在这一系列文章中,我想向大家介绍并探讨使用 InterSystems 技术和 GitLab 进行软件开发可以采用的几种方式。 我将介绍以下主题:
- Git 101
- Git 流程(开发流程)
- GitLab 安装
- GitLab 工作流
- 持续交付
- GitLab 安装和配置
- GitLab CI/CD
在第一篇文章中,我们介绍了 Git 基础知识、深度理解 Git 概念对现代软件开发至关重要的原因,以及如何使用 Git 开发软件。
在第二篇文章中,我们介绍了 GitLab 工作流 – 一个完整的软件生命周期流程,并介绍了持续交付。
在第三篇文章中,我们介绍了 GitLab 安装和配置以及将环境连接到 GitLab
在这篇文章中,我们将介绍编写 CD 配置。
计划
环境
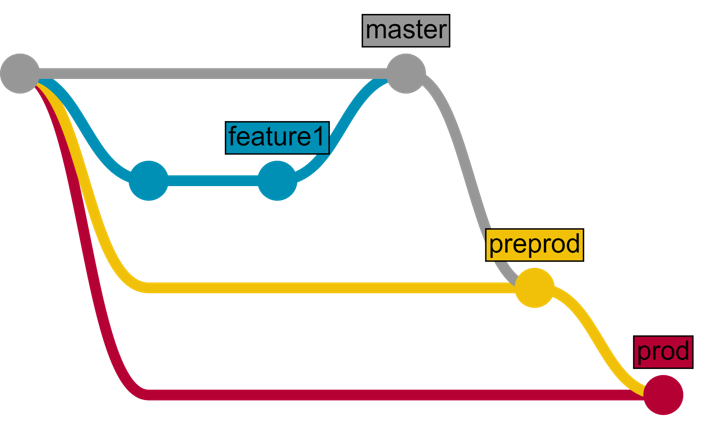
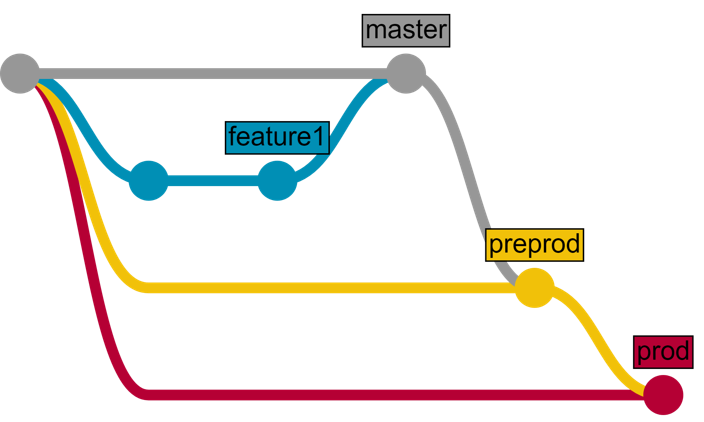
首先,我们需要多个环境以及与之对应的分支:
开发周期
作为示例,我们将使用 GitLab 流程开发一个新功能,并使用 GitLab CD 进行交付。
- 在功能分支中开发功能。
- 对功能分支进行审查并将其合并到 master 分支中。
- 一段时间(合并了多个功能)后,将 master 分支合并到 preprod 分支中
- 一段时间(用户测试等)后,将 preprod 分支合并到 prod 分支中
具体如下图所示(我用草图标出了我们需要为 CD 开发的部分):
- 开发和测试
- 开发者将新功能的代码提交到单独的功能分支中
- 功能稳定后,开发者将功能分支合并到 master 分支中
- 来自 master 分支的代码被交付到测试环境,在其中进行加载和测试
- 交付到预生产环境
- 开发者创建从 master 分支到 preprod 分支的合并请求
- 仓库所有者在一段时间后批准合并请求
- 来自 preprod 分支的代码被交付到预生产环境
- 交付到生产环境
- 开发者创建从 preprod 分支到 prod 分支的合并请求
- 仓库所有者在一段时间后批准合并请求
- 仓库所有者按下“部署”按钮
- 来自 prod 分支的代码被交付到生产环境
也可以用示意图形式表示此流程:
应用程序
应用程序由两部分组成:
- 在 InterSystems 平台上开发的 REST API
- 客户端 JavaScript web 应用程序
阶段
通过上面的计划,我们可以确定需要在持续交付配置中定义的阶段:
- 加载 – 将服务器端代码导入 InterSystems IRIS
- 测试 – 测试客户端和服务器代码
- 封装 – 构建客户端代码
- 部署 – 使用 Web 服务器“发布”客户端代码
以下是它在 gitlab-ci.yml 配置文件中的样式:
stages:
- load
- test
- package
- deploy
脚本
加载
下面我们来定义脚本。 脚本文档。 我们先来定义用于加载服务器端代码的脚本 load server:
load server:
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
stage: load
script: csession IRIS "##class(isc.git.GitLab).load()"脚本会执行哪些操作?
- load server 是脚本名称
- 接下来,我们来描述此脚本运行的环境
- only: master – 告知 GitLab 此脚本仅应在向 master 分支进行提交时运行
- tags: test 指定此脚本仅应在具有 test 标签的运行程序上运行
- stage 指定脚本的阶段
- script 定义要执行的代码 在本例中,我们从 isc.git.GitLab 类调用类方法 load
重要说明
对于 InterSystems IRIS,请将 csession 替换为 iris session。
对于 Windows,请使用:irisdb -s ../mgr -U TEST "##class(isc.git.GitLab).load()
现在,我们来编写相应的 isc.git.GitLab 类。 此类中的所有入口点如下所示:
ClassMethod method()
{
try {
// code
halt
} catch ex {
write !,$System.Status.GetErrorText(ex.AsStatus()),!
do $system.Process.Terminate(, 1)
}
}
请注意,可以通过两种方式结束此方法:
- 停止当前进程 – 在 GitLab 中注册为成功完成
- 调用 $system.Process.Terminate – 异常终止进程,GitLab 将此情况注册为错误
因此,加载代码如下:
/// Do a full load
/// do ##class(isc.git.GitLab).load()
ClassMethod load()
{
try {
set dir = ..getDir()
do ..log("Importing dir " _ dir)
do $system.OBJ.ImportDir(dir, ..getExtWildcard(), "c", .errors, 1)
throw:$get(errors,0)'=0 ##class(%Exception.General).%New("Load error")
halt
} catch ex {
write !,$System.Status.GetErrorText(ex.AsStatus()),!
do $system.Process.Terminate(, 1)
}
}
调用了两个实用方法:
- getExtWildcard – 获取相关文件扩展名列表
- getDir – 获取仓库目录
如何获取目录?
执行脚本时,GitLab 会先指定很多环境变量。 其中一个环境变量是 CI_PROJECT_DIR – 克隆仓库以及运行作业位置的完整路径。 我们可以通过 getDir 方法轻松获取:
ClassMethod getDir() [ CodeMode = expression ]
{
##class(%File).NormalizeDirectory($system.Util.GetEnviron("CI_PROJECT_DIR"))
}
测试
以下是测试脚本:
load test:
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
stage: test
script: csession IRIS "##class(isc.git.GitLab).test()"
artifacts:
paths:
- tests.html有哪些更改? 当然是名称和脚本代码,但还添加了工件。 工件是作业成功完成后附加到作业的文件和目录列表。 本例中,测试完成后,我们可以生成重定向到测试结果的 HTML 页面,并使其可以通过 GitLab 访问。
请注意,加载阶段有很多复制粘贴的内容 – 环境是相同的,脚本部分(例如环境)可以单独标记并附加到脚本。 我们来定义测试环境:
.env_test: &env_test
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test现在,我们的脚本如下:
load test:
<<: *env_test
script: csession IRIS "##class(isc.git.GitLab).test()"
artifacts:
paths:
- tests.html接下来,我们使用 UnitTest 框架执行测试。
/// do ##class(isc.git.GitLab).test()
ClassMethod test()
{
try {
set tests = ##class(isc.git.Settings).getSetting("tests")
if (tests'="") {
set dir = ..getDir()
set ^UnitTestRoot = dir
$$$TOE(sc, ##class(%UnitTest.Manager).RunTest(tests, "/nodelete"))
$$$TOE(sc, ..writeTestHTML())
throw:'..isLastTestOk() ##class(%Exception.General).%New("Tests error")
}
halt
} catch ex {
do ..logException(ex)
do $system.Process.Terminate(, 1)
}
}
本例中,测试设置是相对于存储单元测试的仓库根目录的路径。 如果此处为空,则跳过测试。 writeTestHTML 方法用于输出重定向到测试结果的 html:
ClassMethod writeTestHTML()
{
set text = ##class(%Dictionary.XDataDefinition).IDKEYOpen($classname(), "html").Data.Read()
set text = $replace(text, "!!!", ..getURL())
set file = ##class(%Stream.FileCharacter).%New()
set name = ..getDir() _ "tests.html"
do file.LinkToFile(name)
do file.Write(text)
quit file.%Save()
}
ClassMethod getURL()
{
set url = ##class(isc.git.Settings).getSetting("url")
set url = url _ $system.CSP.GetDefaultApp("%SYS")
set url = url_"/%25UnitTest.Portal.Indices.cls?Index="_ $g(^UnitTest.Result, 1) _ "&$NAMESPACE=" _ $zconvert($namespace,"O","URL")
quit url
}
ClassMethod isLastTestOk() As %Boolean
{
set in = ##class(%UnitTest.Result.TestInstance).%OpenId(^UnitTest.Result)
for i=1:1:in.TestSuites.Count() {
#dim suite As %UnitTest.Result.TestSuite
set suite = in.TestSuites.GetAt(i)
return:suite.Status=0 $$$NO
}
quit $$$YES
}
XData html
{
<html lang="en-US">
<head>
<meta charset="UTF-8"/>
<meta http-equiv="refresh" content="0; url=!!!"/>
<script type="text/javascript">
window.location.href = "!!!"
</script>
</head>
<body>
If you are not redirected automatically, follow this <a href='!!!'>link to tests</a>.
</body>
</html>
}
封装
我们的客户端是一个简单的 HTML 页面:
<html>
<head>
<script type="text/javascript">
function initializePage() {
var xhr = new XMLHttpRequest();
var url = "${CI_ENVIRONMENT_URL}:57772/MyApp/version";
xhr.open("GET", url, true);
xhr.send();
xhr.onloadend = function (data) {
document.getElementById("version").innerHTML = "Version: " + this.response;
};
var xhr = new XMLHttpRequest();
var url = "${CI_ENVIRONMENT_URL}:57772/MyApp/author";
xhr.open("GET", url, true);
xhr.send();
xhr.onloadend = function (data) {
document.getElementById("author").innerHTML = "Author: " + this.response;
};
}
</script>
</head>
<body onload="initializePage()">
<div id = "version"></div>
<div id = "author"></div>
</body>
</html>
要进行构建,需要将 ${CI_ENVIRONMENT_URL} 替换为其值。 当然,实际应用程序可能需要 npm,但此处仅为了举例说明。 脚本如下:
package client:
<<: *env_test
stage: package
script: envsubst < client/index.html > index.html
artifacts:
paths:
- index.html部署
最后,我们将 index.html 部署到 Web 服务器根目录,以部署客户端。
deploy client:
<<: *env_test
stage: deploy
script: cp -f index.html /var/www/html/index.html
就是这些!
多个环境
如果您需要在多个环境中执行相同(相似)的脚本,应该如何操作? 脚本部分也可以是标签,因此下面给出了在测试和预生产环境中加载代码的示例配置:
stages:
- load
- test
.env_test: &env_test
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
.env_preprod: &env_preprod
environment:
name: preprod
url: http://preprod.hostname.com
only:
- preprod
tags:
- preprod
.script_load: &script_load
stage: load
script: csession IRIS "##class(isc.git.GitLab).loadDiff()"
load test:
<<: *env_test
<<: *script_load
load preprod:
<<: *env_preprod
<<: *script_load
通过这种方式,我们便无需复制粘贴代码。
有关完整的 CD 配置,请参阅此处。 该配置遵循在测试、预生产和生产环境之间移动代码的原始计划。
结论
可以将持续交付配置为自动执行任何所需的开发工作流。
链接
后续内容
在下一篇文章中,我们将创建利用 InterSystems IRIS Docker 容器的 CD 配置。












.png)