嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
🏆 InterSystems 2024 Python 编程大赛 🏆
时间: 2024年7月15日-8月4日(美国东部时间)
奖金池: 14,000美元
.jpg)

InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
🏆 InterSystems 2024 Python 编程大赛 🏆
时间: 2024年7月15日-8月4日(美国东部时间)
奖金池: 14,000美元
如果要让超时功能失效, 在DSN设置查询超时为disabled:
Windows Control Panel > Administrative Tools > Data Sources (ODBC) > System DSN configuration
如果勾选了Disable query timeout , 超时就会失效.
如果想在应用侧修改,你可以在ODBC API 层设置:在连接数据源之前,调用ODBC SQLSetStmtAttr功能设置SQL_ATTR_QUERY_TIMEOUT 属性
如果您想在InterSystems 产品启动时执行一个操作系统可执行文件,命令或者程序,可以在SYSTEM^%ZSTART routine里面写明流程 ( %ZSTART routine在 %SYS 命名空间里面创建).
在 SYSTEM^%ZSTART 里面写代码之前, 请确保他可以在任何情况下能正常工作
如果 ^%ZSTART routine 写的不对,或者没有响应或者发生错误,InterSystems 产品可能会无法启动。
更多信息,请参考一下文档。
About writing %ZSTART and %ZSTOP routines [IRIS]
About writing %ZSTART and %ZSTOP routines
InterSystems 产品里数据 (表、对象、实例数据) 是存在global 变量里的。
每个global 的数据大小可以从管理门户中中点击属性查看Management Portal > System > Configuration > Local Database > Globals page, 然后在global 属性页点击计算大小Calculate Size 按钮。
你可以在终端上调用^%GSIZE 来在命名空间里显示数据大小,方法如下.
流程如下
1. 上传到 FTP server
在 OEX 最近一次编程竞赛之后,我有一些令人惊讶的发现。
几乎所有的应用程序都是基于人工智能与预制 Python 模块的结合。
但深入研究后发现,所有示例都使用了 IRIS 的相同技术组件。
从 IRIS 的角度来看,无论是搜索文本还是搜索图像或其他模式都是一样的。 其底层基本都是一样的。
这让我想起了我家里的情况。我的妻子和女儿对家里的大量裙子、衬衫和其他衣服的信息进行了整理。
但无论如何进行整理、分类、归档,我依然通过和我的妻子和女儿说话,来确定我的穿着。
无论怎样包装,其结果都是如此。
回到这次竞赛比赛:
同样的 IRIS 技术内容,却有很多花哨的包装。
每个人都在同一条高速公路上奔跑。没有人提到它有什么限制。
于是我试着深入挖掘,找出新数据类型 VECTOR 的使用限制。
所有向量都有两个基本参数
- 静态 DATATYPE:"整型integer"(或 "int")、"double"、"十进制decimal"、"字符串 "和 "时间戳"。
- 半动态 LEN(gth): > 0 通常也称为 POSITION;纯整数。
迄今为止,我看到的大多数使用向量vector的示例,将它只作为 SQL 中的一种功能,尤其是围绕 VECTOR_Search 的 3 个函数。
* TO_VECTOR()
* vector_dot_product ()
* vector_cosine ()
在 iris-vector-search 演示包中隐藏着一个非常有用的摘要。
从那里,你可以通过多个链接找到所需的一切。
我还缺少更多的 VECTOR 方法,于是在 Idea Portal 上提出了相关请求。
接着,我想起每个 SQL 方法或存储过程都有一堆 ObjectScript 代码。
于是我开始搜索,下面就是我的研究的一些总结:
%Library.Vector 是对新数据类型的核心描述
这是一种复杂的结构,就像对象或 %DynamicObjects 或 $Bit Expressions 一样,需要特定的方式去访问。
我们还可以看到 2 个必备参数:
* DATATTYPE - 一旦设置就不能更改。 可接受的类型: "整数integer"(或 "int")、"双精度浮点double"、"十进制decimal"、"字符串 "和 "时间戳"。
* LEN >0 时,可以增长,但绝对不能缩小
你可以使用List query 对 %SYS.Audit 查询审计日志,代码如下:
Set statement=##class(%SQL.Statement).%New()
Set status=statement.%PrepareClassQuery("%SYS.Audit","List")
Set rs=statement.%Execute()
Set tab = $char(9)
While rs.%Next() {
Write rs.%Get("TimeStamp")_tab_rs.%Get("Event")_tab_rs.%Get("Username"),!
}通过 REST API 将前端 React 应用程序与 IRIS 数据库等后端服务集成,是构建健壮网络应用程序的强大方法。但是,开发人员经常遇到的一个障碍是跨源资源共享(CORS)问题,由于网络浏览器强制执行的安全限制,该问题可能会阻止前端访问后端的资源。在本文中,我们将探讨在将 React Web 应用程序与 IRIS 后端服务集成时如何解决 CORS 问题。
我们首先定义一个名为 Patients 的简单Schema:
Class Prototype.DB.Patients Extends %Persistent [ DdlAllowed ]
{
Property Name As %String;
Property Title As %String;
Property Gender As %String;
Property DOB As %String;
Property Ethnicity As %String;
}
您可以在表中插入一些虚假数据进行测试。我个人认为 Mockaroo 在创建假数据时非常方便。它可以让你把虚拟数据下载为 .csv 文件,直接导入管理门户。
然后,我们定义几个 REST 服务
Class Prototype.DB.RESTServices Extends %CSP.REST
{
Parameter CONTENTTYPE = "application/json";
XData UrlMap [ XMLNamespace = "http://www/intersystems.com/urlmap" ]
{
<Routes>
<Route Url = "/patients" Method="Get" Call="GetPatients"/>
<Route Url = "/patient/:id" Method="Post" Call="UpdatePatientName"/>
</Routes>
}
ClassMethod GetPatients() As %Status
{
#Dim tStatus As %Status = $$$OK
#Dim tSQL As %String = "SELECT * FROM Prototype_DB.Patients ORDER BY Name"
#Dim tStatement As %SQL.Statement = ##class(%SQL.Statement).%New()
Set tStatus = tStatement.%Prepare(tSQL)
If ($$$ISERR(tStatus)) Return ..ReportHttpStatusCode(..#HTTP400BADREQUEST, tStatus)
#Dim tResultSet As %SQL.StatementResult
Set tResultSet = tStatement.%Execute()
#Dim tPatients As %DynamicArray = []
While (tResultSet.%Next()) {
#Dim tPatient As %DynamicObject = {}
Set tPatient.ID = tResultSet.ID
Set tPatient.Name = tResultSet.Name
Set tPatient.Title = tResultSet.Title
Set tPatient.Gender = tResultSet.Gender
Set tPatient.DOB = tResultSet.DOB
Set tPatient.OrderedBy = tResultSet.OrderedBy
Set tPatient.DateOfOrder = tResultSet.DateOfOrder
Set tPatient.DateOfReport = tResultSet.DateOfReport
Set tPatient.Ethnicity = tResultSet.Ethnicity
Set tPatient.HN = tResultSet.HN
Do tPatients.%Push(tPatient)
}
Do ##class(%JSON.Formatter).%New().Format(tPatients)
Quit $$$OK
}
ClassMethod UpdatePatientName(pID As %Integer)
{
#Dim tStatus As %Status = $$$OK
#Dim tPatient As Prototype.DB.Patients = ##class(Prototype.DB.Patients).%OpenId(pID,, .tStatus)
If ($$$ISERR(tStatus)) Return ..ReportHttpStatusCode(..#HTTP404NOTFOUND, tStatus)
#Dim tJSONIn As %DynamicObject = ##class(%DynamicObject).%FromJSON(%request.Content)
Set tPatient.Name = tJSONIn.Name
Set tStatus = tPatient.%Save()
If ($$$ISERR(tStatus)) Return ..ReportHttpStatusCode(..#HTTP400BADREQUEST, tStatus)
#Dim tJSONOut As %DynamicObject = {}
Set tJSONOut.message = "patient name updated successfully"
Set tJSONOut.patient = ##class(%DynamicObject).%New()
Set tJSONOut.patient.ID = $NUMBER(tPatient.%Id())
Set tJSONOut.patient.Name = tPatient.Name
Do ##class(%JSON.Formatter).%New().Format(tJSONOut)
Quit $$$OK
}
}
然后,我们继续在管理门户上注册网络应用程序

Prototype/DB/RESTServices.cls 中定义的 API 将在 http://localhost:52773/api/prototype/* 中提供。
我使用 Next.js 创建了一个简单的前端,Next.js 是一个流行的 React 框架,它能让开发人员轻松创建服务器端渲染(SSR)的 React 应用程序。
我的前端是一个简单的表格,用于显示存储在 IRIS 中的患者数据,并提供更新患者姓名的功能。
const getPatientData = async () => {
const username = '_system'
const password = 'sys'
try {
const response: IPatient[] = await (await fetch("http://localhost:52773/api/prototype/patients", {
method: "GET",
headers: {
"Authorization": 'Basic ' + base64.encode(username + ":" + password),
"Content-Type": "application/json"
},
})).json()
setPatientList(response);
} catch (error) {
console.log(error)
}
}
看似一切准备就绪,但如果直接运行 "npm run dev",就会出现 CORS :(
当网络应用程序尝试向不同域上的资源发出请求,而服务器的 CORS 策略限制了客户端的访问,导致请求被浏览器阻止时,就会发生 CORS 错误。我们可以在前台或后台解决 CORS 问题。
首先,我们在定义 API 端点的同一个 Prototype/DB/RESTServices.cls 调度器类中添加 HandleCorsRequest 参数。
Parameter HandleCorsRequest = 1;
然后,我们在派发器类中定义 OnPreDispatch 方法来设置响应头。
ClassMethod OnPreDispatch() As %Status
{
Do %response.SetHeader("Access-Control-Allow-Credentials","true")
Do %response.SetHeader("Access-Control-Allow-Methods","GET, PUT, POST, DELETE, OPTIONS")
Do %response.SetHeader("Access-Control-Max-Age","10000")
Do %response.SetHeader("Access-Control-Allow-Headers","Content-Type, Authorization, Accept-Language, X-Requested-With")
quit $$$OK
}
在next.config.mjs文件中添加重写函数:
/** @type {import('next').NextConfig} */
const nextConfig = {
async rewrites() {
return [
{
source: '/prototype/:path',
destination: 'http://localhost:52773/api/prototype/:path'
}
]
}
};
export default nextConfig;
并将所有提取 url 从 http://127.0.0.1:52773/api/prototype/:path 更新为 `/prototype/:path
在这里,我放置了前台页面的代码:
'use client'
import { NextPage } from "next"
import { useEffect, useState } from "react"
import { Table, Input, Button, Modal } from "antd";
import { EditOutlined } from "@ant-design/icons";
import type { ColumnsType } from "antd/es/table";
import base64 from 'base-64';
import fetch from 'isomorphic-fetch'
const HomePage: NextPage = () => {
const [patientList, setPatientList] = useState<IPatient[]>([]);
const [isUpdateName, setIsUpdateName] = useState<boolean>(false);
const [patientToUpdate, setPatientToUpdate] = useState<IPatient>()
const [newName, setNewName] = useState<string>('')
const getPatientData = async () => {
const username = '_system'
const password = 'sys'
try {
const response: IPatient[] = await (await fetch("http://localhost:52773/api/prototype/patients", {
method: "GET",
headers: {
"Authorization": 'Basic ' + base64.encode(username + ":" + password),
"Content-Type": "application/json"
},
})).json()
setPatientList(response);
} catch (error) {
console.log(error)
}
}
const updatePatientName = async () => {
let headers = new Headers()
const username = '_system'
const password = 'sys'
const ID = patientToUpdate?.ID
try {
headers.set("Authorization", "Basic " + base64.encode(username + ":" + password))
const response: { message: string, patient: { ID: number, Name: string } } =
await (await fetch(`http://127.0.0.1:52773/api/prototype/patient/${ID}`, {
method: "POST",
headers: headers,
body: JSON.stringify({Name: newName})
})).json()
let patientIndex = patientList.findIndex((patient) => patient.ID == response.patient.ID)
const newPatientList = patientList.slice()
newPatientList[patientIndex] = {...patientList[patientIndex], Name: response.patient.Name}
setPatientList(newPatientList);
setPatientToUpdate(undefined);
setNewName('')
setIsUpdateName(false)
} catch (error) {
console.log(error)
}
}
const columns: ColumnsType = [
{
title: 'ID',
dataIndex: 'ID',
},
{
title: "Title",
dataIndex: "Title"
},
{
title: 'Name',
dataIndex: 'Name',
render: (value, record, index) => {
return (
<div className="flex gap-3">
<span>{value}</span>
<span className="cursor-pointer" onClick={() => {
setIsUpdateName(true)
setPatientToUpdate(record)
}}><EditOutlined /></span>
</div>
)
}
},
{
title: "Gender",
dataIndex: 'Gender'
},
{
title: "DOB",
dataIndex: "DOB"
},
{
title: "Ethnicity",
dataIndex: "Ethnicity"
},
{
title: 'HN',
dataIndex: "HN"
}
]
useEffect(() => {
getPatientData();
}, [])
return (
<>
<div className="min-h-screen">
<Modal open={isUpdateName} footer={null} onCancel={() => {
setIsUpdateName(false);
setPatientToUpdate(undefined);
setNewName('')
}}>
<div className="flex flex-col gap-5 pb-5">
<div>
<div className="text-2xl font-bold">Update name for patient {patientToUpdate?.ID} </div>
</div>
<div className="text-xl">Original Name: { patientToUpdate?.Name}</div>
<div className="flex flex-row gap-2">
<Input className="w-60" value={newName} onChange={(event) => setNewName(event.target.value)} />
<Button type="primary" onClick={updatePatientName}>OK</Button>
<Button onClick={() => {
setIsUpdateName(false)
setPatientToUpdate(undefined);
setNewName('')
}}>Cancel</Button>
</div>
</div>
</Modal>
<div className="flex justify-center py-10">
<div className="h-full w-4/5">
{patientList.length > 0 && <Table dataSource={patientList} columns={columns}/>}
</div>
</div>
</div>
</>
)
}
export default HomePage
现在访问 http://localhost:3000, 可见如下效果:

项目的Github存储库: https://github.com/xili44/iris-react-integration
感谢 Bryan (@Bryan Hoon), Julian(@Julian Petrescu) 和 Martyn (@Martyn Lee),感谢新加坡办事处提供的支持和专业知识。
想象一下那个场景。您正在 Widgets Direct 愉快地工作,这是互联网上首屈一指的小部件和小部件配件零售商。您的老板有一些毁灭性的消息,一些客户可能对他们的小部件不太满意,我们需要一个帮助台应用程序来跟踪这些投诉。为了让事情变得有趣,他希望代码占用非常小,并挑战您使用 InterSystems IRIS 以少于 150 行代码交付应用程序。这可能吗?
免责声明:本文记录了一个非常基本的应用程序的构建,为了简洁起见,省略了安全性和错误处理等细节。该应用程序仅供参考,不得用于任何生产应用。本文使用IRIS 2023.1作为数据平台,并非所描述的所有功能在早期版本中都可用
我们首先定义一个新的干净的命名空间 - 带有代码和数据数据库。虽然所有内容都可以位于 1 个数据库中,但将它们拆分以便于数据刷新。
我们的帮助台系统需要 3 个基本类:一个 Ticket 对象,它可以包含用于记录员工顾问 UserAccount 和客户联系人 UserAccount 之间交互的操作。让我们用一些基本属性来定义它们:
这篇文章介绍了使用由支持 langchain 框架的IRIS来实现问答聊天机器人,其重点介绍了检索增强生成(RAG)。
文章探讨了IRIS中的向量搜索如何在langchain-iris中完成数据的存储、检索和语义搜索,从而实现对用户查询的精确、快速的响应。通过无缝集成以及索引和检索/生成等流程,由IRIS驱动的RAG应用程序使InterSystems开发者能够利用GenAI系统的能力。
为了帮助读者巩固这些概念,文章提供了Jupyter notebook和一个完整的问答聊天机器人应用程序,以供参考。
什么是RAG以及它在问答聊天机器人中的角色
RAG,即检索增强生成,是一种通过整合超出初始训练集的补充数据来丰富语言模型(LLM)知识库的技术。尽管LLM在跨不同主题进行推理方面具有能力,但它们仅限于在特定截止日期之前训练的公共数据。为了使AI应用程序能够有效处理私有或更近期的数据,RAG通过按需补充特定信息来增强模型的知识。这是一种替代微调LLM的方法,微调可能会很昂贵。
在问答聊天机器人领域,RAG在处理非结构化数据查询中发挥着关键作用,包括两个主要组成部分:索引和检索/生成。
索引从数据源摄取数据开始,然后将其分割成更小、更易于管理的块以进行高效处理。这些分割的块随后被存储和索引,通常使用嵌入模型和向量数据库,确保在运行时能够快速准确地检索。
列式存储是 InterSystems IRIS 提供的一项较新的技术。与传统的基于行的存储不同,它通过将数据存储在列而不是行中来优化查询处理,从而实现更快的访问和检索相关信息。
下面是使用SQL创建此类表的例子
CREATETABLEtable (column1 type1, column2 type2, column3 type3) WITH STORAGETYPE = COLUMNAR -- ex 1CREATETABLEtable (column1 type1, column2 type2, column3 type3 WITH STORAGETYPE = COLUMNAR) -- ex 2我们知道InterSystems IRIS 是支持多模型的DMBS, 它可以无缝的通过关系型或对象的方式访问通一数据,
我们使用下面的方式在使用Object Script类定义的时候定义列存储:
1. 如果你想对类中的所有属性都定义为列存储,则直接通过在类中添加parameter 的方式实现:
Parameter STORAGEDEFAULT = "columnar"如前面的例子,我们使用object script定义就会是这样:
VIP:192.168.30.111,故障转移节点一(192.168.30.10),故障转移节点二(192.168.30.11),ECP地址192.168.30.100
在配置时ECP里增加数据服务器IP为【主】故障转移节点一(192.168.30.10)【文档说不能使用VIP地址】后,
如果主从切换。ECP里的数据服务器IP,会自动变换成故障转移节点二(192.168.30.11)【此时为主】吗?
如果不能,需要手动变更吗?还是不需要?
从发布InterSystems IRIS®数据平台2022.3开始,InterSystems修改了许可证强制执行机制,以包括REST和SOAP请求。由于这种变化,在升级后,使用REST或SOAP的非处理器核数的许可证环境下,用户可能会遇到更高的许可证消耗。要确定此警报是否适用于您的InterSystems许可证,请按照下面链接的FAQ中的说明进行操作。
下表总结了强制执行变更情况:
|
产品 |
许可证强制执行中是否包含REST & SOAP 请求? |
|
InterSystems Caché® |
是 |
|
InterSystems Ensemble® |
否 |
|
InterSystems IRIS, InterSystems IRIS® for Health, and Health Connect prior to 2022.3 |
否 |
|
InterSystems IRIS, InterSystems IRIS for Health, and Health Connect 2022.3 and later |
是 |
最近有某国内三甲医院为满足评级和飞行检查要求,希望提升HIS和IRIS的SQL查询效率,客户和实施工程师整理了一个慢查询的SQL列表, 有一些查询比较慢, 查询时间在甚至大于60分钟。
在我们和厂商共同努力下,对整个库的SQL查询做了优化。 下表是记录了我们在进行了大部分优化工作后的结果,您可以看到大多查询从几十分钟减少到了几十秒甚至1秒以内。其中有几个慢到几分钟的查询,最后经过细调, 也把查询耗时减少到了一分钟以内。 优化的效果还是很明显的。
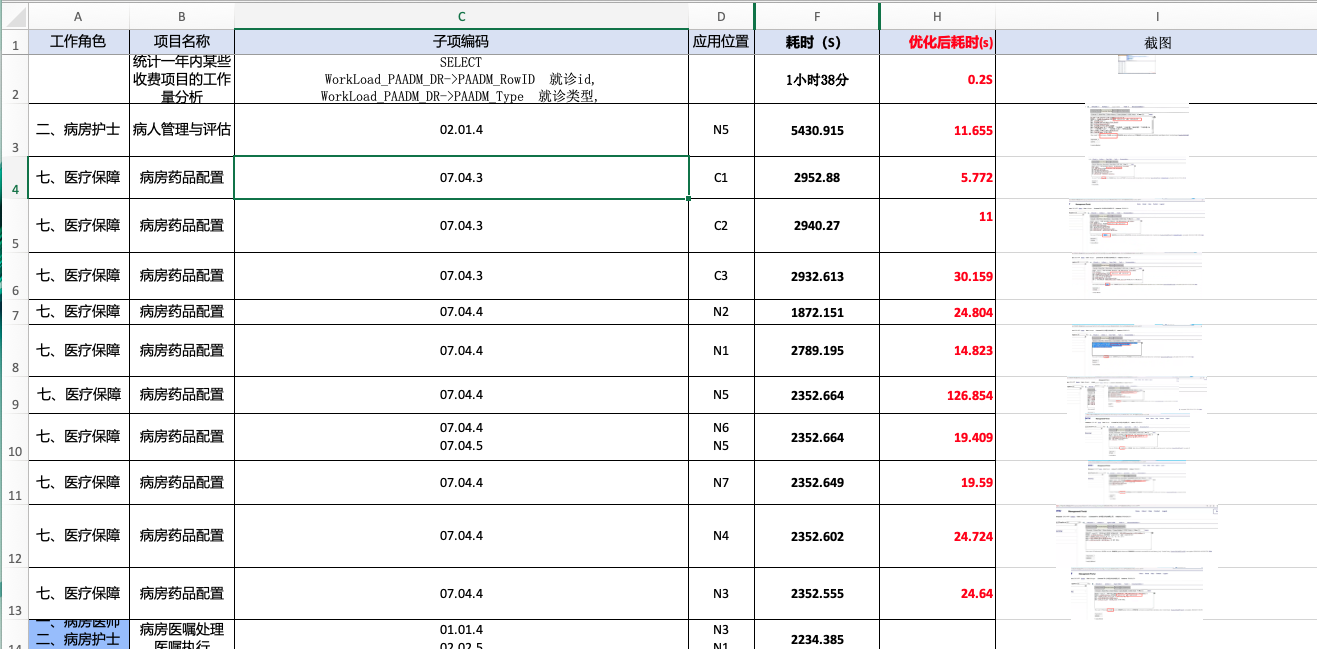
这里我分享一下操作的要点,以便给其他有同样问题的客户一个思路。
其实如果您看过我前面的帖子,应该已经有了基本的概念。我就把工作流程总结一下,其实就这么几个步骤:
步骤一:
检查硬件配置。 配置中和SQL性能相关的有这么几个: 1. 数据缓存大小,应该至少为物理内存的一半以上。 2. BBSIZE, 也就是单个进程最大的内存占用,对应不同的Caché/IRIS版本和不同的应用,这个配置有区别,但当然是越大越好,询问您的实施工程师配置是否正确。 3. 是否使用了大页内存,这个能从messages.log里看到。
步骤二
执行Tunetable。 在上面说的这个客户的系统上从来没人执行过Tunetable, 因此SQL引擎其实是没法正确工作的。执行后基本可以解决80%的慢SQL问题。时间短风险小见效快, 找个半夜业务小的时候直接在生产环境执行。
执行完之后,只剩下20-30个SQL还是太慢(超过5秒), 之后的工作我们集中在这些Case上,
步骤三
校验索引。 在生产环境上数据和索引出错非常普遍,因为有人/业务代码直接去改Global. 有的是没改对, 有的是改的过程出了问题,比如有进程没做好错误管理,出问题了没有回滚等等。SQL表数据的完整性出问题,一个结果是查的数不对, 这是显见的,还有一个是查的慢, 这个大部分人想不到。
校验索引是发现这个问题的最有效的办法。 原则上说, 所有的索引都应该执行一下,但因为时间长,影响业务,我们的做法是把相关用到的索引校验了一遍。其中发现了很多数据被修改的问题,比如必须的字段里面是空的, 要求是数字的字段里面放的是字符串等等等等。
校验索引比重新build索引要慢的多, 但对业务的影响也小的多。
步骤四
使用bitmap和bitmap extent索引。本来bitmap extent是不用人工添加的。创建任何一个bitmap索引,系统会自动添加bitmap extent。然而客户用的是SQLStorage的存储格式,修改会非常麻烦。但结果是值得的,上面所处理的绝大多数SQL, 查询时间都降到了60秒以下, 和count()相关的查询, 更是可以从1000秒直接减少到5秒以内。
步骤五
对于极少数查询时间已经提高了很多,但还是不很如人意的SQL, 我们仔细的检查查询计划,用查询关键字来做最后的优化。在好几个查询里, %PARALLEL证明是起作用的, 也就是说,本来用并行多进程查询是可以提高效率的, 但SQL引擎没自动判断出来。
除此之外, 修改SQL语句有时候是可以改善查询速度的,尤其是含子查询, IN, TOP,ORDER BY的语句, 通过检查查询计划,比较不同查询计划的执行情况,可以做出一下成功的性能改善。
欢迎讨论指正,也欢迎感兴趣的客户前来咨询我们gcdpsales@intersystems.com获取更多信息。
InterSystems 很高兴地宣布现已推出:
该版本新增了对 Ubuntu 24.04 操作系统的支持。Ubuntu 24.04 包括 Linux 内核 6.8、安全性改进以及安装程序和用户界面改进。 InterSystems IRIS IntegratedML 在 Ubuntu 24.04 上尚不可用。
此外,该版本还解决了所有平台的两个缺陷:
与往常一样,Extended Maintenance (EM) 版本附带适用于所有支持平台的经典安装包,以及 Docker 容器格式的容器镜像。有关完整列表,请参阅 "受支持的平台 "页面。
安装包可从 WRC 的 "Extended Maintenance Releases"页面获取。此外,还可在Evaluation Services上找到安装包。
SQL查询优化器一般情况下能给出最好的查询计划,但不是所有情况都这样,所以InterSystems SQL还提供了一个方式, 也就是在查询语句里加入optimize-option keyword(优化关键字), 用来人工的修改查询计划。
比如下面的查询:
SELECT AVG(SaleAmt) FROM %PARALLEL User.AllSales GROUP BY Region
其中的%PARALLEL, 就是最常用的优化关键字, 它强制SQL优化器使用多进程并行处理这个SQL。
您可以这样理解: 如果查询优化器足够聪明,那么绝大多数情况下,根本就不需要优化关键字来人工干预。因此,您也一定不奇怪在不同的IRIS/Caché版本中, 关键字的表现可能不一样。越新的版本,应该是越少用到。比如上面的%PARALLEL, 在Caché的大多数版本中, 在查询中加上它一般都能提高查询速度,而在IRIS中,尤其是2023版本以后, 同样的SQL查询语句,很大的可能查询优化器已经自动使用多进程并行查询了,不再需要用户人工干预了。
因此,先总结有关优化关键字的要点:
优化关键字主要是FROM语句中使用。 UPDATE, INSERT语句也有可以使用的关键字,比如%NOJOURAL等等, 这里我不介绍了,请各位自己查询文档。
INSERT, UPDATE的关键字常用的有:%NOCHECK %NOINDEX %NOLOCK %NOTRIGGER 等等
各个不同版本的文档中这部分内容有少许的不同。
使用查询关键字要结合阅读查询计划,需要经验的积累。用的多了, 在当前版本什么样的查询需要添加关键字就比较有数了。
最新版本的联机文档在: Specify Optimization Hints in Queries | Configure SQL Performance Options
指定查询使用多个进程并行处理。在Query Plan中您可以得到证实。有关Query Plan的阅读请看前面的帖子。
指定不用某一个或者某几个index。比如以下查询:
select min(ps_supplycost)
from %PARALLEL
%IGNOREINDEX SQLUser.supplier.SUPPLIER_PK
%IGNOREINDEX SQLUser.part.PART_PK
%IGNOREINDEX SQLUser.nation.Nation_PK
%IGNOREINDEX SQLUser.region.REGION_PK
partsupp,
supplier,
nation,
region
where p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
...
为什么要强制不用某些索引?
一个是用在测试中,经常会比较不同索引的表现。比如你原来有个复合索引,它希望试试新创建的索引是不是更好, 那么很可能您需要告诉SQL引擎不要用以前的索引了。
还有就是您发现某个索引的使用没有让查询性能变好,强制不用它结果可以使用另一个索引,从而来得到更好的查询速度。
用于测试所有可用的索引。
SQL引擎默认会在多个可用的索引中选中它判断最高效的,但这个判断不是总正确。加入%ALLINDEX会在生成查询计划前,测试所有可用的索引,以证实或者调整判断。 用到比较多的情况是有多个范围查询字句的情况。在Caché和早期IRIS版本中, 很多情况下, 使用%ALLINDEX会带来性能的提升, 尽管对所有可用索引做测试会有个额外开支.
比如以下的语句,
SELECT TOP 5 ID, Name, Age, SSN FROM %ALLINDEX Sample.Person WHERE
(:Name IS NULL or Name %STARTSWITH :Name)
AND
(:Age IS NULL or Age >= :Age)
}
在最新版的IRIS文档中, 这个关键字已经去掉了。 我自己的测试中,在2022年后的IRIS中, 它其实已经不起作用了。 但在Caché中, 非常多的使用%NOINDEX的例子。
Caché在线文档中的这段是这么说的:当绝大多数数据被条件选中(或未被选中)时,这种方法最常用。在小于 (<) 或大于 (>) 条件语句下,使用 %NOINDEX 条件级提示通常是有益的。对于“等于”条件语句,使用 %NOINDEX 条件级提示没有任何好处。对于连接条件语句,不支持在 =* 和 *= WHERE 子句外部连接中使用 %NOINDEX;而在 ON 子句连接中使用 %NOINDEX。
这是文档上的例子: E.Age<65已经包含了绝大多数的表记录,那么使用相应的索引可能不经济,因为后面取“Name"还是要直接回表操作,这样的情况, 不用E表的Age的索引,查起来还快一些。
SELECT P.Name,P.Age,E.Name,E.Age
FROM %ALLINDEX Sample.Person AS P LEFT OUTER JOIN Sample.Employee AS E
ON P.Name=E.Name
WHERE P.Age > 21 AND %NOINDEX E.Age < 65
幸好新版IRIS变的智能了。
这两个关键字都是强制查询计划中对JOIN的执行从那个表开始。如果SQL引擎没法给出正确的判断的话,人工指定是需要的。
其他的关键字包括: %FULL, %INORDER, %NOFLATTEN, %NOMERGE, %NOREDUCE, %NOSVSO, %NOTOPOPT, %NOUNIONOROPT, 等等。 不同的版本会有出入。如果您需要了解更多的关键字的使用,可以到community.intersystems.com里搜索相关的文章,比如这篇Force inner select to be executed, Query Plan Error or Correct Estimation
%SYS.Journal.Record 类有一个查询(query), List, 可以列出Journal文件中记录的数据修改历史。例如,要查询谁对global节点^QP(1,2)做过修改,可以使用如下代码。它查询Journal文件(输入参数pFilePath)中的global节点(输入参数pSearchGlobal)的操作:
InterSystems IRIS, InterSystems IRIS for Health 和 HealthShare Health Connect 的两个扩展维护版本现已发布。
✅ 2022.1.5
2022.1.5 版提供此前发布的任一 2022.1.x 版中的Bug修复。
您可以在以下页面找到详细的变更列表和升级清单:
✅ 2023.1.4
2023.1.4 版提供此前发布的任一2023.1.x 版中的Bug修复。
您可以在以下页面找到详细的变更列表和升级清单:
该软件以经典安装包和容器映像两种形式提供。有关可用安装程序和容器映像的完整列表,请参阅 Supported Platforms webpage.
当我们在设计一个需要重复使用的BP时候,往往需要开发一个可配置<call>的对象的组件,我们将call的target 设置为
@process.TargetConfigName即可实现。
下面是完整代码:
Hi 开发者们,
我们非常高兴地邀请大家参加新的 InterSystems 在线编程竞赛,此次编程大赛关注生成式AI(GenAI), 向量搜索(Vector Search )与机器学习(Machine Learning)!
🏆 InterSystems 编程大赛:Vector Search, GenAI 与 ML 🏆
时间:2024年4月22日 - 5月19日 (美国东部时间)
奖金池: $14,000
.jpg)
SQL性能监控是DBA最重要的日常工作。经常被问起:"Caché/IRIS怎么发现慢SQL"? 答案很简单: 到管理门户的SQL页面,点开如下的“SQL语句“子页, 您能看到这个命名空间的所有执行过的SQL语句,知道每个SQL语句执行了多少次,平均执行时间是多少, 被那个客户端编译的,第一次执行是那一天等等。
请看下面的截图
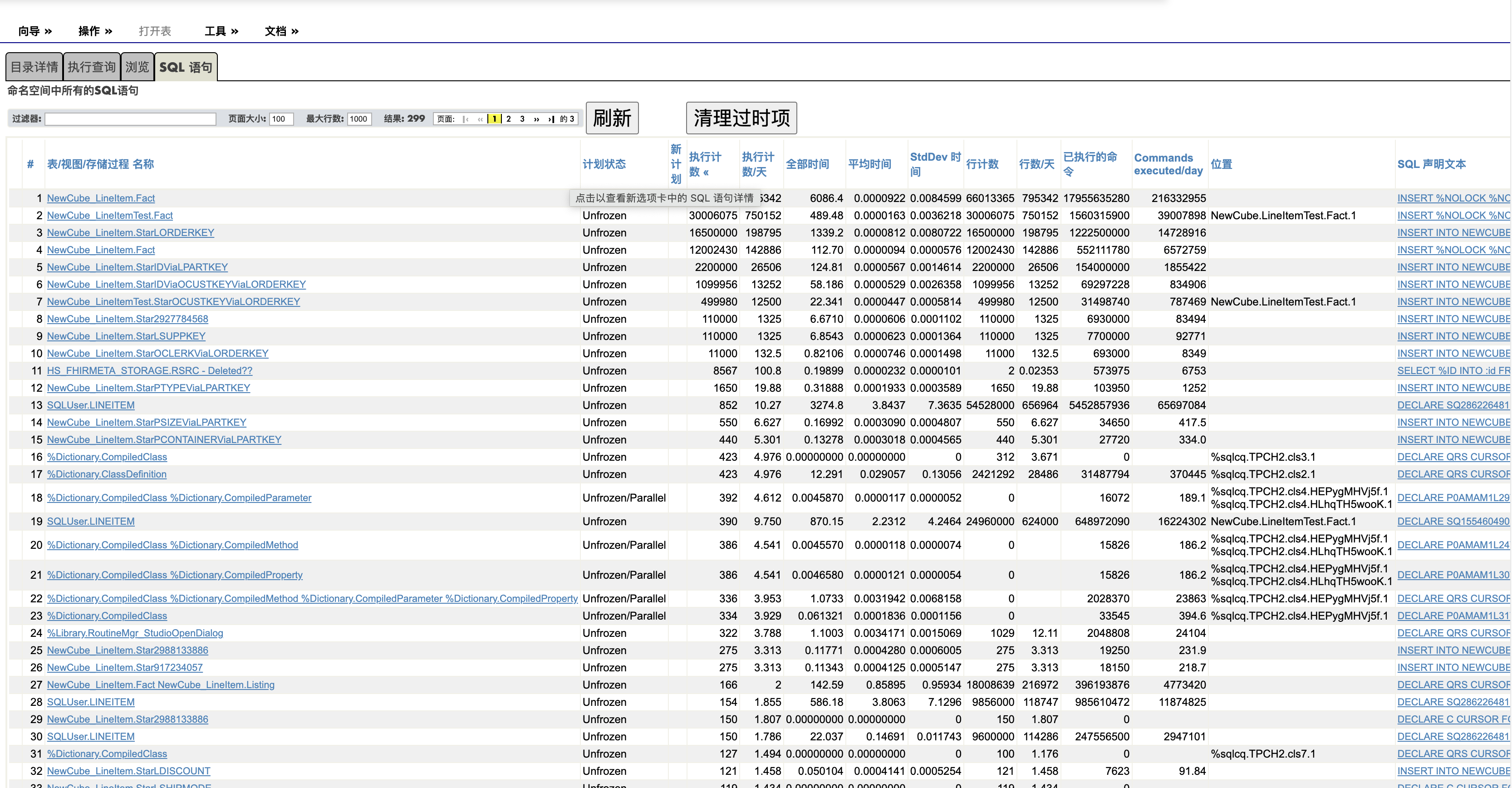
图中的各个栏目基本都不需要解释,有个别的内容在这里总结一些:
表/视图/存储过程名称:列出这个查询使用的所有的表/视图/存储过程的名字。如果你想看某个表有关的查询,可以使用上面的过滤器。
位置(Location) : 对于动态查询, 列出所使用的缓存的查询的类名,对于嵌入SQL(Embedded SQL)查询,列出使用的routine名字。
每个字段的标题栏可以用于排序,比如上图是按执行次数倒序显示的,所以前几位都是执行了很多的INSERT。 如果是日常维护查找慢SQL, 您可以按平均时间倒序显示。
计划状态: 通常是"Unfrozn"或者“Unfrozen/Parallel"。除非您需要升级或者有“Frozen Qeury Plan“的需要,您可以不关心这个栏目。
用鼠标单击上图的最左列或者最右列“SQL声明文本”, 会显示这个SQL语句的详细执行数据。 注意这个页面上的两个按钮: “导出” 和**”查询测试“**, 您可以试试它们。
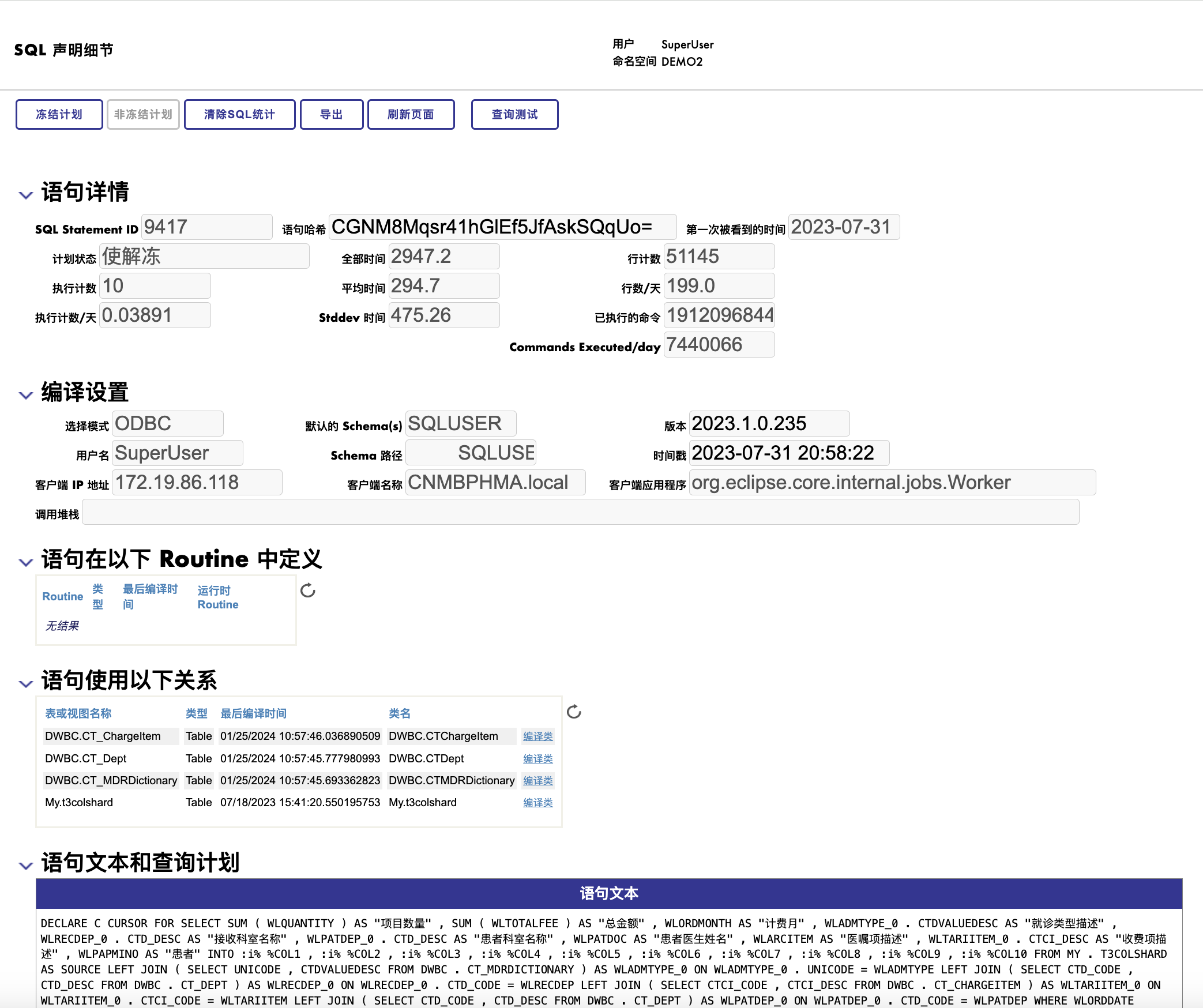
关于如何阅读“SQL Statement”, 上面说了个大概,更多的细节请阅读在线文档Analyze SQL Statements and Statistics。
最后几个要点:
SQL Statement可以导入导出
统计采集的工作一个小时执行一次,所有SQL Statement页面不一定能显示最近一个小时内的操作统计。
如果你要清理“SQL Statement"统计,或者要重新计数,或者要去掉已经"STALE"的查询统计。(如果您删除了一个表,它的记录不会从SQL Statement统计里除去), 请参考这部分操作:Stale SQL Statments。
使用SQL查询“SQL Statement"
如果您需要对SQL Statment做分析,或者设置告警或者通知,您需要学习这部分内容: Querying SQL Statements, 简单说,你需要查询这几个表:INFORMATION_SCHEMA.STATEMENTS,INFORMATION_SCHEMA.STATEMENT_LOCATIONS,INFORMATION_SCHEMA.STATEMENT_RELATIONS,INFORMATION_SCHEMA.CURRENT_STATEMENTS。
注意: 如果您在在线文档中看到“SQL Performance Analysis Toolkit的内容,它说的和上面的"SQL Statement"不是一回事,千万别搞混了。"SQL Performance Analysis Toolkit"对大部分维护人员非常不常用,我会在后面介绍。
另一个可以带来混淆的术语叫"SQL Runtime Statistics". IRIS的在线文档SQL Runtime Statistics章节说它是SQL Statment的执行步骤,而且*“The gathering of SQL runtime statistics is always on and cannot be turned off.”*。而在维护页面的"System Explorer>Tools>SQL Performance Tools>SQL Runtime Statistics"里,它其实是另一个意思。我认为都是历史原因造成的。
Hey Community,
Play the new video on InterSystems Developers Bilibili官方频道:
索引分析器工具用来分析索引的使用情况,对DBA和开发者非常有用。 他们需要知道那些查询进行了全表扫描,那些查询缺失了索引, 而那些索引从来又从来没有被用过。多余的索引降低系统性能,浪费了磁盘空间。
索引使用情况
到“管理门户”的" 系统 > SQL 性能工具 > SQL 索引分析器", 点击**“索引使用情况”**, 您将看到这样的图
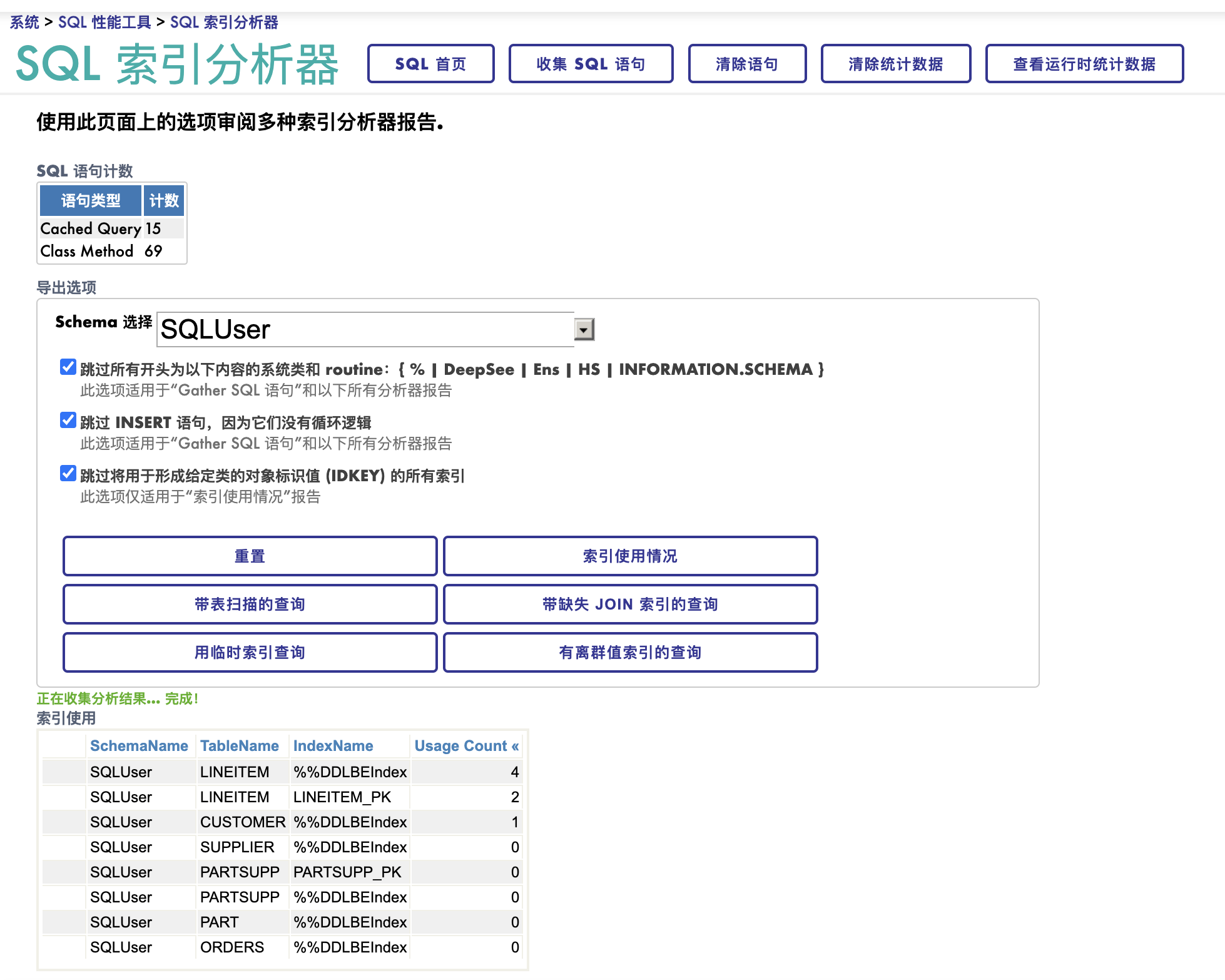
执行SQL语句查询会带来更多的灵活性。上面的查询可以写成下面这个SQL,
SELECT TableName, indexname, UsageCount
FROM %SYS_PTools.UtilSQLAnalysisDB order by usagecount desc
2016年以后的Caché版本就已经有了'索引使用情况'的查询。使用管理门户没有区别, 但SQL语句不同,使用的是比较老的类和表名,各位请参考文档。
注意上图中另外几个按钮,它们的介绍在文档的这个链接, 简单的做个翻译:
全表扫描的查询:
可识别当前命名空间中进行全表扫描的所有查询。应尽可能避免全表扫描。全表扫描并非总能避免,但如果某个表有大量全表扫描,则应检查为该表定义的索引。通常情况下,表扫描列表和临时索引列表会重叠;修复一个会移除另一个。结果集列出了从最大块计数到最小块计数的表。显示计划链接可显示语句文本和查询计划。
使用临时索引的查询:
该选项可识别当前命名空间中所有建立临时索引以解析 SQL 的查询。有时,使用临时索引有助于提高性能,例如,根据范围条件建立一个小索引,然后 InterSystems IRIS 可以使用该索引按顺序读取。有时,临时索引只是不同索引的子集,可能非常高效。其他时候,临时索引会降低性能,例如,扫描主MAP以在有条件的属性上建立临时索引。这种情况表明缺少一个所需的索引;你应该在类中添加一个与临时索引匹配的索引。结果集列出了从最大块计数到最小块计数的表。显示计划链接可显示语句文本和查询计划。
缺少JOIN索引的查询:
该选项会检查当前命名空间中所有使用JOIN的查询,并确定是否定义了支持该JOIN的索引。它将可用来支持JOIN的索引从 0(无索引)排到 4(索引完全支持JOIN)。外关联需要单向索引, INNER JOIN需要两个方向的索引。默认情况下,结果集中只包含 JoinIndexFlag < 4 的记录。 JoinIndexFlag=4 表示有一个完全支持JOIN的索引。
具有离群值Outlier索引的查询:
该选项可识别当前命名空间中所有具有异常值的查询,并确定是否定义了支持异常值的索引。它将可用来支持异常值的索引从 0(无索引)到 4(索引完全支持异常值)进行排序。默认情况下,结果集中只包含 OutlierIndexFlag < 4 的记录。 OutlierIndexFlag=4 表示有一个完全支持异常值的索引。
SQL Performance Analysis Toolkit,或者叫SQL性能分析工具,并不是给维护人员使用的。
在RIS文档里是这么说的: 这个工具包里的工具收集SQL执行的详细信息,用来找出一个查询计划的特殊问题。 使用这些信息,开发人员改善这个查询的效率。 它可以非常大的增加服务器的开销。..., 它不应该被持续执行。
要做分析,首先您需要打开一个采集“SQL runtime Statistics"的开关来收集详细信息,这个开关默认的状态是OFF。 文档里说: The SQL Performance Analysis Toolkit offers support specialists the ability to profile specific SQL statements or groups of statements.
这里的"support specialists"指的是厂家的技术支持人员。
因此,总结如下:
简单的介绍一下, 真正的使用需要参考在线文档: SQL性能分析工具(SQL Performance Analysis Toolkit)
进入*“系统资源管理器>工具>SQL性能工具>SQL运行时统计数据“*,您会看到在“setting"页面写明
当前 SQL 运行时统计数据设置为: 0 - SQL 运行时统计数据已关闭,查询代码生成中将不包含 stats-collection
下面是"更改设置"的按钮,点击后您会看到

这个工具私下被称为PTools, 当激活后,它会在SQL编译后的查询类里加入相应的代码,来跟踪Global Reference, 执行的SQL类编译的代码的行数,查询计划的每一个模块执行的时间等等。
无论您修改到什么级别的设置,1,2还是3, 您都会看到这样的提示
您正在将选项从 0 更改为 2,从先前在查询代码生成中不包括 Stats-collection 的环境启用 Stats-collection。保存更改后,您应该清除所有缓存查询,并重新编译包含嵌入式 SQL 的所有类和 routine。
也可以通过执行 %SYSTEM.SQL.PTools 命令行命令来执行。
%SYS.PTools.SQLStats在Cache 2008.1加入。它用来收集类和routine级别的metrics. 当激活后,它会在SQL编译后的查询类里加入相应的代码,来跟踪Global Reference, 执行的代码的行数,Time to Run and Number of Rows returned for the full query, or for each Module of a query.
您可以在管理门户查看查询的详细内容, 比如下面两个图, 第一个图给出了统计的3个查询,
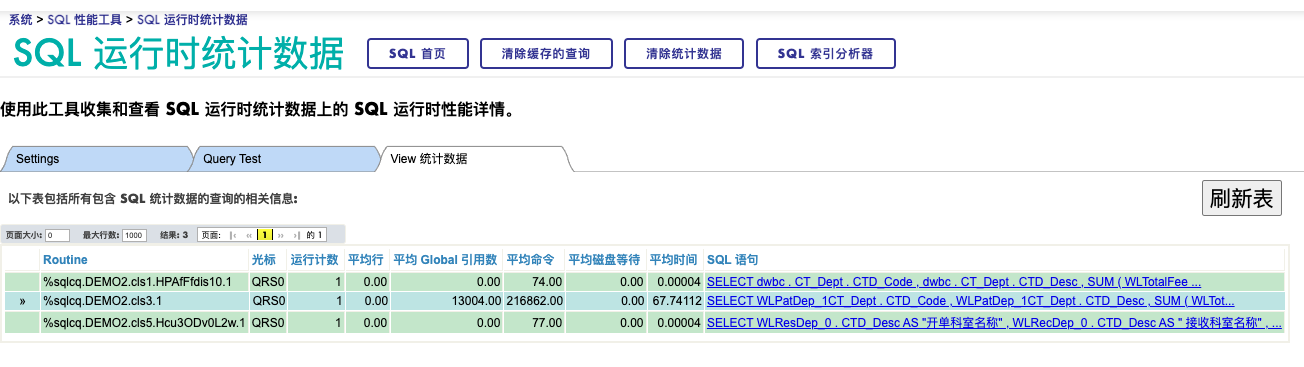
第2个图是其中一个查询的详细数据,包括每个模块执行了多长时间:
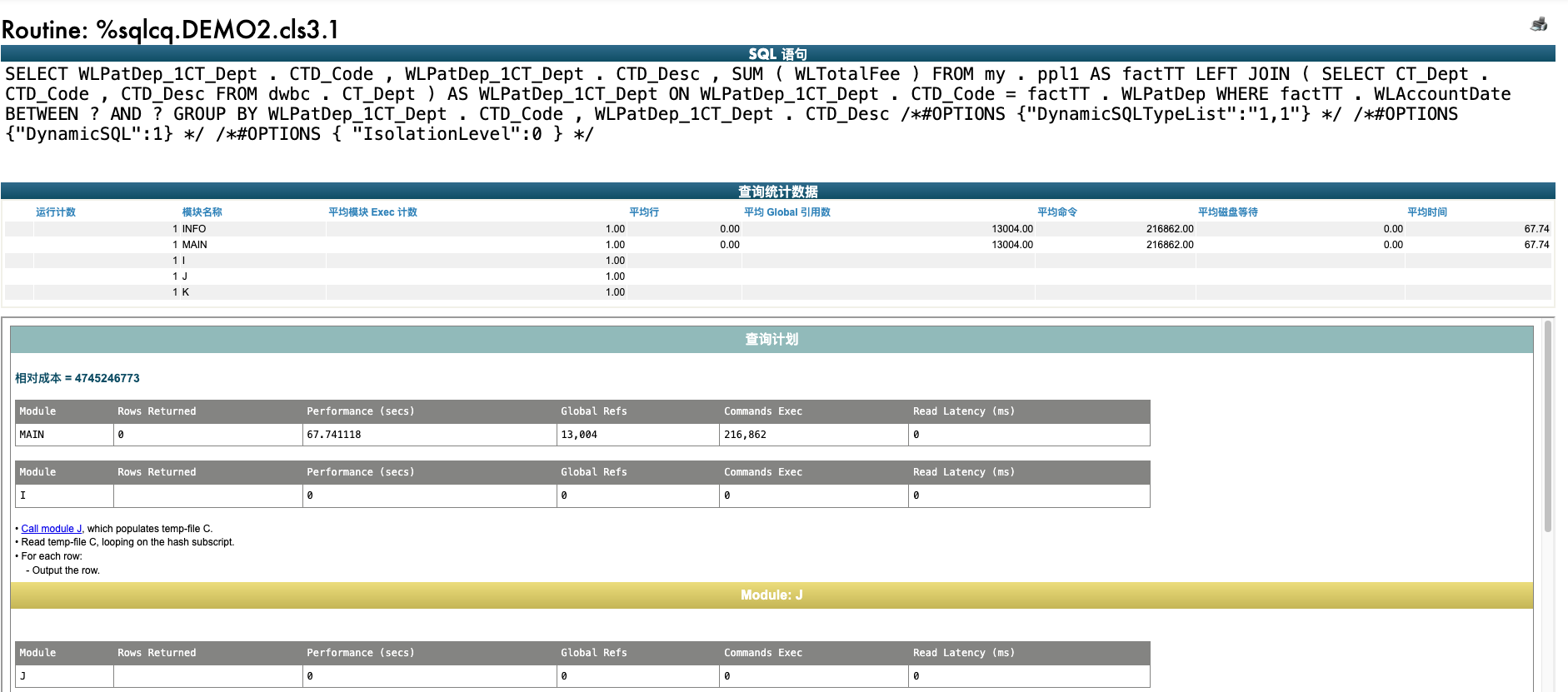
如果使用SQL, 你可以查询视图%SYS_PTools.SQLStatsView , 比如下面这个例子:
SELECT RoutineName, ModuleName, AVG(ModuleCount) AS Mod_Count,
AVG(GlobalRefs) AS Global_Refs, AVG(LinesOfCode) AS Lines_of_Code, AVG(TotalTime) AS Total_Time
FROM %SYS_PTools.SQLStatsView
WHERE NameSpace = 'SAMPLES'
GROUP BY RoutineName, ModuleName
为什么要读Query Plan, 在线文档中有句话是这么说的:
While the SQL compiler tries to make the most efficient use of data as specified by the query, sometimes the author of the query knows more about some aspect of the stored data than is evident to the compiler. In this case, the author can make use of the query plan to modify the original query to provide more information or more guidance to the query compiler.
翻译一下是这样:系统给你的查询计划并不总是最好的,如果您能对查询计划,可以人工做更精细的优化。
我们先看看读Query Plan的几个基本知识:
MAP
An SQL table is stored as a set of maps. 您有看到3种map: Master map, index map, bitmap.
# 回表读主数据,
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
# 读普通索引
Read index map DWBC.CT_MDRDictionary(T1).UniCodeIdx, using the given %SQLUPPER(UniCode), and getting T1.ID.
# 读bitmap索引
Read bitmap index My.ppl1.idxWLRecDep, looping on %SQLUPPER(WLRecDep) (with a given set of values) and bitmap chunks.
temp-file
在复杂查询时,中间过程会存在“temp-file"里。如果您的内存设置合理,通常这个"temp-file"只存在于内存,不会有IO操作。
和map一样,temp-file也是有subscription(下标),也可以有node, 您可以认为它和普通的索引是一样的global记录,通常您可以把temp-file当成一个临时的索引,只是它在内存里。
Divide and process in parallel
一个查询可以被多个进程并行处理。一种情况是用idkey分开,每一段用一个进程处理,看一个例子
• Divide extent bitmap My.column(FACTTT).%%DDLBEIndex into subranges of bitmap chunks.
• Call module A in parallel on each subrange, piping results into temp-file C.
基础教学完成。现在我们来一起看看一个真实的Query Plan。最简单的查看Query plan的方式是在IRIS管理门户的SQL页面,如果您习惯用SQL客户端, 也可以执行“EXPLAIN ..."得到查询计划。
以下的这个查询是一个主表和一个字典表的关联查询,得到一个时间段的结果,按照字典表中的科室代码分组。
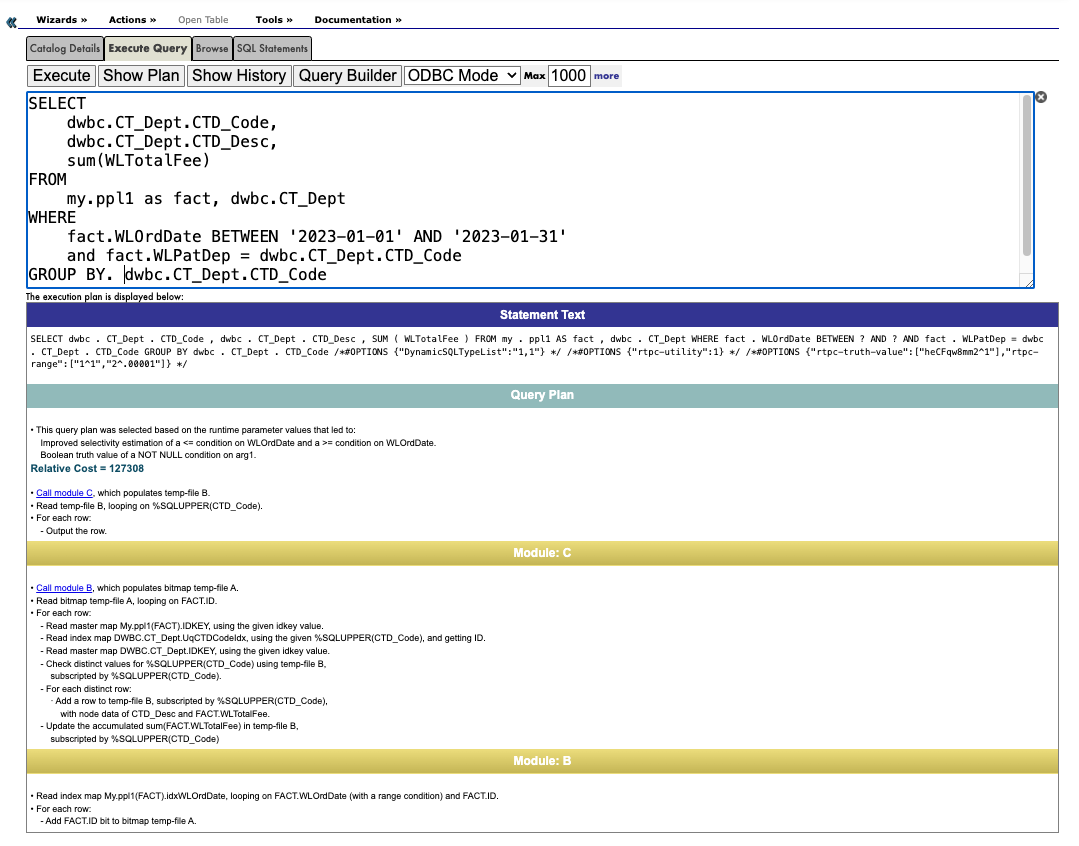
主计划部分
# SQL compiler会在查询语句上附加信息,放在 /*#OPTIONS*/块里。比如下面的“DynamicSQLTypeList”说的是内部SQL查询的类型,
# RTPC指的是Runtime Plan Choice,是一个优化的特性,这些普通的SQL用户可以先不用了解。
# 如果非要知道什么意思,可以查看链接:https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSOC_rtpc
# 这里使用了RTPC的原因是fact.WLPatDep字段有Outlier值
Statement Text
SELECT dwbc . CT_Dept . CTD_Code , dwbc . CT_Dept . CTD_Desc , SUM ( WLTotalFee )
FROM my . ppl1 AS fact LEFT JOIN dwbc . CT_Dept ON fact . WLPatDep = dwbc . CT_Dept . CTD_Code
WHERE fact . WLOrdDate BETWEEN ? AND ?
GROUP BY dwbc . CT_Dept . CTD_Code
/*#OPTIONS {"DynamicSQLTypeList":"1,1"} */
/*#OPTIONS {"rtpc-utility":1} */
/*#OPTIONS {"rtpc-truth-value":["heCFqw8mm2^1"],"rtpc-range":["2^1","3^.00001"]} */
# Query Plan
• This query plan was selected based on the runtime parameter values that led to:
Improved selectivity estimation of a <= condition on WLOrdDate and a >= condition on WLOrdDate.
Boolean truth value of a NOT NULL condition on arg1.
# 除非您比较多个不同的查询计划,这个相对花费的值没有意义
Relative Cost = 127308
#调用Module C, 它会创建一个temp-file B
• Call module C, which populates temp-file B.
# temp-file B的每一行对应一个CTD_Code,也就是科室代码, 因此,temp-file B也就是最后的结果集。
• Read temp-file B, looping on %SQLUPPER(CTD_Code).
• For each row:
- Output the row.
说明: Module C 是主处理模块,它创建一个临时文件temp-file B, 其中每一个记录对应一个科室表中的科室。
Moduel C
# 调用Module B,产生temp-file A,
Call module B, which populates bitmap temp-file A.
# 对temp-file A的每一行,也就是查询范围的每一天,得到这个时段内的所有主表ID,并且“looping on"
• Read bitmap temp-file A, looping on FACT.ID.
# 对应上面的"looping on", 因此每一行是一个FACT.ID
• For each row:
# 回表,得到这行的数据
- Read master map My.ppl1(FACT).IDKEY, using the given idkey value.
# 使用CTD_Code的值去查字典表,这里没有清楚的写明主表和字典表的关联
- Read index map DWBC.CT_Dept.UqCTDCodeIdx, using the given %SQLUPPER(CTD_Code), and getting ID.
# 得到字典表中的这行数据
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
# 确认这行记录里的CTD_Code不是NULL
- Test the NOT NULL condition on %SQLUPPER(CTD_Code).
# 如果字典表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为NULL的数据
- Generate a row padded with NULL for table DWBC.CT_Dept if no row qualified.
# 查看temp-file B的文件里有没有这个科室的值
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file B,
subscripted by %SQLUPPER(CTD_Code).
# 这里的distinct指的是科室代码, 创建的temp-file B的存储
# ^tempB(1) = ("心内科",10块人民币)
# ^tempB(2) = ("心外科",50块人民币)
# ...
- For each distinct row:
· Add a row to temp-file B, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc and FACT.WLTotalFee.
# 把temp-file B汇总,最后的结果集
- Update the accumulated sum(FACT.WLTotalFee) in temp-file B,
subscripted by %SQLUPPER(CTD_Code)
Module B
# 读标准索引idxWLOrdDate, 它的格式是^My.ppl1I("idxWLOrdDate",日期下标,表ID) = ""
• Read index map My.ppl1(FACT).idxWLOrdDate, looping on FACT.WLOrdDate (with a range condition) and FACT.ID.
# 生成一个查询范围内的OrderDate的bitmap索引,被存在一个临时文件temp-file A
• For each row:
- Add FACT.ID bit to bitmap temp-file A.
好了, 当看过一个执行计划后,您就基本可以使用执行计划来发现SQL性能的问题了。比如上面的这个计划,我们可能有两个想法:
答案是不好, 详细请看前面关于bitmap索引的文章
在查询语句里加入*%PARALLE*, 可以强迫使用多进程。
*如果您有兴趣,可以看看多进程的查询计划,当做个练习,:) *
Statement Text
SELECT dwbc . CT_Dept . CTD_Code , dwbc . CT_Dept . CTD_Desc , SUM ( WLTotalFee )
FROM %PARALLEL my . ppl1 AS fact LEFT JOIN dwbc . CT_Dept ON fact . WLPatDep = dwbc . CT_Dept . CTD_Code WHERE fact . WLOrdDate BETWEEN ? AND ? GROUP BY dwbc . CT_Dept . CTD_Code /*#OPTIONS {"DynamicSQLTypeList":"1,1"} */ /*#OPTIONS {"rtpc-utility":1} */ /*#OPTIONS {"rtpc-truth-value":["heCFqw8mm2^1"],"rtpc-range":["2^1","3^.00001"]} */
Query Plan
• This query plan was selected based on the runtime parameter values that led to:
Improved selectivity estimation of a <= condition on WLOrdDate and a >= condition on WLOrdDate.
Boolean truth value of a NOT NULL condition on arg1.
Relative Cost = 127308
• Call module J, which populates temp-file C.
• Read temp-file C, looping on %SQLUPPER(CTD_Code).
• For each row:
- Output the row.
Module: J
• Divide index map My.ppl1(FACT).idxWLOrdDate into subranges of subscript values.
• Call module A in parallel on each subrange, piping results into temp-file D.
• Read temp-file D, looping on a counter.
• For each row:
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file C,
subscripted by %SQLUPPER(CTD_Code).
- For each distinct row:
· Add a row to temp-file C, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc.
- Update the accumulated sum([value]) in temp-file C,
subscripted by %SQLUPPER(CTD_Code)
Module: A
• Call module C, which populates temp-file B.
• Read temp-file B, looping on %SQLUPPER(CTD_Code).
• For each row:
- Add a row to temp-file D, subscripted by a counter, with node data of %SQLUPPER(CTD_Code), CTD_Desc, and sum([value]).
Module: C
• Call module B, which populates bitmap temp-file A.
• Read bitmap temp-file A, looping on FACT.ID.
• For each row:
- Read master map My.ppl1(FACT).IDKEY, using the given idkey value.
- Read index map DWBC.CT_Dept.UqCTDCodeIdx, using the given %SQLUPPER(CTD_Code), and getting ID.
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
- Test the NOT NULL condition on %SQLUPPER(CTD_Code).
- Generate a row padded with NULL for table DWBC.CT_Dept if no row qualified.
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file B,
subscripted by %SQLUPPER(CTD_Code).
- For each distinct row:
· Add a row to temp-file B, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc and FACT.WLTotalFee.
- Update the accumulated sum([value]) in temp-file B,
subscripted by %SQLUPPER(CTD_Code)
Module: B
• Read index map My.ppl1(FACT).idxWLOrdDate, looping on the subrange of FACT.WLOrdDate and FACT.ID.
• For each row:
- Add FACT.ID bit to bitmap temp-file A.

人工智能不仅限于通过带有说明的文本生成图像,或通过简单的指示创建叙事。
您还可以制作图片的变体,或为已有图片添加特殊背景。
此外,您还可以获得音频转录,无论其语言和说话者的语速如何。
让我们来分析一下文件管理是如何工作的。
2024年3月26日,InterSystems数据平台全球主管Scott Gnau发文,宣布InterSystems IRIS数据平台新增了向量搜索(vector search)功能。
本文作者为Scott Gnau,InterSystems数据平台全球主管。
2023.12.31之前的所有百讲课程,总计261讲。IRIS、Cache编程知识的免费课程。
第1讲 IRISObjectScript 简介
ObjectScript 特点第2讲 初识ObjectScript程序
第3讲 语法规则
第4讲 数据类型 - 字符串
第5讲 数据类型 - 位串
第6讲 数据类型 - 数字
第7讲 数据类型 - 对象
第8讲 数据类型 - 布尔
第9讲 数据类型 - 日期
第10讲 变量
ProcedureBlock使用Global^GETPPGINFOGlobal第11讲 运算符 - 逻辑运算符
Not运算符(')第12讲 运算符 - 算术运算符
+)-)*)/)**)\)#)第13讲 关系运算符
<>>=<=='=['[]']]]']]第14讲 运算符 - 模式匹配
第15讲 运算符 - 间接寻址
$TEXT参数间接寻址第16讲 命令梗概
第17讲 命令 - 赋值命令
Set命令Kill命令
KILL影响Zkill命令New命令Merge命令第18讲 命令 - 条件命令
if,elseif,else命令IF中使用QUITIF中使用GOTO第19讲 命令 - 循环命令
For命令while命令Do While命令第20讲 命令 - 退出命令
Continue命令Quit命令Retrun命令第21讲 命令 - 输出命令
WRITE命令
WRITEWRITEZWRITE命令ZZDUMP命令ZZWRITE命令WRITE,ZWRITE,ZZDUMP,ZZWRITE异同第22讲 命令 - 调用命令
Do命令第23讲 命令 - 调用命令 - JOB
第24讲 命令 - 调用命令 - JOB - 使用多进程
第25讲 命令 - 调用命令 - JOB - 消息队列
第26讲 命令 - 调用命令 - XECUTE命令
第27讲 命令 - 调用命令 - GOTO命令
第28讲 方法 - 方法概念
RoutinesSubroutinesFunctionsLabelProceduresMethodsClassMethodsSystemFunctionsProgram第29讲 参数 - 参数传递
第30讲 嵌入式代码
HTML&html标记语法JavaScriptSQL第31讲 多维数组
第32讲 系统函数梗概
第33讲 分隔函数 $PIECE
SET $PIECE替换子字符串第34讲 截取函数 $EXTRACT
SET $EXTRACT替换子字符串DTM模式下的$EXTRACT第35讲 长度函数 $LENGTH,对齐函数 $JUSTIFY,查找函数 $FIND,反转函数 $REVERSE
第36讲 转换函数 $ZCONVERT
第37讲 替换函数 $REPLACE,$TRANSLATE,$CHANGE
$CHANGE, $REPLACE, $TRANSLATE函数第38讲 数组函数 - $LISTBUILD
SET $LISTBUILD第39讲 数组函数 - $LIST
$List错误情况SET $LIST替换元素第40讲 $LIST与$EXTRACT和$PIECE区别
第41讲 数组函数 - $LISTDATA
第42讲 数组函数 - $LISTFIND
第43讲 数组函数 - $LISTGET
第44讲 数组函数 - $LISTLENGTH
第45讲 数组函数 - $LISTNEXT
第46讲 效率 - 对比遍历取值$LISTDATA,$LIST,$LISTGET,$LISTNEXT
第47讲 数组函数 - $LISTSAME
第48讲 数组函数 - $LISTFROMSTRING,$LISTTOSTRING
第49讲 数组函数 - $LISTUPDATE
第50讲 数组函数 - $LISTVALID
第51讲 示例 - 结合所有列表函数 - 总结
第52讲 正则表达式
第53讲 正则表达式函数 - $MATCH
Unicode属性字符类型POSIX字符类型Unicode表示法
Unicode 编码范围Case模式第54讲 正则表达式函数 - $LOCATE
第55讲 正则表达式函数 - $ZSTRIP
第56讲 正则表达式类 - %Regex.Matcher
第57讲 对比 MATCH、LOCATE、ZSTRIP、%Regex.Matcher异同
第58讲 什么是宏?宏的简单使用
第59讲 .inc文件的使用
inc文件第60讲 宏预处理器 - 定义指令 - #Def1Arg、#Define、#Dim、##Continue
第61讲 宏预处理器 - 条件指令 - #If、#ElseIf、#Else、#EndIf、#IfDef、#IfNDef、#UnDef
第62讲 宏预处理器 - 编译指令 - #Execute、##Expression、##SafeExpression、##Function、##Lit
第63讲 宏预处理器 - SQL指令 - #Import、#SQLCompile Audit、#SQLCompile Mode、#SQLCompile Path、#SQLCompile Select、##SQL
#Import和#SQLCompile 区别第64讲 宏预处理器 - 其他指令 - #Include、#Show、#NoShow 、#;、##;、##Quote、##Unique
第65讲 使用系统宏
%occStatus.inc内的宏第66讲 如何使用 %Status 数据类型
第67讲 锁 - LOCK命令
第68讲 锁 - LOCK 命令的两种基本形式
LOCK命令的两种基本形式
第69讲 锁 - 独占锁
第70讲 锁 - 共享锁
第71讲 锁 - 升级锁
第72讲 锁 - 立即解锁
第73讲 锁 - 延迟解锁
第74讲 锁 - 增量锁
第75讲 锁 - 锁类型总结
第76讲 锁 - ^$LOCK 结构化系统变量
第77讲 锁 - 使用Portal管理锁
第78讲 锁 - 使用^LOCKTAB实用程序
"?",显示帮助信息:D删除一个锁。J删除进程中的所有锁。C删除系统中的所有锁。A删除所有锁。第79讲 锁 - 等待锁
第80讲 锁 - 死锁
第81讲 锁 - 注意点总结
第82讲 代码规范 - 变量
第83讲 代码规范 - 方法
第84讲 代码规范 - 类
第85讲 代码规范 - 锁
第86讲 代码规范 - 事务
第87讲 代码规范 - 陷阱
第88讲 代码规范 - 空行
第89讲 代码规范 - 格式
第90讲 代码规范 - 注释
第91讲 事务 - 什么是事务? 事务的特性
第92讲 事务 - 事务命令
TSTARTTCOMMITTROLLBACK<ROLLFAIL>的几种情况SQL命令与ObjectScript命令对照第93讲 事务 - 什么可回滚,什么不可回滚?
第94讲 事务 - SQL 事务命令
SET TRANSACTIONSTART TRANSACTIONCOMMITROLLBACKSAVEPOINT%INTRANSACTION第95讲 事务 - $TLEVEL 变量
Terminal显示事务层数SQL命令和$TLEVEL第96讲 事务 - 嵌套事务的几种情况
第97讲 事务 - 事务使用的基本示例
第98讲 事务 - 事务提交方式
IMPLICIT 显式事务(自动事务)EXPLICIT 隐式事务(关闭自动事务)NONE 没有自动事务处理第99讲 事务 - 并发事务带来的问题 - 脏读
第100讲 事务 - 并发事务带来的问题 - 丢失更新
第101讲 事务 - 并发事务带来的问题 - 不可重复读
第102讲 事务 - 并发事务带来的问题 - 幻读
第103讲 事务 - 并发事务带来的问题总结
第104讲 事务 - 隔离级别 - READ UNCOMMITTED
READ UNCOMMITTED(读取未提交数据)第105讲 事务 - 隔离级别 - READ COMMITTED
READ COMMITTED(读取已提交数据)第106讲 事务 - 隔离级别 - REPEATABLE READ
REPEATABLE READ(可重复读)第107讲 事务 - 隔离级别 - SERIALIZABLE
SERIALIZABLE(可串行化)第108讲 事务 - 隔离级别 - 总结
SNAPSHOT:快照第109讲 事务 - 查看事务日志 - 增删改对日志的影响
INSERT数据UPDATE数据DELETE数据第110讲 事务 - 通过日志恢复被删除的数据
第111讲 事务 - 开放性事务原理以及如何检测开放性事务
第112讲 错误处理 - TRY 命令
TRY - CATCH机制第113讲 错误处理 - CATCH 命令
CATCH命令有两种形式
CATCHCATCH第114讲 错误处理 - THROW 命令
THROWTHROW第115讲 错误处理 - ZTRAP 命令
第116讲 错误处理 - $ZTRAP 变量
第117讲 错误处理 - 错误处理的工作机制原理
第118讲 错误处理 - $ETRAP 变量
第119讲 错误处理 - $ZERROR 变量以及常见错误类型
$ze格式错误第120讲 错误处理 - $ECODE 变量
第121讲 错误处理 - $THROWOBJ 变量
第122讲 错误处理 - TRY - CATCH,$ZTRAP,$ETRAP区别与错误处理工具推荐
第123讲 错误处理 - 堆栈 - $STACK 变量
第124讲 错误处理 - 堆栈 - $ESTACK 变量
第125讲 错误处理 - 堆栈 - $STACK 函数
$STACK的单参数形式$STACK的两个参数形式第126讲 错误处理 - 堆栈 - 手写记录错误堆栈调用信息
第127讲 错误处理 - 堆栈 - Terminal中显示程序堆栈信息
Terminal字母代码第128讲 错误处理 - 堆栈 - %Stack 实用程序
第129讲 错误处理 - 使用系统日志并查看错误堆栈信息
第130讲 错误处理 - 使用%ERN查看应用程序错误日志
第131讲 错误处理 - 常见的返回值错误处理
^、,等。
JSON处理错误方式返回。%Status方式返回。SQLCODE方式返回错误。第132讲 错误处理 - 手写通用错误异常处理方式,包含日志,堆栈。
$Ztrap与Try-Catch双保险方式捕捉异常$Ztrap方式捕捉ZTrap抛出异常第133讲 调试 - BREAK 命令 - 基本使用
BREAK命令有三种形式BREAK第134讲 调试 - BREAK 命令 - 逐步逐行调试
BREAK Extended 参数以设置常规断点第135讲 调试 - BREAK 命令 - 中断运行中的程序
Flag参数第136讲 调试 - ZBREAK 命令 - 基本使用
ZBREAK帮助文档ZBREAKBREAK与ZBREAK的区别第137讲 调试 - ZBREAK 命令 - 使用断点和监视点
action参数值第138讲 调试 - ZBREAK 命令 - 跟踪并输出监视变量值
第139讲 调试 - ZBREAK 命令 - 将调试信息输出到日志txt
txt第140讲 调试 - 使用Stuido调试
第141讲 调试 - 使用监视窗口与监视点
第142讲 调试 - 根据进程调试
第143讲 调试 - 调试CSP页面
第144讲 - 类 - 包 - 定义
第145讲 - 类 - 包 - 包映射
第146讲 - 类 - 包 - 使用包
ObjectScript方法中引入包第147讲 类 - 参数 - 定义使用类参数
第148讲 类 - 参数 - 类参数类型
第149讲 类 - 参数 - 运行时更改类参数值与参数关键字
第150讲 类 - 方法 - 定义方法
.第151讲 类 - 方法 - 使用类方法与实例方法
第152讲 类 - 方法 - 方法关键字
Language - 指定实现语言CodeMode - 方法实现方式SqlProc - 将方法映射为存储过程SqlName - 自定义存储过程名称Abstract - 抽象方法Final - 指定方法为最终方法Private - 指定方法为私有方法第153讲 方法生成器 - 原理
第154讲 方法生成器 - 可用对象简介与示例
第155讲 方法生成器 - 父子类中的区别
第156讲 类 - 对象 - %RegisteredObject类
OREF第157讲 类 - 对象 - %RegisteredObject类常用方法
第158讲 类 - 对象 - 继承与父类类型转换
第159讲 类 - 属性 - 简介
i%PropertyName(实例变量)第160讲 类 - 属性 - 常用关键字
InitialExpression关键字 - 设置属性定义初始值Required关键字 - 设置属性字段不能为nullMultiDimensional - 关键字定义多维属性Aliases - 为属性指定别名ReadOnly - 指定属性为只读第161讲 类 - 属性 - 计算属性
SqlComputed关键字与SqlComputeCode关键字SqlColumnNumber关键字设置属性的SQL列号SqlFieldName设置SQL字段名SqlComputeOnChange关键字Transient关键字Calculated关键字第162讲 类 - 属性 - 属性访问器
IDE创建属性访问器PropGetStored() 方法 - 直接从磁盘加载数据第163讲 类 - 数据类型类 - 简介
第164讲 类 - 数据类型类 - 常用数据类型与映射
ODBC,JDBCSqlCategory映射数据类型类OdbcType映射数据类型类ClientDataType分组的数据类型类第165讲 类 - 数据类型 - 属性方法
第166讲 类 - 数据类型 - 数据类型参数
第167讲 类 - 数据类型 - 自定义数据类型类
第168讲 类 - %Persistent - 持久类简介与定义
SQL映射关系ID和OID第169讲 类 - %Persistent - Storage定义与Storage类
%Storage.Persistent存储类%Storage.SQL 存储类%Storage.Persistent与%Storage.SQL区别第170讲 类 - %Persistent - Global使用
第171讲 类 - %Persistent - 生成ID相关事项
第172讲 类 - %Persistent - 哈希Global
第173讲 类 - %Persistent - 子类拓展使用
NoExtent子类持久类第174讲 类 - %Persistent - 常用关键字
SqlTableName关键字 - 设置表名称SqlRowIdName关键字 - 设置ID列名称SqlRowIdPrivate关键字 - 隐藏ID列StorageStrategy关键字 - 指定StorageDdlAllowed关键字 - 指定是否可以使用DDL语句第175讲 类 - %Persistent - 持久类常用方法
%Save() - 保存对象%Save()方法执行逻辑详解%Save()回滚%Save() 事务%Id() - 返回持久对象ID%Oid() - 返回持久对象OID%ExistsId() - 测试持久对象ID是否存在%OpenId - 打开保存的对象%OpenId()情况分析%Reload() - 重新加载对象%DeleteId() - 根据ID删除保存的对象%Delete() 根据OID删除保存的对象%DeleteExtent() - 删除所有保存的对象%KillExtent() - 强制删除该表数据READONLY 参数 - 指定数据库为只读第176讲 类 - %Persistent - Swizzling
Swizzling - 懒加载、交错存储、重组存储第177讲 类 - %Persistent - Extent查询
第178讲 类 - %Persistent - 并发分析
concurrency 设置为 0 - 无锁。concurrency 设置为 1 - 保存后获取独占锁。concurrency 设置为 2 - 与1相同concurrency 设置为 3 - 总是获取共享锁。concurrency 设置为 4 - 总是获取独占锁。$system.OBJ.SetConcurrencyMode设置当前进程并发值第179讲 类 - %Persistent - 使用列存储
第180讲 类 - 集合 - 简介
第181讲 类 - 集合 - 使用列表集合
List集合第182讲 类 - 集合 - 使用数组集合
Array集合第183讲 类 - 集合 - 在持久类中使用基础数据列表
SQL映射list列表第184讲 类 - 集合 - 在持久类中使用对象列表
list列表第185讲 类 - 集合 - 在持久类中使用序列化列表
list列表第186讲 类 - 集合 - 在持久类中使用基础数据数组
array数组第187讲 类 - 集合 - 在持久类中使用对象数组
array数组第188讲 类 - 集合 - 在持久类中使用序列化数组
array数组第189讲 类 - 集合 - 集合属性参数
STORAGEDEFAULT参数SQLTABLENAME参数SQLPROJECTION参数第190讲 流 - 简介
第191讲 流 - 在持久类中使用流属性
第192讲 流 - 常用方法和属性
%Stream - 流常用方法和属性
Read() - 从流的当前位置开始读取指定数量的字符。Write() - 从当前位置开始,将数据追加到流中。如果位置未设置为流的末尾,则覆盖现有数据。Rewind() - 移至流的开头。NewFileName() - 为%Stream.FileCharacter或%Stream.FileBinary属性指定文件名。常用的属性
AtEnd - 当读取遇到数据源的末尾时,设置为true。Id - 在%Location指定的范围内,流实例的唯一标识符。Size - 流的当前大小(以字节或字符为单位,取决于流的类型)。第193讲 流 - 流中指定编码格式
TranslateTable - 指定读取或写入%Stream.FileCharacter流的字符集编码类型。Filename - %Stream.FileBinary流当前使用的文件名,文件名包含路径+文件名。第194讲 流 - 复制视频文件
CopyFrom() - 所有流都包含一个CopyFrom()方法,该方法复制一个流填充到另一流。LinkToFile()- 类似于Filename 属性,将文件流连接到名为Filename 的文件。如果指定的文件不存在,则在%Save()后创建。第195讲 流 - 在已有文件中追加数据
MoveToEnd() - 移动到流的末尾。%Save() - 当将流类用作独立对象时,使用%Save()方法来保存流数据。第196讲 流 - 使用gzip压缩文件
第197讲 流 - 通过嵌入式对象写入流
SQL读取流SQL写入流第198讲 流 - 使用压缩流
第199讲 %SerialObject - 序列化对象简介
第200讲 %SerialObject - 序列化对象使用
第201讲 类 - XData - 介绍使用
XDataXML示例JSON示例YAML 示例第202讲 类 - Projection映射 - 介绍使用
第203讲 类 - 关系 - 简介
第204讲 类 - 关系 - 定义一对多关系
第205讲 类 - 关系 - 删除一对多关系
第206讲 类 - 关系 - 使用关键字OnDelete
第207讲 类 - 关系 - 定义主子关系
第208讲 类 - 关系 - 删除主子关系
第209讲 类 - 关系 - 在SQL查询中使用关系
第210讲 类 - 关系 - 使用关系定义多对多关系
第211讲 类 - 关系 - 使用外键定义多对多关系
第212讲 Query - 简介与基本使用
第213讲 Query - 自定义Query基本使用
第214讲 Query - 通过%SQL.Statement,%ResultSet使用Query
%SQL.Statement对象调用Query%ResultSet对象调用Query第215讲 Query - 通过Json数据或方法动态生成Query
第216讲 Query - 通过Select Sql语句动态生成Query
第217讲 Query - 通过Query生成动态Query
第218讲 Query - 支持传统的Query并通过参数形式生成Query列
第219讲 Query - 定义通用Query,只需要实现Exceute方法
第220讲 Query - 通过Query生成Json,通过Query生成Csv
第221讲 生命周期回调方法 - 从新建到保存
回调方法列表
%OnNew()%OnAddToSaveSet()%OnBeforeSave()%OnAfterSave()%OnSaveFinally()%OnValidateObject()%OnRollBack()%OnClose()%Save回调示例
第222讲 生命周期回调方法 - 从打开到删除
%OnOpen()%OnOpenFinally()%OnReload()%OnConstructClone()%OnAfterDelete()%OnDelete()%OnDeleteFinally()%Delete示例第223讲 生命周期回调方法 - 索引
%OnBeforePurgeIndices()%OnAfterPurgeIndices()%OnBeforeBuildIndices()%OnAfterBuildIndices()%BuildIndices示例第224讲 填充工具 - Populate实用程序简介
%Library.PopulateUtils填充方法列表Populate()方法简介第225讲 填充工具 - 集合属性
第226讲 填充工具 - 引用序列化对象的属性
第227讲 填充工具 - 关系
第228讲 填充工具 - 引用持久对象的属性
第229讲 填充工具 - 为非集合属性指定POPSPEC参数
第230讲 填充工具 - 为列表属性指定POPSPEC参数
第231讲 填充工具 - 为数组属性指定POPSPEC参数
第232讲 填充工具 - 通过SQL表指定POPSPEC参数
第233讲 填充工具 - 基于另外一个属性生成
第234讲 动态派发
%DispatchMethod()%DispatchClassMethod()%DispatchGetProperty()%DispatchSetProperty()%DispatchSetMultidimProperty()第235讲 动态派发 - 动态属性示例
第236讲 JSON - 简介
JSON简介JSON简单使用示例
第237讲 JSON - 使用JSON文本构造器
JSON构造函数创建动态实体JSON文本构造器第238讲 JSON - 使用动态表达式和点语法
第239讲 JSON - 使用 %Set(), %Get(), %Remove()
%Set(), %Get(), %Remove()%Set()、%Get()和%Remove()以编程方式指定JSON的键和值%Get()和%Remove()检索嵌套的动态实体第240讲 JSON - 链式动态实体方法
第241讲 JSON - 错误处理
第242讲 JSON - 序列化与反序列化
JSON字符串JSON字符串反序列化为动态对象JSON字符串之间进行转换第243讲 JSON - 克隆JSON对象
第244讲 JSON - 迭代JSON
%GetNext()遍历动态实体第245讲 JSON - 解决JSON字符串超长问题
Global字符流Json写入文件流第246讲 JSON - 动态数组中的null值
第247讲 JSON - 在数组中使用%Remove
第248讲 JSON - 使用%Size()的数组迭代
第249讲 JSON - 使用%IsDefined()测试有效值
第250讲 JSON - 在动态数组中使用%Push和%Pop
%Push()和%Pop()构建一个数组并销毁第251讲 JSON - 处理JSON 数据类型
%GetTypeOf()返回值的数据类型oref第252讲 JSON - 用%Set()或%Push()重写覆盖默认数据类型
%Set()或%Push()重写覆盖默认数据类型第253讲 JSON - 解析JSON空值和布尔值
JSON空值和布尔值第254讲 JSON - 解决Null、空字符串和未赋值
Null、空字符串和未赋值第255讲 JSON - 动态实体方法概览
创建、读取、更新、删除
%Set() 可以更改现有动态实体成员属性或元素的值,也可以创建新成员并为其赋值。%Remove() 删除现有成员。%Get() 检索成员的值。迭代数组
%GetIterator() 返回一个迭代器,其中包含指向动态实体每个成员的指针。%GetNext() 返回迭代器标识的成员的键和值,并将光标移到下一个成员。%Size() 返回成员数包括数组中未分配的元素。%IsDefined() 测试成员是否具有指定的值。堆栈功能
%Push() 将新元素添加到动态数组的末尾。%Pop() 删除数组的最后一个元素并返回其值。这些方法不适用于动态对象,因为对象属性不是按可预测的顺序存储的。序列化和反序列化
%FromJSON() 将JSON字符串转换为动态实体。%FromJSONFile()%ToJSON() 将动态实体序列化为规范JSON字符串。数据类型
%GetTypeOf() 返回一个字符串,该字符串指示指定成员值的数据类型。%Set()和%Push()提供一个可选的第三个参数来显式地指定值的数据类型。第256讲 JSON - %JSON.Adaptor - 简介,对象与JSON互转
%JSON.AdaptorJSON字符串JSON字符串导入到对象中第257讲 JSON - %JSON.Adaptor - 使用参数映射
%JSONFIELDNAME%JSONINCLUDE%JSONIGNOREINVALIDFIELD%JSONIGNORENULL%JSONNULL%JSONREFERENCE%JSONIGNOREINVALIDFIELD第258讲 JSON - %JSON.Adaptor - 使用XData映射块
第259讲 JSON - %JSON.Adaptor - 格式化JSON
JSON第260讲 %Dictionary - 是什么怎么用
第261讲 %Dictionary - 类成员对应哪些表