储过程的示例:
Class apc.OpiLLS.SpCollectResults1 [ Abstract ]
{
/// This SP returns a number of rows (pNumRecs) from WebService.LLSResults, and updates a property for each record
Query MyQuery(pNumRecs As %Integer) As %Query(ROWSPEC = "Name:%String,DOB:%Date") [ SqlProc ]
{
}
/// You put initial code here in the Execute method
ClassMethod MyQueryExecute(ByRef qHandle As %Binary, pNumRecs As %Integer) As %Status
{
SET mysql="SELECT TOP ? Name,DOB FROM Sample.Person"
SET rset=##class(%SQL.Statement).%ExecDirect(,mysql,pNumRecs)
IF rset.%SQLCODE'=0 {QUIT rset.%SQLCODE}
SET qHandle=rset
QUIT $$$OK
}
/// This code is called by the SQL framework for each row, until no more rows are returned
ClassMethod MyQueryFetch(ByRef qHandle As %Binary, ByRef Row As %List,
ByRef AtEnd As %Integer = 0) As %Status [ PlaceAfter = NewQuery1Execute ]
{
SET rset=qHandle
SET tSC=$$$OK
FOR {
///Get next row, quit if end of result set
IF 'rset.%Next() {
SET Row = "", AtEnd = 1
SET tSC=$$$OK
QUIT
}
SET name=rset.Name
SET dob=rset.DOB
SET Row = $LISTBUILD(name,dob)
QUIT
}
QUIT tSC
}
ClassMethod MyQueryClose(ByRef qHandle As %Binary) As %Status [ PlaceAfter = NewQuery1Execute ]
{
KILL qHandle //probably not necesary as killed by the SQL Call framework
QUIT $$$OK
}
}
如果可以将查询编写为一个简单的SQL语句并通过查询向导创建它,那么就不需要了解实现查询的底层方法。
在后台,对于每个查询,类编译器都会根据存储过程的名称生成方法,包括:
stored-procedure-nameExecute()stored-procedure-nameFetch()stored-procedure-nameFetchRows()stored-procedure-nameGetInfo()stored-procedure-nameClose()
如果查询类型为%SQLQuery,则类编译器会自动将一些嵌入式SQL插入到生成的方法中。
Execute()为SQL声明并打开存储的游标。
Fetch()被反复调用,直到它返回一个空行(SET row ="")。
还可以选择让Fetch()返回一个AtEnd=1布尔标志,以表明当前获取构成最后一行,下一个获取预期返回空行。
然而,应该总是使用空行(row ="")作为测试,以确定结果集何时结束;
当设置AtEnd=1时,应该始终设置Row=""。
FetchRows()在逻辑上等同于反复调用Fetch()。
调用GetInfo()返回存储过程签名的详细信息。
Close()关闭游标。
当从客户机调用存储过程时,会自动调用所有这些方法,但理论上可以从运行在服务器上的ObjectScript直接调用这些方法。
要将对象从Execute()传递给Fetch(),或从Fetch()传递给下一次调用Fetch(),可以将查询处理程序设置为希望传递的对象的对象引用(oref)。
要传递多个对象,可以将qHandle设置为一个数组:
SET qHandle(1)=oref1,qHandle(2)=oref2
可以基于自定义编写的代码(而不是SQL语句)创建结果集存储过程。
对一个类的用户定义查询Query的最大数目是200。
自定义Query
对于复杂的查询或不适合查询模型的存储过程,通常需要通过替换查询的部分或全部方法来自定义查询。
你可以使用 %Library.Query。
如果选择类型%query (%Library.Query)而不是%SQLQuery (%Library.SQLQuery),则通常更容易实现查询。
这生成了相同的5个方法,但是现在FetchRows()只是重复调用Fetch() (%SQLQuery进行了一些优化,导致了其他行为)。
GetInfo()只是从签名中获取信息,因此代码不太可能需要更改。
这将问题简化为为其他三个类中的每一个创建类方法。
请注意,在编译类时,编译器会检测到这些方法的存在,而不会覆盖它们。
这些方法需要特定的签名:它们都接受类型为%Binary的Qhandle(查询处理程序)。
这是一个指向保存查询的性质和状态的结构的指针。
它通过引用传递给Execute()和Fetch(),通过值传递给Close():
ClassMethod SP1Close(qHandle As %Binary) As %Status
{
// ...
}
ClassMethod SP1Execute(ByRef qHandle As %Binary,
p1 As %String) As %Status
{
// ...
}
ClassMethod SP1Fetch(ByRef qHandle As %Binary,
ByRef Row As %List, ByRef AtEnd As %Integer=0) As %Status
{
// ...
}
Query SP1(p1 As %String)
As %Query(CONTAINID=0,ROWSPEC="lastname:%String") [sqlproc ]
{
}
代码通常包括SQL游标的声明和使用。
从类型为%SQLQuery的查询中生成的游标自动具有诸如Q14这样的名称。
必须确保查询具有不同的名称。
在尝试使用游标之前,类编译器必须找到游标声明。
因此,DECLARE语句(通常在Execute中)必须与Close和Fetch语句在同一个MAC例程中,并且必须出现在它们中的任何一个之前。
直接编辑源代码,在Close和Fetch定义中都使用方法关键字PLACEAFTER,以确保实现这一点。
错误消息引用内部游标名,它通常有一个额外的数字。
因此,游标Q140的错误消息可能指向Q14
使用存储过程
使用存储过程有两种不同的方式:
- 可以使用SQL
CALL语句调用存储过程; - 可以像使用SQL查询中的内置函数一样使用存储函数(即返回单个值的基于方法的存储过程)。
注意:当执行一个以SQL函数为参数的存储过程时,请使用CALL调用存储过程,示例如下:
CALL sp.MyProc(CURRENT_DATE)
SELECT查询不支持执行带有SQL函数参数的存储过程。
SELECT支持执行带有SQL函数参数的存储函数。
xDBC不支持使用SELECT或CALL来执行带有SQL函数参数的存储过程。
存储方法
存储函数是返回单个值的基于方法的存储过程。
例如,下面的类定义了一个存储函数Square,它返回给定值的平方:
Class MyApp.Utils Extends %Persistent [DdlAllowed]
{
ClassMethod Square(val As %Integer) As %Integer [SqlProc]
{
Quit val * val
}
}
存储的函数只是指定了SqlProc关键字的类方法。
注意:对于存储的函数,ReturnResultsets关键字必须不指定(默认)或以关键字not作为开头。
可以在SQL查询中使用存储函数,就像使用内置SQL函数一样。
函数的名称是存储函数(在本例中为“Square”)的SQL名称,该名称由定义该函数的模式(包)名称限定(在本例中为“MyApp”)。
下面的查询使用了Square函数:
SELECT Cost, MyApp.Utils_Square(Cost) As SquareCost FROM Products
如果在同一个包(模式)中定义了多个存储函数,则必须确保它们具有惟一的SQL名称。
下面的示例定义了一个名为Sample的表。
具有两个定义的数据字段(属性)和两个定义的存储函数TimePlus和DTime的工资:
Class Sample.Wages Extends %Persistent [ DdlAllowed ]
{
Property Name As %String(MAXLEN = 50) [ Required ];
Property Salary As %Integer;
ClassMethod TimePlus(val As %Integer) As %Integer [ SqlProc ]
{
QUIT val * 1.5
}
ClassMethod DTime(val As %Integer) As %Integer [ SqlProc ]
{
QUIT val * 2
}
}
下面的查询使用这些存储过程返回同一个表Sample.Wages中每个员工的Salary、time- half和double time工资率:
SELECT Name,Salary,
Sample.Wages_TimePlus(Salary) AS Overtime,
Sample.Wages_DTime(Salary) AS DoubleTime FROM Sample.Wages
下面的查询使用这些存储过程返回不同表Sample.Employee中每个员工的Salary、time- half和double time工资率:
SELECT Name,Salary,
Sample.Wages_TimePlus(Salary) AS Overtime,
Sample.Wages_DTime(Salary) AS DoubleTime FROM Sample.Employee
权限
要执行一个过程,用户必须具有该过程的execute权限。
使用GRANT命令或$SYSTEM.SQL.Security.GrantPrivilege()方法将指定过程的执行权限分配给指定用户。
通过调用$SYSTEM.SQL.Security.CheckPrivilege()方法,可以确定指定的用户是否具有指定过程的执行权限。
要列出用户具有EXECUTE权限的所有过程,请转到管理门户。
从系统管理中选择Security,然后选择Users或Roles。
为所需的用户或角色选择Edit,然后选择SQL Procedures选项卡。
从下拉列表中选择所需的名称空间。
List 存储过程
INFORMATION.SCHEMA.ROUTINES persistent类显示关于当前命名空间中所有例程和过程的信息。
当在嵌入式SQL中指定时,INFORMATION.SCHEMA。
例程需要#include %occInclude宏预处理指令。
动态SQL不需要这个指令。
下面的例子返回例程名称、方法或查询名称、例程类型(过程或函数)、例程主体(SQL=class query with SQL, EXTERNAL=not a class query with SQL)、返回数据类型,以及当前命名空间中模式“Sample”中所有例程的例程定义:
SELECT ROUTINE_NAME,METHOD_OR_QUERY_NAME,ROUTINE_TYPE,ROUTINE_BODY,SQL_DATA_ACCESS,IS_USER_DEFINED_CAST,
DATA_TYPE||' '||CHARACTER_MAXIMUM_LENGTH AS Returns,NUMERIC_PRECISION||':'||NUMERIC_SCALE AS PrecisionScale,
ROUTINE_DEFINITION
FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA='SQLUser'

INFORMATION.SCHEMA.PARAMETERS persistent类显示关于当前命名空间中所有例程和过程的输入和输出参数的信息。
下面的示例返回例程名称、参数名称(不管是输入参数还是输出参数)以及当前命名空间中模式“Sample”中的所有例程的参数数据类型信息:
SELECT SPECIFIC_NAME,PARAMETER_NAME,PARAMETER_MODE,ORDINAL_POSITION,
DATA_TYPE,CHARACTER_MAXIMUM_LENGTH AS MaxLen,NUMERIC_PRECISION||':'||NUMERIC_SCALE AS PrecisionScale
FROM INFORMATION_SCHEMA.PARAMETERS WHERE SPECIFIC_SCHEMA='SQLUser'

使用管理门户SQL界面中的Catalog Details选项卡,可以为单个过程显示大部分相同的信息。 过程的目录详细信息包括过程类型(查询或函数)、类名称、方法或查询名称、描述以及输入和输出参数的数量。 目录详细信息存储过程信息显示还提供了运行存储过程的选项。
HealthShare中RSA加密以及解密如何实现,我尝试了使用##class(%SYSTEM.Encryption).RSAEncrypt(Text,pubKey)这个函数,但是无法成功
第十七章 使用触发器
本章介绍如何在Intersystems SQL中定义触发器。触发器是响应某些SQL事件执行的代码行。本章包括以下主题:
定义触发器
有几种方法可以为特定表定义触发器:
- 在将投影到SQL表的持久性类定义中包含触发定义。例如,
MyApp.person类的此定义包括Loggevent触发器的定义,在每个成功的数据插入到MyApp.person表之后,将在每个成功的数据插入后调用:
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
// ... Class Property Definitions
Trigger LogEvent [ Event = INSERT, Time = AFTER ]
{
// Trigger code to log an event
}
}
- 使用SQL创建触发命令创建触发器。这在相应的持久性类中生成触发对象定义。 SQL触发器名称按照标识符命名约定进行操作。 IntersystemsIris®数据平台使用SQL触发名称生成相应的触发类实体名称。
必须拥有%create_trigger管理级别权限来创建触发器。必须具有删除触发器的%drop_trigger管理级别权限。
类的最大用户定义触发器数为200。
注意:Intersystems Iris不支持收集投影的表上的触发。用户无法定义这样的触发器,并且作为子表的集合的投影不认为涉及该基本集合的触发。
Intersystems Iris不支持修改Security.Roles和Security.Users表的触发器。
触发器的类型
触发器由以下内容定义:
- 导致它执行的事件类型。触发器可以是单个事件触发器或多事件触发。定义单个事件触发器以在指定表上发生插入,更新或删除事件时执行。定义多事件触发器以执行当在指定的表中发生多个指定的事件中的任何一个时执行。可以使用类定义或创建触发命令定义插入/更新,更新/删除或插入/更新/删除多事件触发器。事件类型在Class定义中指定了所需的事件触发器关键字。
- 触发器执行的时间:在事件发生之前或之后。
这是由可选的
Time trigger关键字在类定义中指定的。 默认为Before。 - 可以将多个触发器与同一事件和时间相关联;在这种情况下,可以使用
order trigger关键字来控制触发多个触发器的顺序。先触发顺序较低的触发器。 如果多个触发器具有相同的Order值,则不指定它们的触发顺序。 - 可选的
Foreach trigger关键字提供了额外的粒度。 该关键字控制触发器是每一行触发一次(Foreach = row),还是每一行或对象访问触发一次(Foreach = row/object),还是每语句触发一次(Foreach = statement)。 没有Foreach trigger关键字定义的触发器每一行触发一次。 如果触发器是用Foreach = row/object定义的,那么触发器也会在对象访问期间的特定点被调用,如本章后面所述。 可以使用INFORMATION.SCHEMA.TRIGGERS的ACTIONORIENTATION属性列出每个触发器的Foreach值
下面是可用的触发器及其等价的回调方法:
BEFORE INSERT(等价于%OnBeforeSave())AFTER INSERT(等价于%OnAfterSave())BEFORE UPDATE(等价于%OnBeforeSave())AFTER UPDATE(等价于%OnAfterSave())BEFORE UPDATE OF specified column(s)AFTER UPDATE OF specified column(s)BEFORE DELETE(等价于%OnDelete())AFTER DELETE(等价于%OnAfterDelete())
注意:当触发器执行时,它不能直接修改正在处理的表中的属性值。 这是因为InterSystems IRIS在字段(属性)值验证代码之后执行触发代码。 例如,触发器不能将LastModified字段设置为正在处理的行中的当前时间戳。 但是,触发器代码可以对表中的字段值发出更新。 更新执行自己的字段值验证。
AFTER Triggers
在INSERT、UPDATE或DELETE事件发生后执行AFTER触发器:
- 如果
SQLCODE=0(事件成功完成),InterSystems IRIS将执行AFTER触发器。 - 如果
SQLCODE是负数(事件失败),系统间IRIS就不会执行AFTER触发器。 - 如果
SQLCODE=100(没有发现要插入、更新或删除的行),则系统间IRIS执行AFTER触发器。
递归触发器
触发器执行可以是递归的。
例如,如果表T1有一个对表T2执行插入操作的触发器,表T2也有一个对表T1执行插入操作的触发器。
当表T1有一个调用例程/过程的触发器,并且该例程/过程执行对T1的插入操作时,也可以发生递归。
触发器递归的处理取决于触发器的类型:
- 行和行/对象触发器:InterSystems IRIS不阻止行触发器和行/对象触发器递归地执行。
处理触发器递归是程序员的责任。
如果触发代码不处理递归执行,则可能发生runtime
<FRAMESTACK>错误。 - 语句触发器:InterSystems IRIS阻止
AFTER语句触发器递归执行。 如果InterSystems IRIS检测到该触发器在执行堆栈中已经被调用,它将不会发出AFTER触发器。 没有错误发出; 触发器不会被第二次执行。
InterSystems IRIS不会阻止BEFORE语句触发器递归地执行。
在触发递归之前处理是程序员的责任。
如果BEFORE触发器代码不处理递归执行,可能会发生runtime <FRAMESTACK>错误。
Trigger Code
每个触发器包含执行触发操作的一行或多行代码。 每当与触发器关联的事件发生时,SQL引擎就会调用这段代码。 如果触发器是使用CREATE触发器定义的,则可以用ObjectScript或SQL编写此操作代码。 (InterSystems IRIS将SQL编写的代码转换为类定义中的ObjectScript。) 如果触发器是使用Studio定义的,那么这个操作代码必须用ObjectScript编写。
因为触发器的代码不是作为过程生成的,所以触发器中的所有局部变量都是公共变量。 这意味着触发器中的所有变量都应该用一个新语句显式声明; 这可以防止它们与调用触发器的代码中的变量发生冲突。
%ok, %msg, and %oper 系统变量
%ok:仅在触发器代码中使用的变量。 如果触发代码成功,它设置%ok=1。 如果触发代码失败,它设置%ok=0。 如果在触发器执行期间发出SQLCODE错误,InterSystems IRIS将设置%ok=0。 当%ok=0时,触发器代码中止,触发器操作和调用触发器的操作被回滚。 如果插入或更新触发器代码失败,并且表中定义了一个外键约束,InterSystems IRIS将释放外键表中相应行上的锁。
触发代码可以显式设置%ok=0。
这会创建一个运行时错误,中止触发器的执行并回滚操作。
通常,在设置%ok=0之前,触发器代码显式地将%msg变量设置为用户指定的字符串,用于描述这个用户定义的触发器代码错误。
%ok变量是一个必须显式更新的公共变量。
在完成非触发代码SELECT、INSERT、UPDATE或DELETE语句后,%ok的值与之前的值没有变化。
%ok仅在执行触发器代码时定义。
%msg:触发代码可以显式地将%msg变量设置为描述运行时错误原因的字符串。
设置变量%msg。
%oper:仅在触发器代码中使用的变量。
触发器代码可以引用变量%oper,该变量包含触发触发器的事件(插入、更新或删除)的名称。
{fieldname}语法
在触发器代码中,可以使用特殊的{fieldname}语法引用字段值(对于属于触发器关联的表的字段)。
例如,下面是MyApp中LogEvent触发器的定义。
Person类包含一个对ID字段的引用,如{ID}:
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
// ... Definitions of other class members
/// This trigger updates the LogTable after every insert
Trigger LogEvent [ Event = INSERT, Time = AFTER ]
{
// get row id of inserted row
NEW id,SQLCODE,%msg,%ok,%oper
SET id = {ID}
// INSERT value into Log table
&sql(INSERT INTO LogTable
(TableName, IDValue)
VALUES ('MyApp.Person', :id))
IF SQLCODE<0 {SET baderr="SQLCODE ERROR:"_SQLCODE_" "_%msg
SET %ok=0
RETURN baderr }
}
// ... Definitions of other class members
}
这个{fieldname}语法支持统一字段。
它不支持%SerialObject集合属性。
例如,如果表引用了嵌入的串行对象类Address(其中包含属性City),那么触发器语法{Address_City}就是对字段的有效引用。
触发器语法{Address}是对集合属性的引用,不能使用。
触发器代码中的宏
触发器代码可以包含一个引用字段名的宏定义(使用{fieldname}语法)。
但是,如果你的触发代码包含一个#Include预处理器指令,用于一个引用字段名的宏(使用{fieldname}语法),那么这个字段名就不能被访问。
这是因为InterSystems IRIS在代码被传递给宏预处理器之前,翻译触发器代码中的{fieldname}引用。
如果一个{fieldname}引用在#Include文件中,它不会在触发器代码中“看到”,因此不会被转换。
这种情况的解决方法是定义一个带参数的宏,然后将{fieldname}传递给触发器中的宏。
例如,#Include文件可以包含如下一行:
#Define dtThrowTrigger(%val) SET x=$GET(%val,"?")
然后在触发器中调用提供{fieldname}语法作为参数的宏:
$$$dtThrowTrigger({%%ID})
{name*O}, {name*N}和{name*C}触发代码语法
在更新触发器代码中有三种语法快捷方式可用。
可以使用下面的语法引用旧的(预更新的)值:
{fieldname*O}
其中fieldname是字段的名称,星号后面的字符是字母“O”(表示旧)。
对于插入触发器,{fieldname*O}总是空字符串("")。
你可以使用下面的语法来引用新的(更新后的)值:
{fieldname*N}
其中fieldname是字段的名称,星号后面的字符是字母“N”(表示新字段)。
{fieldname*N}语法只能用于引用要存储的值;
它不能用来更改值。
不能在触发器代码中设置{fieldname*N}。
在插入或更新时计算字段的值应该通过其他方法实现,比如SqlComputeOnChange。
可以使用以下语法测试字段值是否被更改(更新):
{fieldname*C}
其中,fieldname是字段的名称,星号后面的字符是字母“C”(表示已更改)。
{fieldname*C}的计算结果是1,如果字段已经被修改,0,如果它没有被修改。
对于插入触发器,InterSystems IRIS将{fieldname*C}设置为1。
对于具有流属性的类,如果SQL语句(INSERT或UPDATE)没有插入/更新流属性本身,则对流属性{stream *N}和{stream *O}的SQL触发器引用将返回流的OID。
然而,如果SQL语句确实插入/更新了stream属性,{stream *O}仍然是OID,但{stream *N}的值被设置为以下之一:
- 在触发器之前,将流字段的值以传递给更新或插入的任何格式返回。
这可以是输入到
stream属性中的文字数据值,也可以是临时stream对象的OREF或OID。 AFTER trigger将流的Id作为{stream *N}的值返回。 这是InterSystems IRIS的Id值,存储在流字段名为global的^classnameD中。 该值根据流属性的CLASSNAME类型参数使用适当的Id格式。
如果一个流属性使用InterSystems IRIS对象更新,{stream *N}的值总是一个OID。
注意:对于由串行对象的数组集合创建的子表触发器,触发器逻辑与对象访问/保存一起工作,但与SQL访问(插入或更新)不工作。
附加触发器代码语法
在ObjectScript中编写的触发器代码可以包含伪域引用变量{%%CLASSNAME}、{%%CLASSNAMEQ}、{%%OPERATION}、{%%TABLENAME}和{%%ID}。
这些伪字段在类编译时被转换成特定的值。
可以从触发器代码、SQL计算代码和SQL映射定义中使用类方法,因为类方法不依赖于拥有开放对象。
必须使用##class(classname). methodname()语法从触发器代码中调用方法。
你不能使用..Methodname()语法,因为这个语法需要一个当前打开的对象。
可以将当前行字段的值作为类方法的参数传递,但是类方法本身不能使用字段语法。
Pulling Triggers
如果调用对应于该表的DML命令,则“拉出”(执行)已定义的触发器。
对于DML命令成功插入、更新或删除的每一行,都会拉取一行或行/对象触发器。
对于每个成功执行的INSERT、UPDATE或DELETE语句,都会拉出一次语句触发器,而不管该语句是否实际更改了表数据中的任何行。
INSERT语句拉动相应的插入触发器。 插入可以通过指定%NOTRIGGER关键字来阻止触发相应的触发器。 指定%NOJOURN关键字的插入不会记录该插入或相应的插入触发器。 这意味着插入事件或触发事件都不可能回滚。
快速插入不能用于具有插入触发器的表。
UPDATE语句拉动相应的更新触发器。 更新可以通过指定%NOTRIGGER关键字来阻止触发相应的触发器。 指定%NOJOURN关键字的更新不会记录该更新或相应的更新触发器。 这意味着更新事件或触发事件都不可能回滚。根据执行的DDL操作的类型,
INSERT或UPDATE语句拉动相应的INSERT触发器或UPDATE触发器。 要防止触发任何类型的触发器,请指定%NOTRIGGER关键字。DELETE语句拉动相应的DELETE触发器。DELETE可以通过指定%NOTRIGGER关键字来阻止触发相应的触发器。 指定%NOJOURN关键字的删除不会记录删除或相应的删除触发器。 这意味着删除事件或触发事件都不可能回滚。TRUNCATE TABLE语句不会触发删除触发器。
默认情况下,DDL语句和相应的触发操作被记录在日志中。
%NOJOURN关键字阻止DDL命令和触发动作的日志记录。
触发器和对象访问
如果触发器是用Foreach = row/object定义的,那么触发器也会在对象访问期间的特定点被调用,这取决于触发器定义的Event和Time关键字,如下所示:
Event | Time | 此时也调用Trigger |
|---|---|---|
| INSERT | BEFORE | 在新对象的%Save()之前 |
| INSERT | AFTER | 在新对象的%Save()后 |
| UPDATE | BEFORE | 在已存在对象的%Save()之前 |
| UPDATE | AFTER | 在已存在对象的%Save()后 |
| DELETE | BEFORE | 在现有对象的%DeleteId()之前 |
| DELETE | AFTER | 在现有对象的%DeleteId()后 |
因此,也没有必要为了保持SQL和对象行为同步而实现回调方法,
在对象访问期间没有拔出触发器
默认情况下,SQL对象使用%Storage.Persistent存储。
InterSystems IRIS也支持 %Storage.SQL storage。
SQL存储。
在使用 %Storage.SQL storage的类中保存或删除对象时。
SQL存储,所有语句(Foreach = statement)、行(Foreach = row)和行/对象(Foreach = row/object)触发器被拉出。
没有定义Foreach trigger关键字的触发器是行触发器。
提取所有触发器是默认行为。
但是,在使用%Storage.SQL storage保存或删除类中的对象时。
SQL,可以指定只有定义为Foreach = row/object的触发器应该被拉出。
定义为Foreach = statement或Foreach = row的触发器不会被拉取。
这是通过指定类参数OBJECTSPULLTRIGGERS = 0来实现的。
默认值是OBJECTSPULLTRIGGERS = 1。
此参数仅应用于使用%Storage.SQL定义的类。
触发器与事务
触发器在事务中执行触发器码。它设置事务级别,然后执行触发器代码。成功完成触发器代码后,触发器提交事务。
注意:使用事务的触发器的结果是,如果触发器调用提交事务的代码,则触发器的完成失败,因为事务级别已经递减为0.调用生产的业务服务时可能发生这种情况。
使用INSERT语句级别对象触发器后,如果触发器集%OK = 0,则使用SQLCODE -131错误失败行的插入失败。如下所示,可能会发生交易回滚:
- 如果
auto_commit = on,则插入的事务将被回滚。 - 如果
auto_commit =off,则应用于回滚或提交输入的事务。 - 如果使用
no_auto_commit模式,则不启动事务,因此插入件不能回滚。
Auto_Commit模式是使用 SET TRANSACTION %COMMITMODE option或 SetOption()方法建立的,如下所示 SET status=$SYSTEM.SQL.Util.SetOption("AutoCommit",intval,.oldval). 可用方法INTVAL值为0(无),1(隐式)和2(显式)。
触发器可以在触发器中的%MSG变量中设置错误消息。此消息将返回给呼叫者,给出触发器失败的信息。
列出触发器
在管理门户SQL接口目录详细信息中列出了为指定表定义的触发器。这列出了每个触发器的基本信息。
Information.schema.triggers类列出了当前命名空间中的定义触发器。对于每个触发信息.Schema.triggers列出了各种属性,包括触发器的名称,关联的架构和表名称,EventManipulation属性(插入,更新,删除,插入/更新,ActionTiming属性(之前,之后),创建的属性(触发创建时间戳)和ActionStatement属性,它是生成的SQL触发器代码。
创建的属性从上次修改课程定义时派生触发创建时间戳。因此,随后使用此类(例如,定义其他触发器)可能导致创建属性值的意外更新。
可以从SQL查询中访问此信息.Schema.triggers信息,如下例所示:
SELECT TABLE_NAME,TRIGGER_NAME,CREATED,EVENT_MANIPULATION,ACTION_TIMING,ACTION_ORIENTATION,ACTION_STATEMENT
FROM INFORMATION_SCHEMA.TRIGGERS WHERE TABLE_SCHEMA='SQLUser'
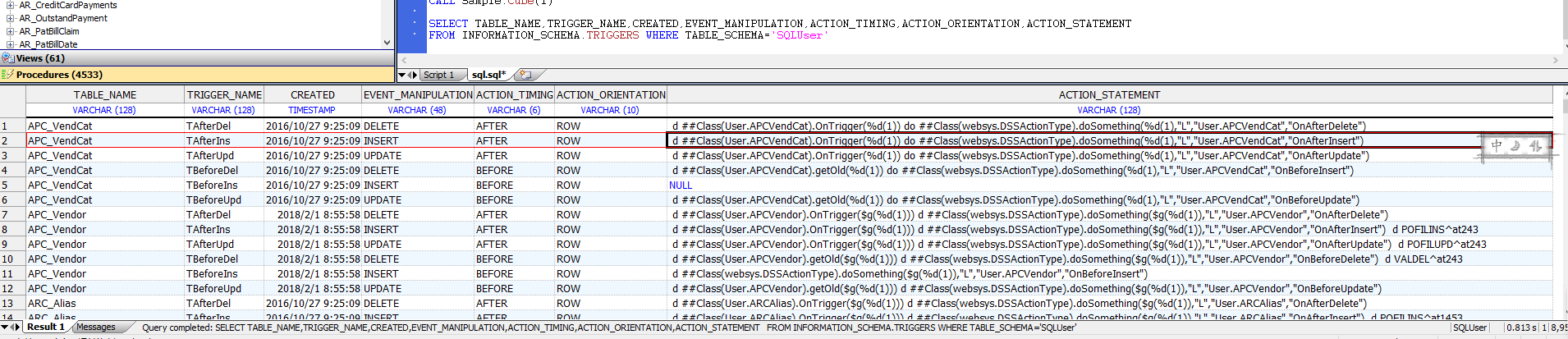
第十六章 导入SQL Code
本章介绍如何将SQL代码从文本文件导入Intersystems SQL。导入SQL代码时,IntersystemsIris®数据平台使用动态SQL准备并执行每行SQL。如果遇到无法解析的代码行,则SQL导入跳过该行代码并继续准备和执行后续行,直到它到达文件的末尾。所有SQL代码导入操作导入到当前名称空间。
SQL导入主要用于导入数据定义语言(DDL)命令(例如Create Table),并使用Insert,Update和Delete命令填充表。 SQL导入确实准备并执行SELECT查询,但不创建结果集。
SQL导入可用于导入Intersystems SQL代码。它也可以用于代码迁移,从其他供应商导入SQL代码(FDBMS,Informix,Interbase,MSSQLServer,MySQL,Oracle,Sybase)。来自其他供应商的代码被转换为Intersystems SQL代码并执行。 SQL导入无法将所有SQL命令导入Intersystems SQL。它导入与SQL标准的Intersystems Iris实现兼容的那些命令和条款。不兼容的功能通常被解析,但忽略了。
SQL导入可以成功准备一个SQL查询 - 在适当的情况下创建相应的缓存查询 - 但它不会执行查询。
通过从%system.sql.schema类中调用相应的方法,执行SQL代码导入。导入SQL代码时,这些方法可以创建其他两个文件:errors.log文件,它记录解析SQL命令中的错误,以及一个不支持的。其中包含该方法无法识别为SQL命令的文字文本。
导入Intersystems SQL.
可以使用以下%System.sql.schema方法从文本文件中导入Intersystems SQL代码:
ImportDDL()是一个通用的SQL导入方法。此方法运行作为背景(非交互式)进程。要导入Intersystems SQL,请将“IRIS”指定为第一个参数。run()是一个Intersystems SQL导入方法。该方法从终端交互方式运行。它会提示指定导入文本文件的位置,创建Errors.log文件和Unsupported.log文件以及其他信息。
注意:此导入和执行SQL DDL代码不应与管理门户SQL接口的Import语句操作混淆。该操作以XML格式导入SQL语句。
以下示例导入Intersystems Iris SQL代码文件Pathname MySQLCode.txt,在当前命名空间中执行该文件中列出的SQL命令:
DO $SYSTEM.SQL.Schema.ImportDDL("IRIS",$USERNAME,"c:\temp\mysqlcode.txt",,1)
默认情况下,ImportDDL()创建错误日志文件。此示例在与SQL代码文件中创建名为mysqlcode_errors.log的文件。第五个参数是一个布尔值,指定是否创建列出不受支持的SQL命令的文件。默认值为0.在此示例中,第五个参数设置为1,在与SQL代码文件相同的目录中创建名为mysqlcode_unsupported.log的文件。即使没有写入它们时,也会创建这些日志文件。
从终端执行ImportDDL()时,它首先列出输入文件,错误日志文件和不受支持的日志文件。然后,对于每个SQL命令,它显示一个列表,例如以下内容:
SQL statement to process (number 1):
CREATE TABLE Sample.MyStudents (StudentName VARCHAR(32),
StudentDOB DATE)
Preparing SQL statement...
Executing SQL statement...
DONE
如果在任何SQL命令中发生错误,则终端显示错误,如以下示例所示:
SQL statement to process (number 3):
INSERT INTO Sample.MyStudents (StudentName,StudentDOB) SELECT Name,
DOB FROM Sample.Person WHERE Age <= '21'
Preparing SQL statement...
ERROR #5540: SQLCODE: -30 Message: Table 'SAMPLE.PERSON' not found
Pausing 5 seconds - read error message! (Type Q to Quit)
如果在5秒内没有退出,则导入DDL()继续执行下一个SQL命令。错误记录在错误日志文件中,具有时间戳,用户名和命名空间名称。
导入文件格式
SQL文本文件必须是未格式化的文件,例如.txt文件。每个SQL命令必须在自己的行中开始。 SQL命令可能会被丢进到多行,允许缩进。默认情况下,每个SQL命令必须在其自己的行上进行Go语句。
以下是有效的Intersystems SQL Import文件文本的示例:
CREATE TABLE Sample.MyStudents (StudentName VARCHAR(32),StudentDOB DATE)
GO
CREATE INDEX NameIdx ON TABLE Sample.MyStudents (StudentName)
GO
INSERT INTO Sample.MyStudents (StudentName,StudentDOB) SELECT Name,
DOB FROM Sample.Person WHERE Age <= '21'
GO
INSERT INTO Sample.MyStudents (StudentName,StudentDOB)
VALUES ('Jones,Mary',60123)
GO
UPDATE Sample.MyStudents SET StudentName='Smith-Jones,Mary' WHERE StudentName='Jones,Mary'
GO
DELETE FROM Sample.MyStudents WHERE StudentName %STARTSWITH 'A'
GO
DHC-APP>DO $SYSTEM.SQL.DDLImport("CACHE","glenn","e:\temp\yxtest.txt",,1)
Importing SQL Statements from file: e:\temp\yxtest.txt
Recording any errors to principal device and log file: e:\temp\yxtest_Errors.log
Recording unsupported statements to file: e:\temp\yxtest_Unsupported.log
SQL statement to process (number 1):
CREATE TABLE Sample.MyStudents (StudentName VARCHAR(32),
StudentDOB DATE)
Preparing SQL statement...
Executing SQL statement...
DONE
SQL statement to process (number 2):
INSERT INTO Sample.MyStudents (StudentName,StudentDOB) SELECT Name,
DOB FROM Sample.Person WHERE Age <= '21'
Preparing SQL statement...
Executing SQL statement...
DONE
SQL statement to process (number 3):
INSERT INTO Sample.MyStudents (StudentName,StudentDOB)
VALUES ('Jones,Mary',60123)
Preparing SQL statement...
Executing SQL statement...
DONE
SQL statement to process (number 4):
INSERT OR UPDATE INTO Sample.MyStudents (StudentName,StudentDOB) VALUES ('
Smith-Jones,Mary',60123)
Preparing SQL statement...
Executing SQL statement...
DONE
SQL statement to process (number 5):
DELETE FROM Sample.MyStudents WHERE StudentName %STARTSWITH 'A'
Preparing SQL statement...
Executing SQL statement...
DONE
SQL statement to process (number 6):
SELECT TOP 5 * FROM Sample.MyStudents
Preparing SQL statement...
Executing SQL statement...
DONE
Elapsed time: 5.750462 seconds
通过设置ImportDDL(“IRIS”)DEOS第七参数,此方法可以接受(但不需要)指定的语句末尾分隔符,通常是分号(;),在每个SQL命令的末尾。默认值不支持终止终止分隔符。始终支持SQL命令后行的“Go”语句,但如果deos指定语句结束分隔符,则不需要。
支持的SQL命令
并非所有有效的Intersystems都可以导入SQL命令。以下是支持的Intersystems SQL命令列表:
CREATE TABLE, ALTER TABLE, DROP TABLE
CREATE VIEW, ALTER VIEW, DROP VIEW
CREATE INDEX all index types, except bitslice
CREATE USER, DROP USER
CREATE ROLE
GRANT, REVOKE
INSERT, UPDATE, INSERT OR UPDATE, DELETE
SET OPTION
SELECT for optimizer plan mode only
代码迁移:导入非Intersystems SQL
可以导入以其他供应商使用的SQL格式的SQL代码。来自其他供应商的代码被转换为Intersystems SQL代码并执行。提供以下方法:
ImportDDL()是一个通用的SQL导入方法。此方法运行作为背景(非交互式)进程。
要以特定格式导入SQL,将该格式的名称指定为第一个参数:FDBMS,Informix,Interbase,MSSQLSERVER(或MSSQL),MySQL,Oracle或Sybase。
以下示例导入SQL代码文件SQLCode.txt,在当前命名空间中执行该文件中列出的SQL命令:
DO $SYSTEM.SQL.Schema.ImportDDL("MSSQL",$USERNAME,$lb("C:\temp\somesql.sql","UTF8"),,1)
请注意,如果第一个参数是MSSQL,Sybase,Informix或MySQL,则第三个参数可以是SQL代码文件路径名或具有第一个元素的两个元素%list,SQL代码文件路径名和第二个元素是i / o用于使用的翻译表。
- 在
%system.sql.schema中提供单个交互式方法,用于导入以下类型的SQL:loadfdbms(),loadInformix(),loadInterbase(),loadmssqlserver(),loadoracle()和loadybase()。这些方法与终端交互式运行。它会提示指定导入文本文件的位置,创建Errors.log文件和Unsupported.log文件以及其他信息。 ImportDDLDIR()允许从目录中的多个文件导入SQL代码。此方法运行作为背景(非交互式)进程。它支持Informix,MSSQLServer和Sybase。要导入的所有文件必须具有.sql扩展后缀。ImportDir()允许从目录中的多个文件导入SQL代码。提供比ImportDDIR()更多的选项。此方法运行作为背景(非交互式)进程。它支持MSSQLServer和Sybase。可以指定允许文件扩展后缀的列表。