
在本节中,我们将探讨如何在 IRIS 中使用 Python 作为主要编程语言,在使用 Python 编写应用程序逻辑的同时仍能利用 IRIS 的强大功能。
使用方法 (irispython)
我们先来介绍官方操作方式,即使用 irispython 解释器。
您可以使用 irispython 解释器直接在 IRIS 中运行 Python 代码。 这样,您可以编写 Python 代码,并在 IRIS 应用程序的运行环境中执行相应代码。
什么是 irispython?
irispython 是位于 IRIS 安装目录 (<installation_directory>/bin/irispython) 下的 Python 解释器,用于在 IRIS 的运行环境中执行 Python 代码。
它的功能包括:
- 设置
sys.path,以包含 IRIS Python 库和模块。- 此操作通过
<installation_directory>/lib/python/iris_site.py中的site.py文件执行。 - 如需了解详情,请参阅模块文章 Python 模块简介。
- 此操作通过
- 允许您导入
iris模块,这是一个特殊模块,用于访问 IRIS 功能,例如实现任何 ObjectScript 类与 Python 的双向桥接。 - 修复权限问题并动态加载 iris 内核库。
irispython 使用示例
您可以通过命令行运行 irispython 解释器:
<installation_directory>/bin/irispython
我们来运行一个简单的示例:
# src/python/article/irispython_example.py
import requests
import iris
def run():
response = requests.get("https://2eb86668f7ab407989787c97ec6b24ba.api.mockbin.io/")
my_dict = response.json()
for key, value in my_dict.items():
print(f"{key}: {value}") # print message: Hello World
return my_dict
if __name__ == "__main__":
print(f"Iris version: {iris.cls('%SYSTEM.Version').GetVersion()}")
run()
您可以使用 irispython解释器运行此脚本:
<installation_directory>/bin/irispython src/python/article/irispython_example.py
您将看到如下输出:
Iris version: IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2025.1 (Build 223U) Tue Mar 11 2025 18:23:31 EDT
message: Hello World
此例展示了如何使用 irispython 解释器在 IRIS 的运行环境中执行 Python 代码。
优点
- Python 优先:您可以使用 Python 编写应用程序逻辑,这样,您可以利用 Python 的功能和库。
- IRIS 集成:您可以轻松将 Python 代码与 IRIS 功能相集成。
缺点
- 调试受限:在
irispython中调试 Python 代码并不像在专用 Python 环境中那样简单直接。- 这并不是说无法进行调试,而是并不像在专用 Python 环境中那样简单。
- 如需了解详情,请参阅补充部分。
- 虚拟环境:在
irispython中为 Python 代码搭建虚拟环境比较困难。- 这并不是说无法搭建,只是操作起来比较困难。因为默认情况下,虚拟环境会查找名为
python或python3的解释器,而 IRIS 中的情况并非如此。 - 如需了解详情,请参阅补充部分。
- 这并不是说无法搭建,只是操作起来比较困难。因为默认情况下,虚拟环境会查找名为
结论
总的来说,使用 irispython 解释器让您既可以利用 Python 编写应用程序逻辑,又能利用 IRIS 的强大功能。 不过,这种方式也存在调试和虚拟环境搭建方面的限制。
使用 WSGI
在本节中,我们将探讨如何使用 WSGI(Web 服务器网关接口)在 IRIS 中运行 Python Web 应用程序。
WSGI 是 Web 服务器与 Python Web 应用程序或框架之间的标准接口。 利用 WSGI,您可以在 Web 服务器环境中运行 Python Web 应用程序。
IRIS 支持 WSGI,这意味着您可以在 IRIS 中使用内置的 WSGI 服务器运行 Python Web 应用程序。
使用方法
要在 IRIS 中使用 WSGI,您需要创建 WSGI 应用程序,并向 IRIS Web 服务器注册此应用程序。
如需了解详情,请参阅官方文档。
WSGI 使用示例
有关完整模板,请参见此处:iris-flask-example。
优点
- Python Web 框架:您可以使用流行的 Python Web 框架(如 Flask 或 Django)来构建 Web 应用程序。
- IRIS 集成:您可以轻松将 Python Web 应用程序与 IRIS 功能相集成。
缺点
- 复杂程度:构建 WSGI 应用程序会比直接在 Python Web 框架中使用
uvicorn或gunicorn复杂一些。
结论
总的来说,在 IRIS 中使用 WSGI 让您既可以利用 Python 构建功能强大的 Web 应用程序,又能利用 IRIS 的功能。
DB-API
在本节中,我们将探讨如何使用 Python DB-API 与 IRIS 数据库进行交互。
Python DB-API 是 Python 中用于连接数据库的标准接口。 利用此接口,您可以执行 SQL 查询,并从数据库中检索结果。
使用方法
您可以使用 pip 进行安装:
pip install intersystems-irispython
随后,您可以使用 DB-API 连接 IRIS 数据库并执行 SQL 查询。
DB-API 使用示例
它的使用方法与其他所有 Python DB-API 相同,示例如下:
# src/python/article/dbapi_example.py
import iris
def run():
# Connect to the IRIS database
# Open a connection to the server
args = {
'hostname':'127.0.0.1',
'port': 1972,
'namespace':'USER',
'username':'SuperUser',
'password':'SYS'
}
conn = iris.connect(**args)
# Create a cursor
cursor = conn.cursor()
# Execute a query
cursor.execute("SELECT 1")
# Fetch all results
results = cursor.fetchall()
for row in results:
print(row)
# Close the cursor and connection
cursor.close()
conn.close()
if __name__ == "__main__":
run()
您可以使用任何 Python 解释器运行此脚本:
python3 /irisdev/app/src/python/article/dbapi_example.py
您将看到如下输出:
(1,)
优点
- 标准接口:DB-API 提供用于连接数据库的标准接口,因此可以轻松切换不同的数据库。
- SQL 查询:您可以使用 Python 执行 SQL 查询,并从数据库检索结果。
- 远程访问:您可以使用 DB-API 连接到远程 IRIS 数据库。
缺点
- 功能有限:DB-API 仅可通过 SQL 访问数据库,因此,您无法使用高级 IRIS 数据库功能,如执行 ObjectScript 或 Python 代码。
备选方案
还提供社区版 DB-API,参见此处:intersystems-irispython-community。
该版本能更好地支持 SQLAlchemy、Django、langchain,以及其他使用 DB-API 的 Python 库。
如需了解详情,请参阅 补充部分。
结论
总的来说,将 Python DB-API 与 IRIS 结合使用能够让您构建功能强大的应用程序,实现与数据库的无缝交互。
Notebook
现在,我们已了解如何在 IRIS 中使用 Python,接下来我们将探讨如何将 Jupyter Notebooks 与 IRIS 结合使用。
Jupyter Notebooks 是交互式编写和执行 Python 代码的绝佳方式,并且可与 IRIS 结合使用,以充分利用 IRIS 的功能。
使用方法
要在 IRIS 中使用 Jupyter Notebooks,您需要安装 notebook 和 ipykernel 这两个软件包:
pip install notebook ipykernel
然后,您可以创建新的 Jupyter Notebook 并选择 Python 3 内核。
Notebook 使用示例
您可以创建新的 Jupyter Notebook 并编写以下代码:
# src/python/article/my_notebook.ipynb
# Import the necessary modules
import iris
# Do the magic
iris.system.Version.GetVersion()
您可以使用 Jupyter Notebook 运行此 notebook:
jupyter notebook src/python/article/my_notebook.ipynb
优点
- 交互式开发:利用 Jupyter Notebooks,您可以交互式编写和执行 Python 代码,非常适合数据分析和探索。
- 丰富的输出:您可以直接在 Notebook 中显示丰富的输出,如图表和表格。
- 文档:您可以在代码旁添加文档和说明。
缺点
- 设置有难度:设置将 Jupyter Notebooks 与 IRIS 结合使用存在一定的难度,特别是对于内核配置而言。
结论
总的来说,将 Jupyter Notebooks 与 IRIS 结合使用可以交互式编写和执行 Python 代码,同时利用 IRIS 的功能。 不过,设置起来存在一定的难度,特别是对于内核配置而言。
补充部分
从本节开始,我们将探讨一些与在 IRIS 中使用 Python 相关的高级主题,例如远程调试 Python 代码、使用虚拟环境等。
以下大部分主题均未获得 InterSystems 的官方支持,但如果您要在 IRIS 中使用 Python,了解相关内容会提供很大的帮助。
使用原生解释器(无 irispython)
在本节中,我们将探讨如何使用原生 Python 解释器代替 irispython 解释器。
这样一来,您可以直接使用虚拟环境,并使用您习惯的 Python 解释器。
使用方法
要使用原生 Python 解释器,您需要在机器本地安装 IRIS,并需要安装 iris-embedded-python-wrapper 软件包。
您可以使用 pip 进行安装:
pip install iris-embedded-python-wrapper
接下来,您需要设置一些环境变量指向 IRIS 安装目录:
export IRISINSTALLDIR=<installation_directory>
export IRISUSERNAME=<username>
export IRISPASSWORD=<password>
export IRISNAMESPACE=<namespace>
然后,您可以使用您的原生 Python 解释器运行 Python 代码:
python3 src/python/article/irispython_example.py
# src/python/article/irispython_example.py
import requests
import iris
def run():
response = requests.get("https://2eb86668f7ab407989787c97ec6b24ba.api.mockbin.io/")
my_dict = response.json()
for key, value in my_dict.items():
print(f"{key}: {value}") # print message: Hello World
return my_dict
if __name__ == "__main__":
print(f"Iris version: {iris.cls('%SYSTEM.Version').GetVersion()}")
run()
如需了解详情,请参阅 iris-embedded-python-wrapper 文档。
优点
- 虚拟环境:您可以将虚拟环境与原生 Python 解释器结合使用,从而可以更加轻松地管理依赖项。
- 熟悉的工作流:您可以使用习惯的 Python 解释器,从而可以更轻松地与现有工作流相集成。
- 调试:可以使用您喜欢的 Python 调试工具(如
pdb或ipdb)在 IRIS 中调试 Python 代码。
缺点
- 设置的复杂程度:设置环境变量和
iris-embedded-python-wrapper软件包可能会比较复杂,特别是对于初学者来说。 - 未获官方支持:此方式未获 InterSystems 的官方支持,因此您可能遇到文档中未记录或不受支持的问题。
DB-API 社区版
在本节中,我们将探讨 GitHub 上提供的社区版 DB-API。
使用方法
您可以使用 pip 进行安装:
pip install sqlalchemy-iris
此代码将安装社区版 DB-API。
或使用特定版本:
pip install https://github.com/intersystems-community/intersystems-irispython/releases/download/3.9.3/intersystems_iris-3.9.3-py3-none-any.whl
然后,您可以使用 DB-API 连接 IRIS 数据库,并执行 SQL 查询或其他任何使用 DB-API 的 Python 代码,如 SQLAlchemy、Django、langchain、pandas 等。
DB-API 使用示例
它的使用方法与其他所有 Python DB-API 相同,示例如下:
# src/python/article/dbapi_community_example.py
import intersystems_iris.dbapi._DBAPI as dbapi
config = {
"hostname": "localhost",
"port": 1972,
"namespace": "USER",
"username": "_SYSTEM",
"password": "SYS",
}
with dbapi.connect(**config) as conn:
with conn.cursor() as cursor:
cursor.execute("select ? as one, 2 as two", 1) # second arg is parameter value
for row in cursor:
one, two = row
print(f"one: {one}")
print(f"two: {two}")
您可以使用任何 Python 解释器运行此脚本:
python3 /irisdev/app/src/python/article/dbapi_community_example.py
也可以使用 sqlalchemy:
from sqlalchemy import create_engine, text
COMMUNITY_DRIVER_URL = "iris://_SYSTEM:SYS@localhost:1972/USER"
OFFICIAL_DRIVER_URL = "iris+intersystems://_SYSTEM:SYS@localhost:1972/USER"
EMBEDDED_PYTHON_DRIVER_URL = "iris+emb:///USER"
def run(driver):
# Create an engine using the official driver
engine = create_engine(driver)
with engine.connect() as connection:
# Execute a query
result = connection.execute(text("SELECT 1 AS one, 2 AS two"))
for row in result:
print(f"one: {row.one}, two: {row.two}")
if __name__ == "__main__":
run(OFFICIAL_DRIVER_URL)
run(COMMUNITY_DRIVER_URL)
run(EMBEDDED_PYTHON_DRIVER_URL)
您可以使用任何 Python 解释器运行此脚本:
python3 /irisdev/app/src/python/article/dbapi_sqlalchemy_example.py
您将看到如下输出:
one: 1, two: 2
one: 1, two: 2
one: 1, two: 2
优点
- 更好的支持:对 SQLAlchemy、Django、langchain 以及其他使用 DB-API 的 Python 库提供更好的支持。
- 依托于社区:它由社区维护,这意味着随着时间的推移,可能会对其进行更新和改进。
- 兼容性:它兼容官方 InterSystems DB-API,因此您可以在官方版与社区版之间轻松切换。
缺点
- 速度:社区版的优化程度可能不如正式版高,某些场景下可能会导致速度变慢。
在 IRIS 中调试 Python 代码
在本节中,我们将探讨如何在 IRIS 中调试 Python 代码。
默认情况下,无法在 IRIS 中调试 Python 代码(在包含语言标签或 %SYS.Python 的 objectscript 中),但可以通过社区解决方案在 IRIS 中调试 Python 代码。
使用方法
先安装 IoP 基于 Python 的互操作性:
pip install iris-pex-embedded-python
iop --init
此代码将安装 IoP 和新的 ObjectScript 类,以便您可以在 IRIS 中调试 Python 代码。
然后,您可以使用 IOP.Wrapper 类包装 Python 代码并实现调试。
Class Article.DebuggingExample Extends %RegisteredObject
{
ClassMethod Run() As %Status
{
set myScript = ##class(IOP.Wrapper).Import("my_script", "/irisdev/app/src/python/article/", 55550) // Adjust the path to your module
Do myScript.run()
Quit $$$OK
}
}
然后,向 launch.json 文件添加以下配置,将 VsCode 配置为使用 IoP 调试器:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python in IRIS",
"type": "python",
"request": "attach",
"port": 55550,
"host": "localhost",
"pathMappings": [
{
"localRoot": "${workspaceFolder}/src/python/article",
"remoteRoot": "/irisdev/app/src/python/article"
}
]
}
]
}
现在,您可以运行用于导入 Python 模块的 ObjectScript 代码,然后将 VsCode 中的调试器关联到端口 55550。
您可以使用以下命令运行此脚本:
iris session iris -U IRISAPP '##class(Article.DebuggingExample).Run()'
然后,您可以在 Python 代码中设置断点,调试器将在这些断点处停止执行,以便您检查变量并单步执行代码。
远程调试实际运作视频(针对 IoP,但原理是相同的):
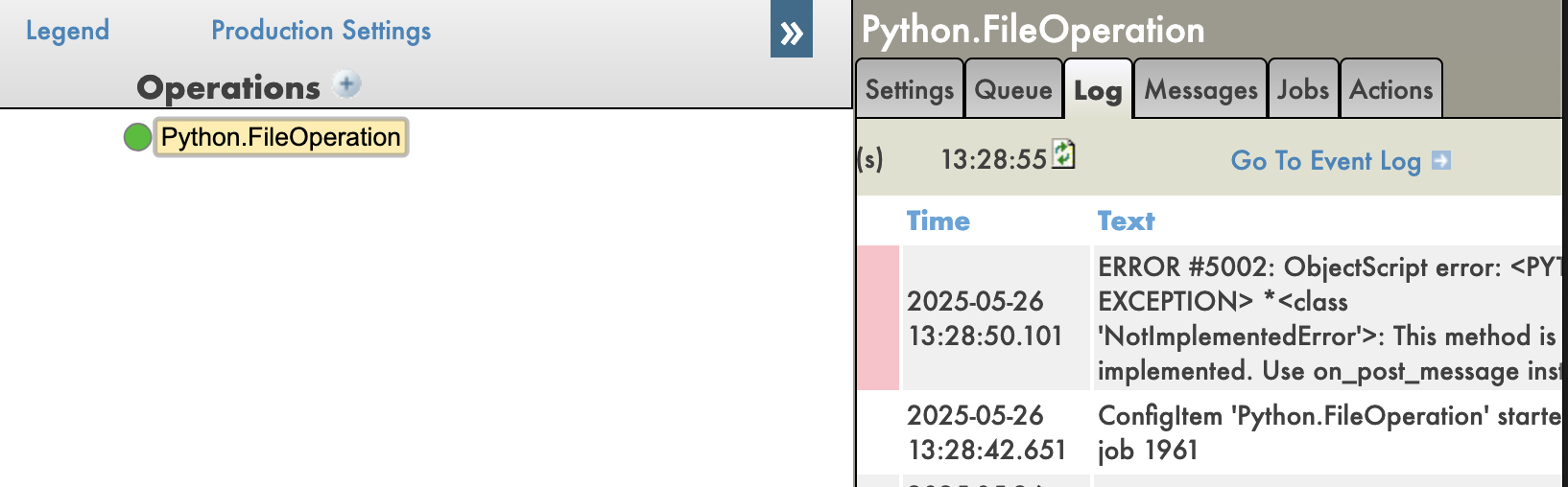
Python 代码中还提供回溯信息,这对调试非常有用。
启用回溯时:
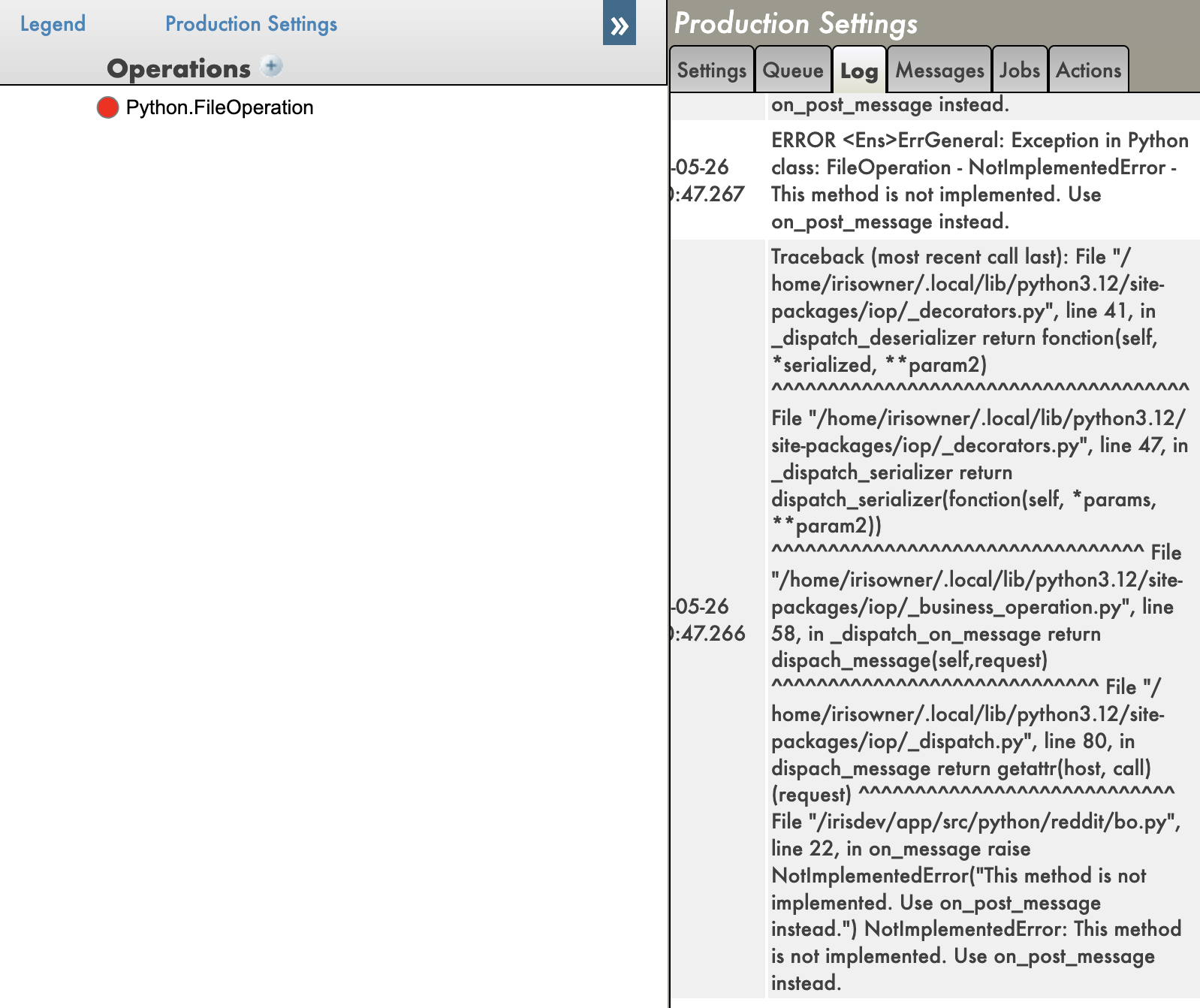
禁用回溯时:
优点
- 远程调试:您可以远程调试在 IRIS 中运行的 Python 代码,在我看来,这是一项革命性的功能。
- Python 调试功能:您可以使用所有 Python 调试功能,例如断点、变量检查和单步执行代码。
- 回溯:您可以看到 Python 代码中错误的完整回溯信息,这对调试非常有用。
缺点
- 设置的复杂程度:设置 IoP 和调试器可能会比较复杂,特别是对于初学者来说。
- 社区解决方案:该解决方案属于社区解决方案,因此可能不像官方解决方案那样稳定,文档也可能不完善。
结论
总的来说,在 IRIS 中调试 Python 代码可以通过 IoP 社区解决方案来实现,借助该解决方案,您可以使用 Python 调试器调试在 IRIS 中运行的 Python 代码。 不过,此解决方案需要执行一些设置操作,并可能不像官方解决方案一样稳定。
IoP(基于 Python 的互操作性)
在本节中,我们将探讨 IoP(基于 Python 的互操作性)解决方案,利用该解决方案,您可以使用 Python 优先的方式在 IRIS 中运行 Python 代码。
我开发这个解决方案已经有一段时间了,可以说它是我的心血之作,该解决方案尝试解决或改善我们在本系列文章中提到的所有问题。
IoP 的要点:
- Python 优先:您可以使用 Python 编写应用程序逻辑,这样,您可以利用 Python 的功能和库。
- IRIS 集成:您可以轻松将 Python 代码与 IRIS 功能相集成。
- 远程调试:您可以远程调试在 IRIS 中运行的 Python 代码。
- 回溯:您可以看到 Python 代码中错误的完整回溯信息,这对调试非常有用。
- 虚拟环境:支持虚拟环境功能,因此您可以更加轻松地管理依赖项。
要详细了解 IoP,您可以查阅官方文档。
然后,您可以阅读以下文章详细了解 IoP:
- 介绍 IoP 的第一篇文章。
- iop 命令行
- 异步支持
- dtl 和 jsonschema 支持
🐍❤️如您所见,通过 IoP 这一功能强大的方法,我们可以将 Python 与 IRIS 相集成,从而可以更轻松地开发和调试应用程序。
您无需继续使用 irispython,也不必手动设置 sys.path,而是可以使用虚拟环境,并且可以调试在 IRIS 中运行的 Python 代码。
结论
希望大家喜欢这一系列关于在 IRIS 中使用 Python 的文章。
如果您对这一系列的文章有任何疑问或反馈,请随时联系我。
祝您在 IRIS 中使用 Python 时一切顺利!
.png)