第十四章 使用SQL Shell界面(一)
执行SQL的其他方式
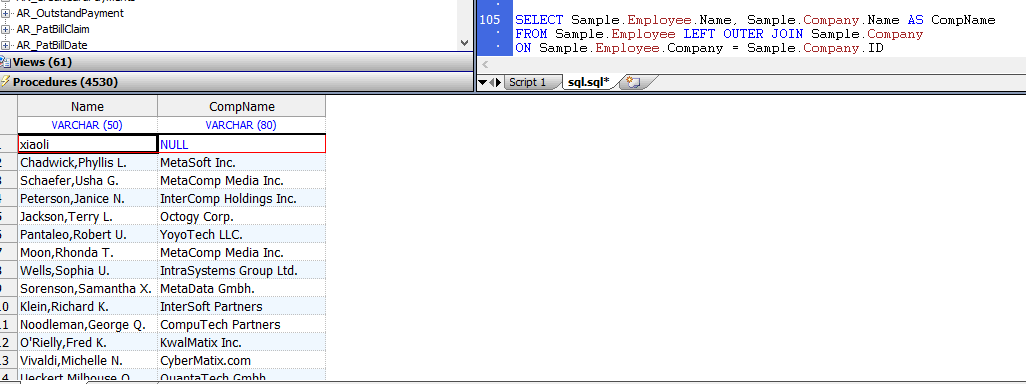
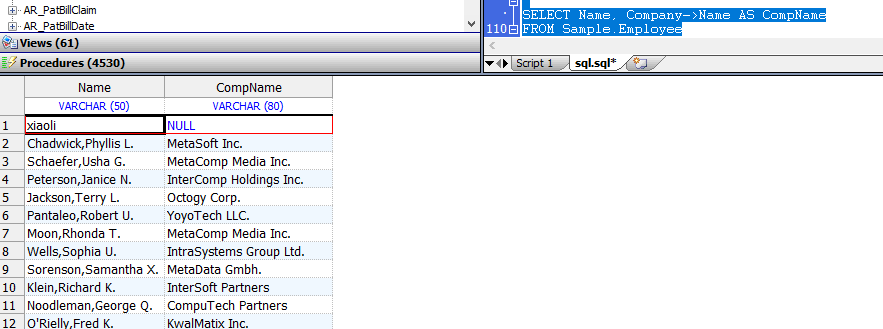
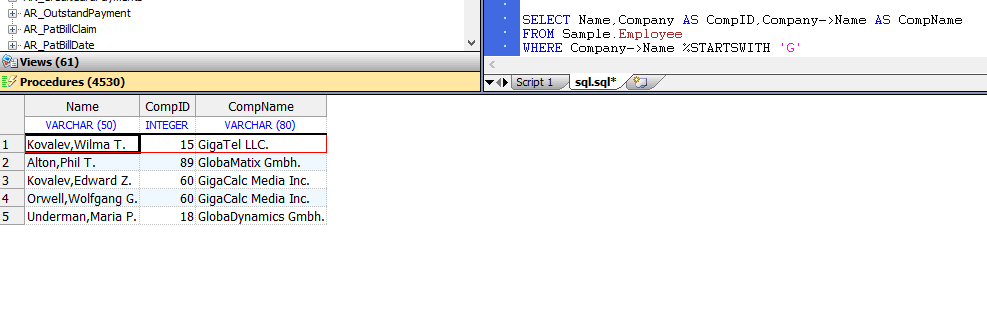
可以使用$SYSTEM.SQL.Execute() 方法从Terminal命令行执行一行SQL代码,而无需调用SQL Shell。以下示例显示如何在终端提示下使用此方法:
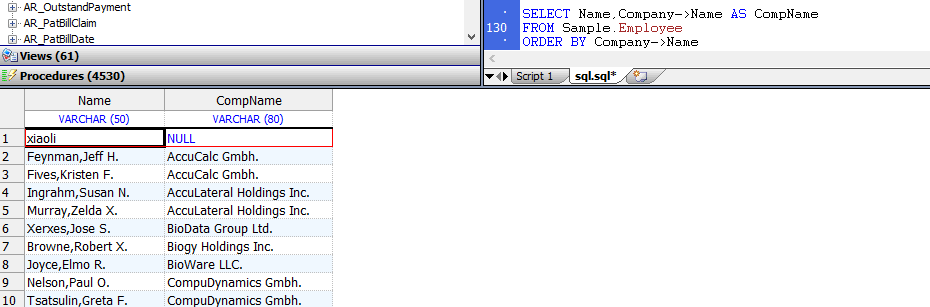
DHC-APP>SET result=$SYSTEM.SQL.Execute("SELECT TOP 5 name,dob,ssn FROM Sample.Person")
DHC-APP>DO result.%Display()
Name DOB SSN
yaoxin 54536 111-11-1117
xiaoli 111-11-1111
姚鑫 63189 111-11-1112
姚鑫 63189 111-11-1113
姚鑫 50066 111-11-1114
5 Rows(s) Affected
如果SQL语句包含错误,则Execute()方法成功完成;否则,该方法无效。 %Display()方法返回错误信息,例如:
USER>DO result.%Display()
[SQLCODE: <-29>:<Field not found in the applicable tables>]
[%msg: < Field 'GAME' not found in the applicable tables^ SELECT TOP ? game ,>]
0 Rows Affected
USER>
Execute()方法还提供了可选的SelectMode、Dialect和ObjectSelectMode参数。
InterSystems IRIS支持许多其他编写和执行SQL代码的方法
这些包括:
- 嵌入式SQL:嵌入ObjectScript代码中的SQL代码。
- 动态SQL:使用
%SQL。 从ObjectScript代码中执行SQL语句的语句类方法。 - 管理门户SQL接口:使用Execute Query接口从InterSystems IRIS管理门户执行动态SQL。
调用SQL Shell
可以使用$SYSTEM.SQL.Shell()方法在终端提示符中调用SQL Shell,如下所示:
DO $SYSTEM.SQL.Shell()
或者,可以使用%SQL作为一个实例调用SQL Shell。 Shell类,如下所示:
DO ##class(%SQL.Shell).%Go("IRIS")
或
SET sqlsh=##class(%SQL.Shell).%New()
DO sqlsh.%Go("IRIS")
无论如何调用,SQL Shell都会返回SQL Shell提示符,如下所示:
[SQL]termprompt>>
其中[SQL]是指在SQL Shell中,termprompt是配置的终端提示符,>>是指SQL命令行。
默认情况下,SQL Shell提示符如下所示:[SQL]nsp>>,其中“nsp”是当前命名空间的名称。
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
DHC-APP>> << entering multiline statement mode >>
1>>
1>>SELECT TOP 5 name,dob,ssn FROM Sample.Person
2>>
2>>q
DHC-APP>>q
在这个提示符下,可以使用以下任一Shell模式:
- 单行模式:在提示符下键入一行SQL代码。
结束SQL语句,按
“Enter”。 默认情况下,这将准备并执行SQL代码(这称为立即执行模式)。 对于查询,结果集显示在终端屏幕上。 对于其他SQL语句,将在终端屏幕上显示SQLCODE和行数值。 - 多行模式:在提示符下按Enter。这使进入多行模式。可以键入多行SQL代码,每个新行提示均指示行号。 (空行不会增加行号。)要结束多行SQL语句,请键入GO并按Enter。默认情况下,这既准备并执行SQL代码。对于查询,结果集显示在终端屏幕上。对于其他SQL语句,SQLCODE和行计数值显示在终端屏幕上。
多行模式提供以下命令,可以在多行提示符下键入以下命令,然后按Enter:L或LIST列出到目前为止输入的所有SQL代码。 C或CLEAR删除到目前为止输入的所有SQL代码。 C n或CLEAR n(其中n是行号整数)以删除特定的SQL代码行。 G或GO准备和执行SQL代码,然后返回单行模式。 Q或QUIT删除到目前为止输入的所有SQL代码并返回单行模式。这些命令不区分大小写。发出命令不会增加下一个多行提示的行号。打?在多行提示符处列出了这些多行命令。
为了准备一条SQL语句,SQL Shell首先验证该语句,包括确认指定的表存在于当前名称空间中,并且指定的字段存在于表中。如果不是,它将显示适当的SQLCODE。
如果该语句有效,并且具有适当的特权,则SQL Shell会回显SQL语句,并为其分配一个序号。无论您是否更改名称空间和/或退出并重新进入SQL Shell,这些数字在终端会话期间都将按顺序分配。这些分配的语句编号允许重新调用以前的SQL语句,如下所述。
也可以使用DO Shell^%apiSQL.在终端提示下调用SQL Shell。
要列出所有可用的SQL Shell命令,请输入?。在SQL提示下。
要终止SQL Shell会话并返回到Terminal提示符,请在SQL提示符下输入Q或QUIT命令或E命令。 SQL Shell命令不区分大小写。
以下是使用默认参数设置的示例SQL Shell会话:
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
DHC-APP>>SELECT TOP 5 Name,Home_State FROM Sample.Person ORDER BY Home_State
1. SELECT TOP 5 Name,Home_State FROM Sample.Person ORDER BY Home_State
Name Home_State
xiaoli
姚鑫
姚鑫
姚鑫
姚鑫
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0523s/45502/270281/2ms
execute time(s)/globals/lines/disk: 0.0004s/225/2915/0ms
---------------------------------------------------------------------------
DHC-APP>>q
以下是使用默认参数设置的多行SQL Shell会话:
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
DHC-APP>> << entering multiline statement mode >>
1>>SELECT TOP 5
2>>Name,Home_State
3>>FROM Sample.Person
4>>ORDER BY Home_State
5>>GO
2. SELECT TOP 5
Name,Home_State
FROM Sample.Person
ORDER BY Home_State
Name Home_State
xiaoli
姚鑫
姚鑫
姚鑫
姚鑫
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0002s/18/1168/0ms
execute time(s)/globals/lines/disk: 0.0003s/225/2886/0ms
---------------------------------------------------------------------------
GO命令
SQL Shell GO命令执行最新的SQL语句。在单行模式下,GO重新执行最近执行的SQL语句。在多行模式下,GO命令用于执行多行SQL语句并退出多行模式。单行模式下的后续GO将重新执行先前的多行SQL语句。
输入参数
SQL Shell支持使用“?”输入参数的使用SQL语句中的字符。每次执行SQL语句时,系统都会提示指定这些输入参数的值。必须以与“?”相同的顺序指定这些值字符出现在SQL语句中:第一个提示为第一个“?”提供一个值,第二个提示为第二个“?”提供一个值,依此类推。
输入参数的数量没有限制。可以使用输入参数将值提供给TOP子句,WHERE子句,并将表达式提供给SELECT列表。不能使用输入参数将列名提供给SELECT列表。
可以将主机变量指定为输入参数值。在输入参数提示下,指定一个以冒号(:)开头的值。该值可以是公共变量,ObjectScript特殊变量,数字文字或表达式。然后,SQL Shell会提示“这是文字(Y / N)吗?”。在此提示下指定N(否)(或仅按Enter)意味着将输入值解析为主机变量。例如,:myval将被解析为局部变量myval的值; :^ myval将被解析为全局变量^myval的值; :$HOROLOG将被解析为$HOROLOG特殊变量的值; :3将被解析为数字3; :10-3将被解析为数字7。在此提示符下指定Y(是)表示将输入值(包括冒号)作为文字提供给输入参数。
执行ObjectScript命令
在SQL Shell中,可能希望发出一个ObjectScript命令。例如,通过使用SET $NAMESPACE命令将InterSystems IRIS命名空间更改为包含要引用的SQL表或存储过程的命名空间。可以使用SQL Shell!命令或OBJ命令以发出由一个或多个ObjectScript命令组成的ObjectScript命令行。 (OBJ是OBJECTSCRIPT的缩写。)!,OBJ和OBJECTSCRIPT命令是同义词。以下示例显示了这些命令的用法:
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
[SQL]%SYS>>! SET oldns=$NAMESPACE SET $NAMESPACE="USER" WRITE "changed the namespace"
changed the namespace
[SQL]USER>>OBJ SET $NAMESPACE=oldns WRITE "reverted to old namespace"
reverted to old namespace
[SQL]%SYS>>
OBJ命令之后的其余命令行被视为ObjectScript代码。 !之间不需要空格。和ObjectScript命令行。可以在SQL Shell单行模式或SQL Shell多行模式下指定OBJ命令。以下示例在USER名称空间中定义的表上执行SELECT查询:
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
[SQL]%SYS>> << entering multiline statement mode >>
1>>OBJ SET $NAMESPACE="USER"
1>>SELECT TOP 5 Name,Home_State
2>>FROM Sample.Person
3>>GO
/* SQL query results */
[SQL]USER>>
请注意,OBJ语句不会增加SQL行数。
在SQL Shell多行模式下,在返回行时将执行OBJ命令,但是直到指定GO才发出SQL语句。因此,以下示例在功能上与先前的示例相同:
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
[SQL]%SYS>> << entering multiline statement mode >>
1>>SELECT TOP 5 Name,Home_State
2>>FROM Sample.Person
3>>OBJ SET $NAMESPACE="USER" WRITE "changed namespace"
changed namespace
3>>GO
/* SQL query results */
[SQL]USER>>
以下示例使用OBJ命令定义主机变量:
USER>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: <<nothing>>.
Enter q to quit, ? for help.
[SQL]USER>> << entering multiline statement mode >>
1>>SELECT TOP :n Name,Home_State
2>>FROM Sample.Person
3>>OBJ SET n=5
3>>GO
浏览命名空间
SQL Shell支持BROWSE命令,该命令显示在当前名称空间中定义或可从其访问的架构,表和视图。该显示包括多个级别的提示。要返回上一个提示级别,请在提示时按Return键。名称区分大小写。
- 在SQL Shell提示符下键入BROWSE,以列出当前名称空间中的架构。
- 在“架构:”提示下,按名称或编号选择一个架构。这将列出架构中的表和视图。
- 在“表/视图:”提示下,按名称或编号选择一个表(T)或视图(V)。这将显示表信息,然后显示选项列表。
- 在“选项:”提示下,按编号选择一个选项。可以使用此选项列出为表定义的字段或映射。
指定选项1(按名称表示的字段)或选项2(按数字表示的字段)以显示“Field:”提示。指定选项3(地图)以显示“Map:”提示。
- 在
“Field:”提示下,按数字或名称选择一个字段,或指定*以列出所有字段。这列出了详细的字段信息。
在“Map:”提示下,按数字或名称选择地图,或指定*列出所有Map。这列出了详细的Map信息。
CALL 命令
可以使用SQL Shell发出SQL CALL语句来调用SQL存储过程,如以下示例所示:
DHC-APP>>CALL Sample.PersonSets('G','NY')
3. CALL Sample.PersonSets('G','NY')
Dumping result #1
Name DOB Spouse
Gallant,Thelma Q. 45767 94
Gibbs,Mark S. 37331 13
Goldman,Will H. 59069 10
Gomez,Mo Q. 55626 55
Gore,Alfred M. 42991 13
Gore,Fred X. 32391 6
Grabscheid,Jocelyn B. 59676 79
7 Rows(s) Affected
Dumping result #2
Name Age Home_City Home_State
Chadbourne,Danielle G. 34 Pueblo NY
Eastman,Clint G. 4 Miami NY
Pape,Linda M. 71 Vail NY
Peterson,Janice N. 49 Islip NY
Schaefer,Jocelyn V. 93 Zanesville NY
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0043s/2153/15795/0ms
execute time(s)/globals/lines/disk: 0.0015s/315/7829/0ms
---------------------------------------------------------------------------
如果指定的存储过程在当前名称空间中不存在,则SQL Shell会发出SQLCODE -428错误。
如果指定的输入参数多于存储过程中定义的参数,则SQL Shell会发出SQLCODE -370错误。可以使用文字(“字符串”),主机变量(:var)和输入参数(?)的任意组合为存储过程指定参数值。
可以在CALL语句中使用主机变量,如以下示例所示:
[SQL]USER>>OBJ SET a="G",b="NY"
[SQL]USER>>CALL Sample.PersonSets(:a,:b)
- 可以在
CALL语句中使用输入参数(“?”字符),如以下示例所示:
[SQL]USER>>CALL Sample.PersonSets(?,?)
当执行CALL语句时,SQL Shell会提示为每个输入参数提供一个值。
执行SQL脚本文件
SQL Shell RUN命令执行一个SQL脚本文件。脚本文件的类型由DIALECT设置确定。 DIALECT的默认值为IRIS(InterSystems SQL)。











 在创建角色之后,即可为其分配资源。根据资源类型的不同,对资源的操作可以有读、写和使用三种权限。对于数据库引用的资源,是读权限和写权限。在本例中,我们需要创建的是只读用户,因此,资源权限分配读权限即可,不用赋写权限。
在创建角色之后,即可为其分配资源。根据资源类型的不同,对资源的操作可以有读、写和使用三种权限。对于数据库引用的资源,是读权限和写权限。在本例中,我们需要创建的是只读用户,因此,资源权限分配读权限即可,不用赋写权限。

 在经过上述配置之后,用户DemoUser即已拥有对命名空间DEMOSPACE中数据库的访问权限。
在经过上述配置之后,用户DemoUser即已拥有对命名空间DEMOSPACE中数据库的访问权限。
 此时,用户对数据库拥有读权限,但并没有对表执行查询或建表的权限,如果尝试create table,则会得到如下的权限错误信息:
此时,用户对数据库拥有读权限,但并没有对表执行查询或建表的权限,如果尝试create table,则会得到如下的权限错误信息:
 为继续实验,我们通过Portal执行这SQL语句先创建DemoSchema.Persons这张表
为继续实验,我们通过Portal执行这SQL语句先创建DemoSchema.Persons这张表

 在SQL表,SQL视图和SQL过程栏中,则是分别对表、视图和存储过程授予查询、执行等权限。在本例中,用户需要对DemoSchema这个Schema下的表拥有select查询权限,即可通过对SQL表授权进行
在SQL表,SQL视图和SQL过程栏中,则是分别对表、视图和存储过程授予查询、执行等权限。在本例中,用户需要对DemoSchema这个Schema下的表拥有select查询权限,即可通过对SQL表授权进行
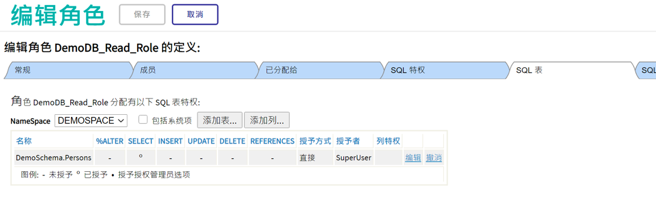
 授权后该角色的SQL表权限如下
授权后该角色的SQL表权限如下
 此时通过SQL工具已可执行查询
此时通过SQL工具已可执行查询
 使用Portal授权时是针对单个的表、视图或存储过程进行。在上例中,我们单独对表DemoSchema.Persons进行了授权,如果我们再建立一张DemoSchema.Employee表,当前的角色和用户并不能自动获得读取其数据的权限。
使用Portal授权时是针对单个的表、视图或存储过程进行。在上例中,我们单独对表DemoSchema.Persons进行了授权,如果我们再建立一张DemoSchema.Employee表,当前的角色和用户并不能自动获得读取其数据的权限。 即这个角色已经拥有了Schema级的授权,因此,对整个Schema下的所有表都拥有权限。之后在Schema中如果建立了新的表,则这个角色会自动拥有这些表的读权限。
即这个角色已经拥有了Schema级的授权,因此,对整个Schema下的所有表都拥有权限。之后在Schema中如果建立了新的表,则这个角色会自动拥有这些表的读权限。 IRIS的Web应用程序在创建时默认并不需要额外的资源去访问,这意味着所有合法用户都能登入这个Web应用,但由于支撑应用的后台程序和数据是受到资源的保护的,能登入的用户不一定具有运行程序、访问数据的权限,正如我们建立的用户DemoUser可以登录Portal,但没有功能菜单可用。
如果需要进一步限制用户的行为,禁止其登录,则还需要对应用权限进行控制。
如我们在上一篇文章:
IRIS的Web应用程序在创建时默认并不需要额外的资源去访问,这意味着所有合法用户都能登入这个Web应用,但由于支撑应用的后台程序和数据是受到资源的保护的,能登入的用户不一定具有运行程序、访问数据的权限,正如我们建立的用户DemoUser可以登录Portal,但没有功能菜单可用。
如果需要进一步限制用户的行为,禁止其登录,则还需要对应用权限进行控制。
如我们在上一篇文章: 其中必要的资源一栏即为该应用的资源需求,默认为空,即访问该应用不需要特定资源,只要是合法用户即可。我们可以为该应用指定所需资源,例如%Development,即只有具有%Development资源的角色及其对应的用户才能够访问该程序。保存设置后,再尝试以用户DemoUser登录Portal,结果是
其中必要的资源一栏即为该应用的资源需求,默认为空,即访问该应用不需要特定资源,只要是合法用户即可。我们可以为该应用指定所需资源,例如%Development,即只有具有%Development资源的角色及其对应的用户才能够访问该程序。保存设置后,再尝试以用户DemoUser登录Portal,结果是
 除非我们为DemoUser引用的角色DemoDB_Read_Role分配资源%Development,该用户都不能登录。
当然,超级管理员由于拥有所有权限,不受这个设置的影响。
除非我们为DemoUser引用的角色DemoDB_Read_Role分配资源%Development,该用户都不能登录。
当然,超级管理员由于拥有所有权限,不受这个设置的影响。
 并将其设置为按需启动
并将其设置为按需启动