目录
- 本文目的
- 什么是容器,它们为什么对 IRIS 有意义
2.1 容器和镜像简介
2.2 为什么容器对开发者很有用
2.3 为什么 IRIS 可以很好地与 Docker 配合使用 - 先决条件
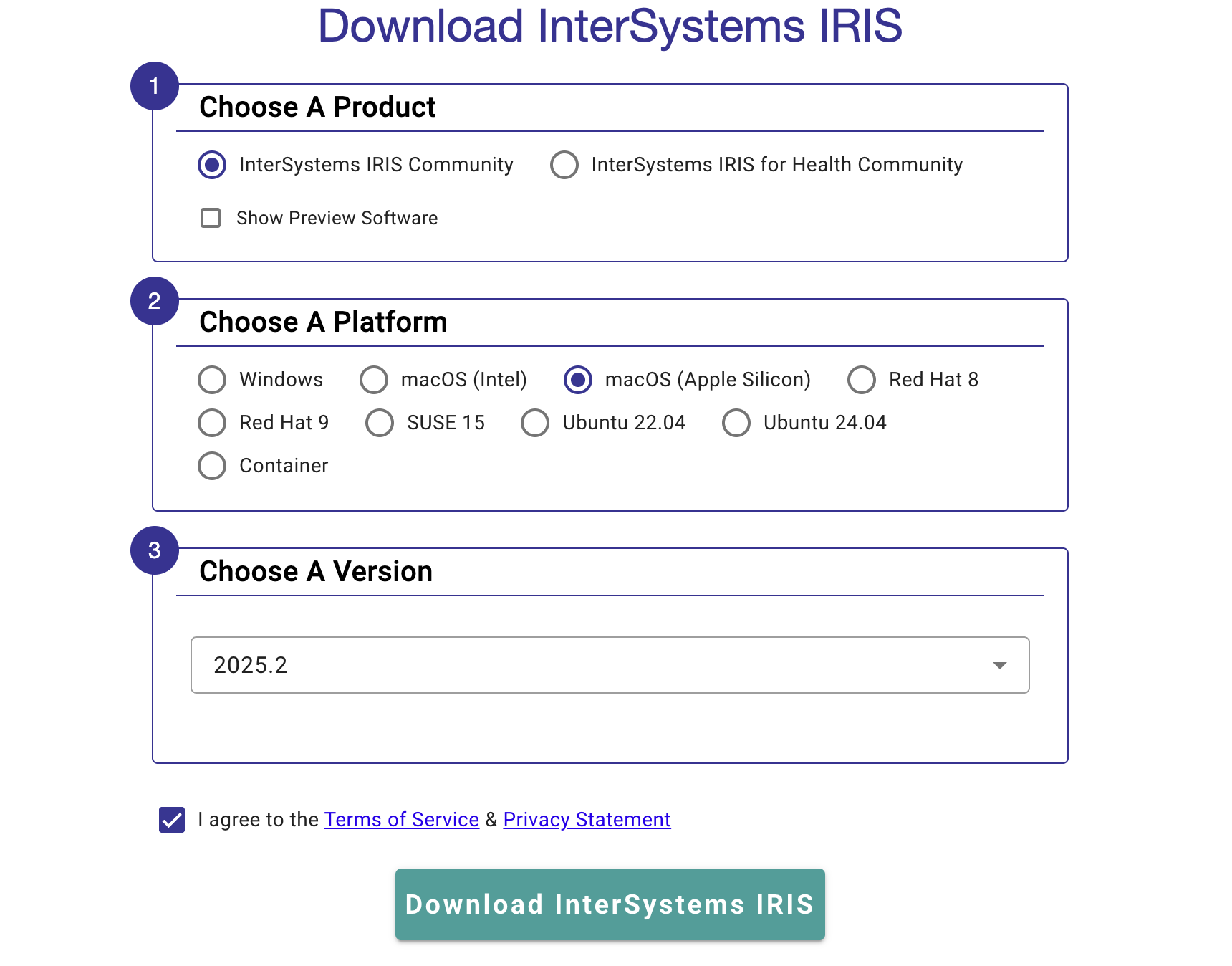
- 安装 InterSystems IRIS 镜像
4.1 使用 Docker Hub
4.2 拉取镜像 - 运行 InterSystems IRIS 镜像
5.1 启动 IRIS 容器
5.2 检查容器状态
5.3 在容器终端执行代码
5.4 访问 IRIS 管理门户
5.5 将容器连接到 VS Code
5.6 停止或移除容器
5.7 使用绑定挂载设置特定密码
5.8 使用持久化 %SYS 卷
5.8.1 可以使用持久化 %SYS 存储什么
5.8.2 如何启用持久化 %SYS - 使用 Docker Compose
6.1 Docker Compose 示例
6.2 运行 Docker Compose - 使用 Dockerfile 运行自定义源代码
7.1 Dockerfile 示例
7.2 Docker Compose 示例
7.3 了解层、镜像标记和构建与 运行时
7.4 源代码和初始化脚本
7.5 使用 Dockerfile 构建镜像
7.6 在容器化 IRIS 终端中运行指令 - 结语和未来计划
1. 本文目的
InterSystems 开发者社区已经有很多优秀的文章解释了 Docker 是什么、最重要的命令以及 InterSystems IRIS 在容器化环境中的多个用例。
本系列文章的目的略有不同。 由于我非常喜欢分步指南,我想创建一份全面的讲解,介绍如何在 InterSystems IRIS 中配置和使用 Docker,我们先从最基础的场景开始,逐步过渡到更高级的场景,例如多命名空间实例、互连容器、与外部系统的集成以及用于了解 UI 的应用程序。
2. 什么是容器,它们为什么对 IRIS 有意义
2.1 容器和镜像简介
按照传统方法,要想运行应用程序,需要将版本与您的操作系统进行匹配,并针对特定目标对其进行打包。 同时,每个应用程序都应当打包,以便专门与某个目标系统配合使用。 如果您希望应用程序在 macOS 和 Windows 上运行,必须更改应用程序设计并针对不同的系统进行打包。Docker 镜像和容器是应用程序部署技术,通过让开发者将软件打包一次并在任何地方运行来解决此问题。
Docker 是一个将软件打包到容器中的软件平台。 Docker 镜像(或容器镜像)是独立的可执行文件,包含创建和运行容器的所有指令(库、依赖项和文件)。 Docker 镜像可共享、可移植,因此您可以一次在多个位置部署同一个镜像。Docker 容器是一个运行时环境,具有运行应用程序代码所需的所有必要组件,无需使用主机依赖项。
与虚拟机不同,容器是轻量级的。 它们不需要完整的操作系统,只使用特定应用程序所需的二进制文件和库,通过 Docker 引擎直接在主机操作系统上运行,这使其更加高效。 多个隔离的容器可以在同一台计算机上并行启动,互不干扰。
2.2 为什么容器对开发者很有用
- 隔离:在清晰、可重现的环境中运行,不会影响您的主机系统。
- 可重现性:确保您的设置在不同的计算机上以相同的方式工作。
- 轻松设置:使用一个命令,只需几秒钟即可启动 IRIS 实例,无需手动安装。
2.3 为什么 IRIS 可以很好地与 Docker 配合使用
在 Docker 中运行 InterSystems IRIS 有几项优势:
- 应用程序运行并且可以在隔离的容器中进行测试
- 可以使用共享版本控制系统(如 Git),无需直接在服务器上操作
- 容器化环境可以在任何阶段重现,从而在整个软件生命周期中保持一致性。
- 您的应用程序可以轻松地在每台计算机上运行。
3. 先决条件
要在 Docker 容器中运行 InterSystems IRIS,您必须具有:
- 已安装并且正在运行的 Docker 引擎:
- 在 Linux 上安装 Docker 引擎。
- Docker 引擎也可以通过 Docker Desktop 用于 Windows、macOS 和 Linux。
- Git,以允许使用共享的源代码控制仓库。
- Visual Studio Code,以查看和修改源代码。
4. 安装 InterSystems IRIS 镜像
4.1 使用 Docker Hub
Docker Hub 是 Docker 镜像的中心注册表。 它提供了一个庞大的预构建镜像库,您可以将其作为切入点。 InterSystems 在其中发布官方 IRIS 社区版镜像,您可以下载该镜像以在自己的容器中本地运行 IRIS。 您还可以使用 Docker Hub 推送自己的自定义镜像,以便在团队中共享或分发给社区。Docker Hub 既可以在线使用,也可以嵌入到 Docker Desktop 中。
4.2 拉取镜像
一些常见的 Docker 镜像命令包括:
| 命令 | 描述 |
|---|---|
docker pull <image> | 从 Docker Hub 下载镜像 |
docker images | 列出所有本地镜像 |
docker rmi <image> | 移除一个或多个镜像 |
您可以直接在镜像的 Docker Hub 页面上找到确切的拉取命令:.png)
对于 InterSystems IRIS 镜像,该命令为:
docker pull intersystems/iris-community:latest-cd或者,您可以在 Docker Desktop 搜索栏中搜索 iris-community 并点击 Pull:


安装后,您应当拥有在本地镜像中列出的 InterSystems IRIS 镜像:

5. 运行 InterSystems IRIS 镜像
从 Docker Hub 中拉取出 InterSystems IRIS 镜像后,您可以在容器内运行该镜像。
以下是常用的 Docker 容器命令:
| 命令 | 描述 |
|---|---|
docker run -d <image> | 以分离模式运行:在后台启动容器并立即将控制权返还给终端。 |
docker run -p <host>:<container> <img> | 将主机端口映射到容器端口 |
docker ps | 列出正在运行的容器 |
docker ps -a | 列出所有容器(包括已停止的容器) |
docker exec -it <container> bash | 在正在运行的容器中执行命令 |
docker logs <container> | 查看容器日志 |
docker stop <container> | 停止正在运行的容器 |
docker start <container> | 启动已停止的容器 |
docker restart <container> | 重启容器 |
docker rm <container> | 移除容器 |
5.1 启动 IRIS 容器
您可以通过 Docker Desktop UI 启动名为“my-iris”的 InterSystems IRIS 社区版容器,只需在 Images 面板中点击要运行的镜像的 Run 按钮即可。 对于 InterSystems 镜像,可以指定一些可选的设置,例如在主机上公开哪些端口来与容器内运行的服务进行通信。
可以通过上面显示的菜单完成操作,具体如下:
- 左侧 → 主机上的端口
- 右侧 → 容器内的端口
常用 IRIS 端口(容器内)
- 1972 → 超级服务器端口:由 IRIS 用于网络协议(ObjectScript、JDBC 等)。
- 52773 → Web 服务器端口:由 IRIS 用于管理门户(Web 界面)。
如果没有显式映射端口,Docker 将在主机上指定随机端口。
.png)
或者,可以使用终端来运行容器:
docker run --name my-iris -d --publish 9091:1972 --publish 9092:52773 intersystems/iris-community:latest-cd在本例中:
- 主机上的
9091映射到容器内的1972(超级服务器)。 - 主机上的
9092映射到容器内的52773(管理门户)。
5.2 检查容器状态
运行此命令后,运行 docker ps 以验证容器是否正常运行。
> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
907d4c2b4ab5 intersystems/iris-community:latest-cd "/tini -- /iris-main" 3 seconds ago Up 2 seconds (health: starting) 0.0.0.0:9091->1972/tcp, [::]:9091->1972/tcp, 0.0.0.0:9092->52773/tcp, [::]:9092->52773/tcp my-iris正在运行的容器也会列在 Docker Desktop Containers 面板中:
.png)
相关镜像的状态将是 In Use,如 Images 面板中所示:

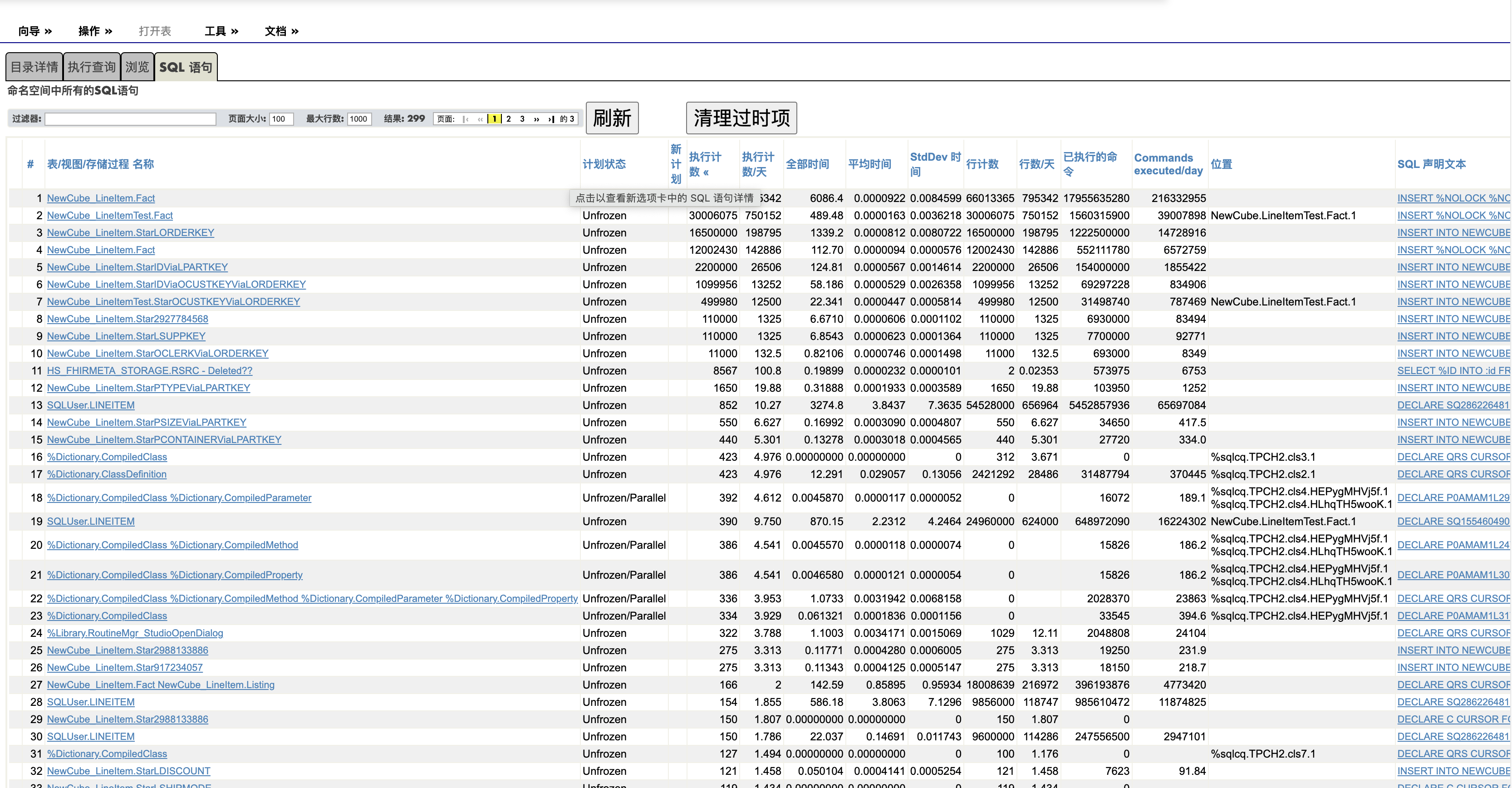
5.3 在容器终端执行代码
当容器状态显示 Running 时,表示一切正常。
您可以进行测试,只需打开容器终端(点击 Docker Desktop 的 Containers 面板内的容器名称并转到 Exec)并输入以下内容即可:
iris session IRIS这将在 Docker 容器中打开一个 IRIS 终端,您可以在其中使用标准的 ObjectScript 语法来执行命令和脚本。
.png)
5.4 访问容器化实例的 IRIS 管理门户
接下来,打开浏览器并导航到:
http://localhost:9092/csp/sys/UtilHome.csp
默认情况下,IRIS 容器使用用户 _SYSTEM 和密码 SYS。登录后需要更改密码。
这将为您提供 IRIS 管理门户的完整访问权限,这样您可以直接从 Web 界面管理命名空间、数据库和其他 IRIS 功能。
.png)
5.5 将容器连接到 VSCode IDE
您可以使用映射的超级服务器端口(默认为容器内的 1972,例如主机上的 9091)和 Web 服务器端口(默认为容器内的 52773,例如主机上的 9092)将您喜欢的 IDE(例如 VS Code 或 Studio)连接到 IRIS 容器。 这样您可以直接针对正在运行的容器开发和测试 ObjectScript 代码。
将容器连接到 VSCode:
- 安装 InterSystems ObjectScript 扩展程序包
- 打开 InterSystems Server 扩展程序
- 点击三个点和“Edit server”
-
.png)
- 点击“Edit in settings.json”
- 将此元素添加到“intersystems.servers”json:
"docker_iris": {
"webServer": {
"scheme": "http",
"host": "localhost",
"port": 9092
},
"description": "Connection to Docker container."
}- 服务器现已连接。 您可以使用 _SYSTEM 用户登录。
- 您可以看到,USER 是唯一可用的命名空间:
.png)
5.6 停止或移除容器
要停止正在运行的容器,请使用以下命令:
docker stop my-iris再次启动容器
要再次启动容器,请使用以下命令:
docker start my-iris移除(删除)容器
要移除容器实例,但不移除镜像,请使用:
docker rm my-iris除非您挂载了卷,否则容器内的所有数据都将丢失(我们将在后续段落中讨论这个问题)。
5.7 使用绑定挂载设置特定密码
在启动容器时,可以使用密码文件设置自定义密码。 该文件将保存在我们的主机上,并使用绑定挂载机制复制到容器中。
当您使用绑定挂载时,主机上的文件或目录将从主机挂载到容器中,从而允许在 Docker 主机上的开发环境和容器之间共享源代码或构建工件。
- 创建名为 password.txt 的文件,其中仅包含字符串形式的密码(注意! 记下密码,以后会用到)。
- 复制其路径,本例中为
C:\InterSystems\DockerTest\password\password.txt - 运行以下命令:
docker run --name my-iris -d --publish 9091:1972 --publish 9092:52773 --volume "C:\InterSystems\DockerTest:/durable" intersystems/iris-community:latest-cd --password-file /durable/password/password.txt 容器运行后,可以使用用户 _SYSTEM 和您在密码文件中写下的密码登录。
在 Docker 容器内,您会看到一个 password.txt.done 文件。您的主机文件夹中会有一个相同的文件。
.png)
文件扩展名会更改为 .done,以避免密码以纯文本形式保留。 这是 InterSystems IRIS 中对密码文件的标准操作。 因此,在从 password.txt 文件读取密码并将默认 IRIS 用户 (_SYSTEM) 更新为该密码后,出于安全原因,该文件会附加 .done 并移除密码。
您可以使用自定义密码登录管理门户(我告诉过您记下来 :D)。 登录后,InterSystems IRIS 不会强迫您更改密码。
请注意,如果在没有挂载任何持久化卷的情况下移除了容器,然后重启(有关详情,请参阅下一段),则不会再次从 password.txt 文件中读取密码,因为它已被替换为 password.txt.done。 如果是这种情况,将使用标准的“SYS”密码。
5.8 使用特定的持久化卷启动容器
默认情况下,当您使用 docker rm <container's name> 命令移除正在运行的 Docker 容器时,保存在该容器内的任何内容都将消失。
为了避免丢失数据,InterSystems IRIS 提供了持久化 %SYS 功能。 这可以让实例将所有重要的文件都存储在您的主机上,以便在容器和实例重启后它们仍然存在。
5.8.1 可以使用持久化 %SYS 存储什么?
一些示例包括:
- 配置文件(
iris.cpf、httpd.conf) - Web 网关配置和日志 (
/csp) - 系统数据库(
IRIS、USER、IRISSECURITY、IRISTEMP等) - 日志、写入镜像文件 (WIJ) 和临时文件
- 日志文件(
messages.log、SystemMonitor.log等) - 许可证密钥 (
iris.key) - 您创建的任何其他数据库
5.8.2 如何启用持久化 %SYS
首先,从主机中选择一个文件夹,如 C:\InterSystems\DockerTest
- 在 Linux 上,创建 irisowner 用户并为其授予目录所有权,确保 IRIS 可以写入该文件夹:
adduser irisowner
chown -R irisowner:irisowner /InterSystems/DockerTest- 在 Windows 上,您可以跳过这一段,因为 Docker Desktop 将使用您当前的 Windows 用户权限挂载该文件夹。
然后,挂载您的主机文件夹并使用 ISC_DATA_DIRECTORY 变量告知 IRIS 将其持久化数据写入何处:
--volume "C:\InterSystems\DockerTest:/durable" --env ISC_DATA_DIRECTORY=/durable/iris
在终端上运行的完整指令是:
docker run --name my-iris -d --publish 9091:1972 --publish 9092:52773 --volume "C:\InterSystems\DockerTest:/durable" --env ISC_DATA_DIRECTORY=/durable/iris intersystems/iris-community:latest-cd --password-file /durable/password/password.txt此时,您可以检查您的容器,看到一个持久化文件夹已装载并包含目录 iris/(对于持久化 %SYS)和 password/。 在主机上,您也可以看到以下两个目录:
.png)
如果容器停止并被移除,当您使用相同的 Docker Compose 命令重新创建容器时,IRIS 将使用 iris/ 文件夹中的数据恢复其先前的状态(用户、配置、日志、数据库等),因此不会丢失任何内容。 您可以通过创建 Web 应用程序、停止并移除容器,然后再次创建来进行测试。 如果不使用持久化 %SYS 功能,每次移除容器并启动新实例时,%SYS 内的任何更改都会丢失。
请注意,如果删除了 iris/ 文件夹,下次启动 IRIS 容器时,由于无法找到先前的 %SYS 数据,它将像在全新安装中一样进行初始化。 将创建一个全新的 iris/ 文件夹。
6. 使用 Docker Compose
到目前为止,您一直在使用一个长命令 docker run 启动 InterSystems IRIS。 这虽然可行,但很快就会难以使用普通的 Shell 命令来管理一切。
Docker Compose 是一个 YAML 配置文件,用于定义如何运行一个或多个容器。这简化了整个应用程序栈的控制,使管理服务、网络和卷变得更加容易。 只需一个命令,即可从配置文件创建并启动所有服务。
以下是 Docker compose 的常用命令:
| 命令 | 描述 |
|---|---|
docker compose up -d | 以分离模式启动 docker-compose.yml 中定义的所有服务(默认情况下,使用当前文件夹中的 docker-compose.yml 文件)。 |
docker compose -f ./path/to/docker-compose.yml up -d | 从另一个目录中的 compose 文件启动服务。 |
docker compose down | 停止并移除由 docker compose up 创建的所有容器、网络和卷。 |
docker compose ps | 列出由 Compose 管理的容器。 |
docker compose logs | 查看 Compose 文件中定义的所有服务的日志。 |
docker compose logs <service> | 查看特定服务(例如,iris)的日志。 |
docker compose exec <service> bash | 在由 Compose 管理的正在运行的容器内打开一个 Shell。 |
docker compose stop | 停止正在运行的容器,但不将其移除。 |
docker compose start | 启动之前停止的容器。 |
docker compose restart | 重启 Compose 文件中定义的所有容器。 |
docker compose build | 构建或重建由 Dockerfile 定义的服务。 |
docker compose pull | 拉取服务的最新镜像。 |
docker compose config | 验证并查看 Compose 文件中的合并配置。 |
6.1 Docker Compose 示例
要使用 Docker Compose,必须创建一个 docker-compose.yml 文件,其中包含您要创建和启动的容器的所有配置。
这样一来,以下命令:
docker run --name my-iris -d --publish 9091:1972 --publish 9092:52773 --volume "C:\InterSystems\DockerTest:/durable" --env ISC_DATA_DIRECTORY=/durable/iris intersystems/iris-community:latest-cd --password-file /durable/password/password.txt可被替换为下方的 docker-compose.yml:
# docker-compose.yml
services:
iris:
container_name: my-iris
image: intersystems/iris-community:latest-cd
init: true
volumes:
# System/persistent data (IRIS installation, databases, etc.)# On Windows, you can use either: "C:\\InterSystems\\DockerTest:/durable"
- C:/InterSystems/DockerTest:/durable
ports:
- "9092:52773"# Management Portal / REST APIs
- "9091:1972"# SuperServer port
environment:
- ISC_DATA_DIRECTORY=/durable/iris
# Use the password file to log within the container
command: --password-file /durable/password/password.txt6.2 运行 Docker Compose
在保存 Docker Compose 文件的目录中打开一个终端(或使用 -f 选项)并运行以下命令:
docker compose up -d您的 IRIS 容器将以 Docker Compose 文件中指定的确切配置启动。
在 Docker Desktop 中,您现在可以看到一个名为“dockertest”的 Compose 栈(它采用保存 Docker Compose 的文件夹的名称)已经创建并与容器“my-iris”相关联:
.png)
7. 使用 Dockerfile 运行自定义源代码
到目前为止,您一直在直接从官方 Docker 镜像运行 InterSystems IRIS。 不过,在构建镜像时,我们可能需要自动加载镜像中的 ObjectScript 类或其他自定义代码。
Dockerfile是一个文本文件,其中包含从基础镜像(如 intersystems/iris-community:latest-cd)开始构建镜像的指令。 使用 Dockerfile,我们可以将自定义源代码添加到容器中,并在构建镜像时运行自定义命令。
7.1 Dockerfile 示例
下一个示例提供了一个执行以下操作的 Dockerfile:
- 从官方 InterSystems IRIS 镜像启动镜像。
- 将应用程序代码从
src/文件夹复制到容器。 - 运行脚本来导入类并初始化容器化的应用程序,然后将日志保存到日志文件中。
- 公开默认的 InterSystems IRIS 端口。
7.2 Docker Compose 示例
您还应当修改 Docker Compose,以指定从当前文件夹中的 Dockerfile 构建镜像:
# docker-compose.yml
services:
iris:
container_name: my-iris
build: # this tells Docker to build a new image based on the one specified in the Dockerfile
context: . # build the image from local Dockerfile
dockerfile: Dockerfile
image: my-modified-iris-image:latest # give the new image a new tag to avoid overriding the base image
init: true
volumes:
# System/persistent data (IRIS installation, databases, etc.)# On Windows, you can use either: "C:\\InterSystems\\DockerTest:/durable"
- C:/InterSystems/DockerTest:/durable
ports:
- "9092:52773"# Management Portal / REST APIs
- "9091:1972"# SuperServer port
environment:
- ISC_DATA_DIRECTORY=/durable/iris
# Use the password file to log within the container
命令:--password-file /durable/password/password.txt7.3 了解层、镜像标记和构建与 运行时
在 Docker 中,正如什么是镜像?中所述,有两个重要的原则需要牢记:
- 镜像不可变:创建完镜像后,将无法进行修改。 您只能生成新的镜像或在镜像上添加更改。
- 容器镜像由层组成:每一层代表一组添加、移除或修改文件的文件系统更改。
执行 Dockerfile 中指定的指令时,新层会添加到镜像中。 这些层也将显示在镜像信息中。
考虑到这一点,务必区分 Docker 在构建时(当它从 Dockerfile 创建镜像时)和运行时(当它从该镜像启动容器时)的作用。
以下每个 Dockerfile 指令都在构建时执行:
COPY:将文件复制到镜像中RUN:执行命令并将结果保存为新的镜像层ENTRYPOINT:不改变文件系统,而是定义将在运行时启动的默认进程EXPOSE:设置元数据,指示镜像打算使用哪些端口
在运行时,Docker 不会重建镜像,而是在镜像上添加一个容器层。容器运行时所做的所有更改(如新文件、编辑、日志)都会进入这个临时层。
从上一个 Docker Compose 示例来看:
build: # this tells Docker to build a new image based on the one specified in the Dockerfile
context: . # build the image from local Dockerfile
dockerfile: Dockerfile
image: my-modified-iris-image:latest # give the new image a new tag to avoid overriding the base image这些指令通过拉取基础镜像并按照 Dockerfile 中的描述进行修改,告知 Docker 创建一个名为“my-modified-iris-image:latest”的新镜像(这称为标签)。 用其他名称标记新镜像非常重要。如果我们不在新创建的镜像上放置标签,基础镜像会被新镜像覆盖。 官方镜像仍在 Docker Hub 上提供,但此本地版本会对其进行映射,并且每个引用该标签的项目现在都会不知不觉地使用包含多个新层的自定义镜像。
为了避免这种情况,请务必使用不同的标签来创建新的单独镜像,同时确保官方基础镜像干净、可重用。
7.4 源代码和初始化脚本
此时,我们应至少创建一个类,并将其放在 src/ 文件夹中。 该类将被复制到容器中,并通过 iris.script 文件导入,该文件包含在构建镜像时导入类和初始化应用程序所需的所有指令。
在项目文件夹中创建一个名为 src/DockerStepByStep 的新目录并创建以下类文件:
Class DockerStepByStep.cheers Extends%RegisteredObject
{
ClassMethod sayHi() As%Status
{
Set sc = $$$OKw"Hi mom!",!
Return sc
}
}
在项目的根目录中,创建一个名为 iris.script 的文件:
// Unexpire passwords for dev modezn"%SYS"Do##class(Security.Users).UnExpireUserPasswords("*")
// Load classes from durable sourcezn"USER"// Import classesset importPath = "/opt/irisapp/src"write"Loading classes at '", importPath, "' ...", !
set errors = ""do$System.OBJ.Import(importPath,"cuk",,.errors)
if errors = 0 { write"Classes loaded successfully", ! } else { write errors, " errors occurred while loading classes!", ! }
halt
7.5 使用 Dockerfile 构建镜像
首次运行时,您可以使用以下命令从 Dockerfile 构建镜像(--build 标记会强制 Docker 从您的 Dockerfile 重建镜像):
docker-compose up --build对于其他运行,如果 Dockerfile 未被修改,则可以简单地运行:
docker-compose up -d开始构建镜像后,您会在终端中看到以下日志:
PS C:\InterSystems\DockerTest> docker-compose up --build
[+] Building 21.5s (13/13) FINISHED
=> [internal] load local bake definitions 0.0s
=> => reading from stdin 530B 0.0s
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.73kB 0.0s
=> [internal] load metadata for docker.io/intersystems/iris-community:latest-cd 10.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/6] FROM docker.io/intersystems/iris-community:latest-cd@sha256:93488df381f5868649e7bfc33a9083a3e86a22d 0.9s
=> => resolve docker.io/intersystems/iris-community:latest-cd@sha256:93488df381f5868649e7bfc33a9083a3e86a22d 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 147B 0.0s
=> [2/6] WORKDIR /opt/irisapp 0.0s
=> [3/6] COPY src src 0.1s
=> [4/6] COPY iris.script . 0.1s
=> [5/6] RUN mkdir -p /opt/irisapp/logs 0.3s
=> [6/6] RUN iris start IRIS && iris session IRIS < iris.script > /opt/irisapp/logs/build.log 2>&1 && 4.5s
=> exporting to image 4.5s
=> => exporting layers 3.3s
=> => exporting manifest sha256:3ce316cefa21a3707251c4287005a15b02e6dc0151b24baf2a82f76064792250 0.0s
=> => exporting config sha256:00238e19edef86b29149d2eb89ff75f4d1465ba0d9a2ac4494a14d3bd3746a94 0.0s
=> => exporting attestation manifest sha256:3579cab5c8accc7958090276deb60bd7dbbc2ecbf13af8e7fa8c4ff2dfe91028 0.0s
=> => exporting manifest list sha256:17b969c340f57d611cc7603287cc6db50cffd696258a72b5648ece0a919676ac 0.0s
=> => naming to docker.io/intersystems/iris-community:latest-cd 0.0s
=> => unpacking to docker.io/intersystems/iris-community:latest-cd 0.9s
=> resolving provenance for metadata file 0.0s
[+] Running 3/3
✔ intersystems/iris-community:latest-cd Built 0.0s
✔ Network dockertest_default Created 0.1s
✔ Container my-iris Created 0.2s 在第 6/6 步中,iris.script 文件被执行到容器化的 IRIS 实例中,日志保存在路径 /opt/irisapp/logs/build.log 中。
要查看日志,可以运行以下指令:
docker exec -it my-iris cat /opt/irisapp/logs/build.log您应当看到以下记录,这些记录会告知您类编译的结果:
Node: buildkitsandbox, Instance: IRIS
USER>
USER>
%SYS>
%SYS>
%SYS>
%SYS>
USER>
USER>
USER>
USER>
Loading classes at '/opt/irisapp/src' ...
USER>
USER>
Load of directory started on 09/16/202507:46:28
Loading file /opt/irisapp/src/DockerStepByStep/cheers.cls as udl
Compilation started on 09/16/202507:46:28 with qualifiers 'cuk'
Class DockerStepByStep.cheers is up-to-date.
编译在 0.005s 内成功完成。
Load finished successfully.
USER>
Classes loaded successfully
USER>
USER>
在 Docker Desktop 上,您可以看到一个名为“my-modified-iris-image”的新镜像已创建,并且正在与基础官方镜像一起运行。
.png)
如果检查这些镜像,您会发现自定义镜像由 31 层组成,而不是原始镜像的 25 层。 新层与 Dockerfile 在构建时执行的指令相对应:
.png)
7.6 在容器化 IRIS 终端中运行指令
要测试这些类,您可以在容器化 IRIS 实例中激活 IRIS 终端。 为此,请执行以下指令:
docker exec -it my-iris iris session IRIS此时,您可以使用以下命令从 USER 命名空间调用 ClassMethod:
do##class(DockerStepByStep.cheers).sayHi()最后,您应当看到以下输出:
PS C:\InterSystems\DockerTest> docker exec -it my-iris iris session IRIS
Node: 41c3c7a9f2e4, Instance: IRIS
USER>do##class(DockerStepByStep.cheers).sayHi()
Hi mom!
8. 结语和未来计划
我们已经完成了在 Docker 中运行 InterSystems IRIS 的整个周期:
- 拉取镜像
- 启动并配置容器
- 使用持久化 %SYS 来持久化数据
- 使用自己的代码和脚本构建自定义镜像
以上内容足以让您在容器化环境中试验 IRIS 并将其用于开发。
您可以访问 GitHub 仓库,其中包含最后一部分讨论的所有文件(Docker Compose、Dockerfile、iris.script 等)。
敬请期待下一篇文章!
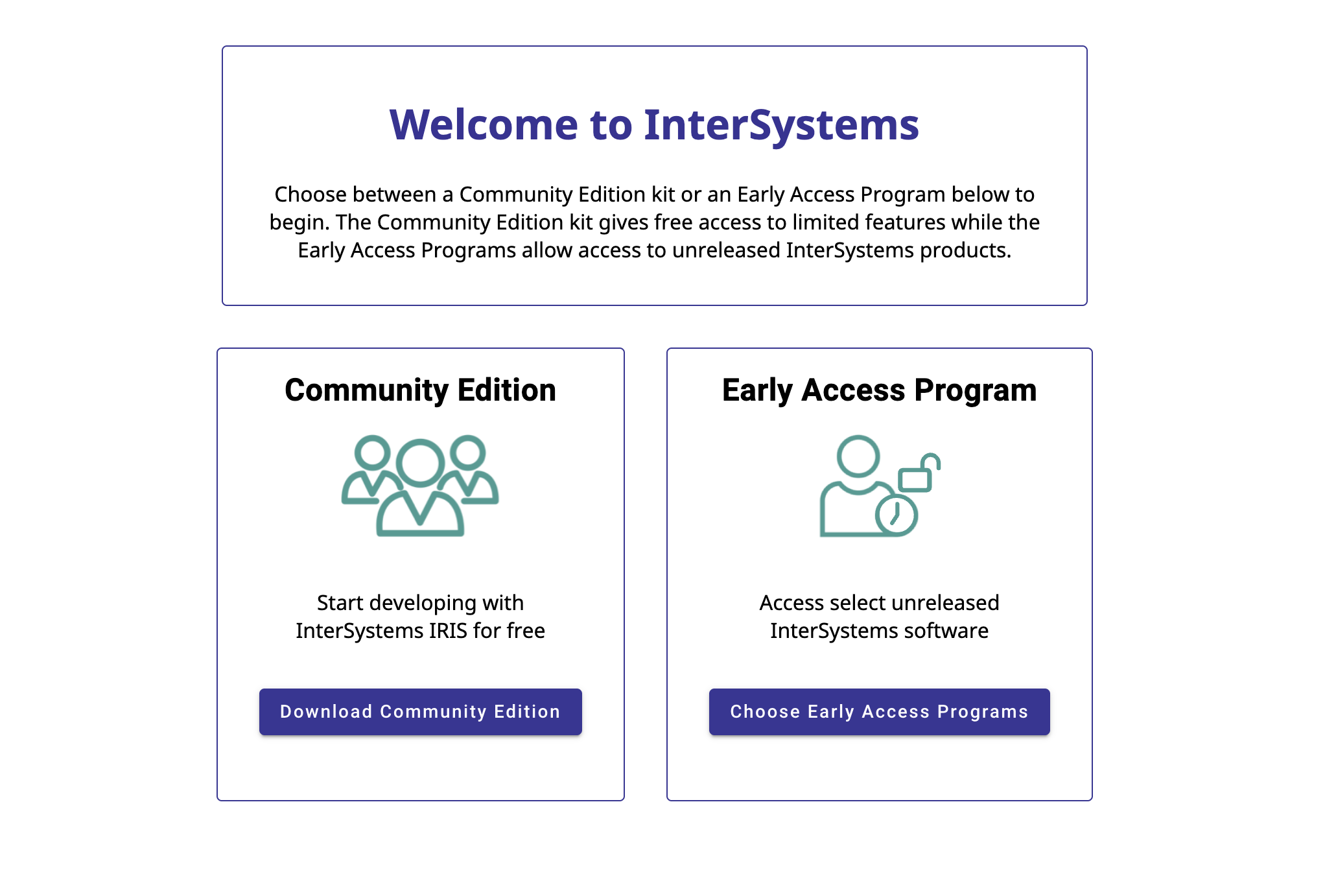
 登录后,您应会看到以下页面;点击“下载社区版”开始下载安装套件:
登录后,您应会看到以下页面;点击“下载社区版”开始下载安装套件: