概述
快捷式医疗服务互操作资源 (FHIR) 是一个由 HL7 International 开发的标准化框架,旨在以灵活、对开发者友好且现代的方式促进医疗数据的交换。 它利用现代网络技术来确保在医疗保健系统间实现无缝集成与通信。
关键 FHIR 技术
- 用于资源交互的 RESTful API
- 用于数据表示的 JSON 和 XML
- 用于安全授权和身份验证的 OAuth2
FHIR 围绕着称为资源的模块化组件构建,每个组件代表特定的医疗保健概念,包括:
- 患者 – 受众特征和标识符
- 观察数据 – 临床测量数据(例如,生命体征、实验室检测结果)
- 诊疗 – 患者与医疗服务提供者的互动
- 药物、过敏不耐受、健康状况等
资源单独定义,并且可以引用其他资源,以构成一个完善的数据模型。
InterSystems IRIS for Health:FHIR 支持
InterSystems IRIS for Health 是一个专为医疗保健行业设计的统一数据平台。 它包含对 HL7 FHIR 的原生支持。 它提供内置工具与服务,能够实现 FHIR 资源的存储、检索、转换和交换。IRIS 通过三大 FHIR 处理组件提升系统的互操作性:
1.FHIR 仓库服务器
IRIS 可以快速部署符合 FHIR 标准的服务器,并支持以下功能:
- 完整的 FHIR 范式
- 实现 FHIR RESTful API,包括搜索和查询参数
- 导入并利用 FHIR 软件包和结构定义
- 使用 FHIR 配置文件
- 对 FHIR 资源进行原生 CRUD 操作
- 以 JSON 或 XML 格式检索 FHIR 数据
- 支持多种 FHIR 版本
- FHIR SQL Builder 和批量 FHIR 处理功能
2. FHIR 装饰层
FHIR 装饰层是用于在现有架构(通常为非 FHIR 架构)之上提供符合 FHIR 标准的 API 接口的软件架构模式。 它还能简化医疗保健数据系统,包括电子健康记录系统 (EHR)、旧版数据库或 HL7 v2 消息存储库,无需将所有数据迁移到 FHIR 原生系统中。
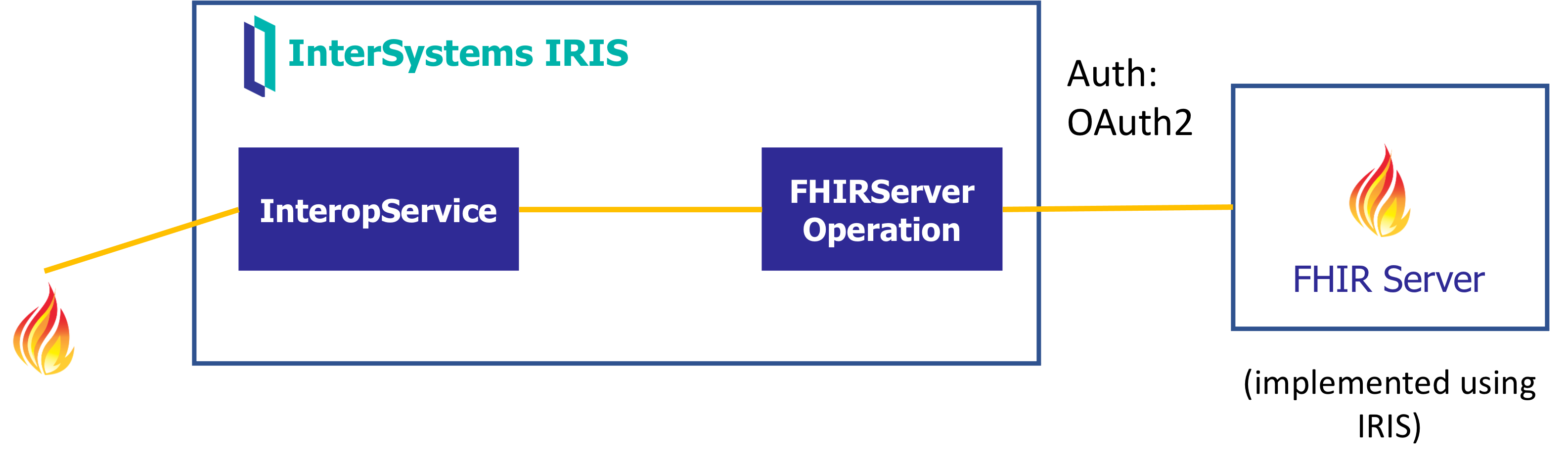
此实现专门围绕 FHIR Interoperability Adapter 展开。
3. FHIR Interoperability Adapter
InterSystems IRIS for Health 具备高度灵活性和精细控制能力,可以实现 HL7 V2.x、C-CDA 等医疗消息标准与 FHIR 之间的双向转换(参见“消息转换示意图”)。 不过,部分 FHIR 实现需要使用专用的 FHIR 仓库服务器。 为支持此类场景,InterSystems IRIS for Health 内置了一套互操作性适配器工具包,无需使用 FHIR 服务器即可实现详细的消息转换。
此适配器能够处理来自外部系统的各种外部请求(例如, REST 或 SOAP API 请求),将这些请求转换为 FHIR 格式,然后路由到下游系统,且无需将数据持久存储在数据库中。
如有需要,该适配器也可以对数据进行转换并将其存储在数据库中。
它能有效提供外部接口层,使非 FHIR 数据库可以像 FHIR 服务器一样运行,从而实现无缝互操作性。

消息转换
SDA:摘要文档架构
摘要文档架构 (SDA) 是 InterSystems 推出的基于 XML 的中间格式,用于在 IRIS 和 HealthShare 产品内部表示患者数据。 利用这种功能强大的原生数据结构,您可以访问离散数据,并轻松实现多种数据格式之间的转换,包括 HL7 V2、CCDA、C32、HL7 FHIR 等。

SDA 结构
SDA(结构化数据架构)主要分为两个组成部分:
- 容器 – 包含一个或多个部分的顶层结构
- 部分 – 特定医疗元素(例如,患者、诊疗、过敏不耐受)的表示
容器
容器是 SDA 标准的顶层结构,其中包含多个部分(例如,患者、诊疗、过敏不耐受等)。
我们来深入探讨一下 SDA 的内部结构及其组成部分。
容器的类定义:
HS.SDA3.Container 类作为表示 SDA 文档的主要定义。 各个部分(如患者、诊疗)均定义为对象,并作为属性包含在此 class.Sections 中。
“部分”是指容器元素的独立片段,它以 IRIS 类定义的形式表示,并包含容器上的相关数据元素。
- 患者 – HS.SDA3.Patient
- 诊疗 – HS.SDA3.Encounter
- 过敏症 - HS.SDA3.Allergy
SDA 容器结构
以下 XML 结构表示整个 SDA 容器。
<Container><Patient/><Encounters/><Encounters/><AdvanceDirectives/></Container>
SDA 数据类型
FHIR 数据类型格式与 IRIS 标准数据类型不同。 因此,SDA 具有特定的自定义数据类型,与 %String、%Integer、%Stream 等标准属性相比,这些数据类型可以更有效地处理部分中的属性。 不过,标准属性也用于 SDA 部分中。
相应数据类型类也在 HS.SDA3* 软件包中定义:
- HS.SDA3.Name
- HS.SDA3.CodeTableDetail.Allergy
- HS.SDA3.PatientNumber
- HS.SDA3.TimeStamp
SDA 扩展
大多数情况下,SDA 具有充足的属性来管理和生成系统中传输的所有数据,以开发资源。 不过,如果您需要在实现过程中加入额外的数据,IRIS 提供了一种简单直接的方式可以帮助您轻松地将相应数据扩展到 SDA 扩展类中。
例如,HS.Local.SDA3.AllergyExtension 类定义是 HS.SDA3.Allergy 的扩展类。 您可以向此扩展类添加必要的数据元素,从而简化整个实现过程中的访问和操作流程。
下一步是创建容器对象。
创建容器对象
ClassMethod CreateSDAContainer()
{
<span class="hljs-keyword">set</span> SDAContainer = <span class="hljs-keyword">##class</span>(HS.SDA3.Container).<span class="hljs-built_in">%New</span>()
#<span class="hljs-comment">; create patient object</span>
<span class="hljs-keyword">set</span> patientSDA = <span class="hljs-keyword">##class</span>(HS.SDA3.Patient).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> patientSDA.Name.FamilyName = <span class="hljs-string">"stood"</span>
<span class="hljs-keyword">set</span> patientSDA.Name.GivenName = <span class="hljs-string">"test"</span>
<span class="hljs-keyword">set</span> patientSDA.Gender.Code=<span class="hljs-string">"male"</span>
<span class="hljs-keyword">set</span> patientSDA.Gender.Description=<span class="hljs-string">"birth gender"</span>
#<span class="hljs-comment">; create Encounter 1</span>
<span class="hljs-keyword">set</span> encounterSDA = <span class="hljs-keyword">##class</span>(HS.SDA3.Encounter).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> encounterSDA.AccountNumber = <span class="hljs-number">12109979</span>
<span class="hljs-keyword">set</span> encounterSDA.ActionCode =<span class="hljs-string">"E"</span>
<span class="hljs-keyword">set</span> encounterSDA.AdmitReason.Code =<span class="hljs-string">"Health Concern"</span>
<span class="hljs-keyword">set</span> encounterSDA.AdmitReason.Description = <span class="hljs-string">"general health concern"</span>
#<span class="hljs-comment">; create Encounter 2</span>
<span class="hljs-keyword">set</span> encounterSDA1 = <span class="hljs-keyword">##class</span>(HS.SDA3.Encounter).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> encounterSDA1.AccountNumber = <span class="hljs-number">95856584</span>
<span class="hljs-keyword">set</span> encounterSDA1.ActionCode =<span class="hljs-string">"D"</span>
<span class="hljs-keyword">set</span> encounterSDA1.AdmitReason.Code =<span class="hljs-string">"reegular checkup"</span>
<span class="hljs-keyword">set</span> encounterSDA1.AdmitReason.Description = <span class="hljs-string">"general health ckeckup"</span>
#<span class="hljs-comment">; set the patientSDA into the container.</span>
<span class="hljs-keyword">set</span> SDAContainer.Patient = patientSDA
#<span class="hljs-comment">; set multiple encounters into the container SDA</span>
<span class="hljs-keyword">do</span> SDAContainer.Encounters.Insert(encounterSDA)
<span class="hljs-keyword">do</span> SDAContainer.Encounters.Insert(encounterSDA1)
#<span class="hljs-comment">; convert the SDA object into an XML string.</span>
<span class="hljs-keyword">do</span> SDAContainer.XMLExportToString(.containerString)
<span class="hljs-keyword">write</span> containerString
}
SDA – XML 文档输出
<Container><Patient><Name><FamilyName>stood</FamilyName><GivenName>test</GivenName></Name><Gender><Code>male</Code><Description>birth gender</Description></Gender></Patient><Encounters><Encounter><AccountNumber>12109979</AccountNumber><AdmitReason><Code>Health Concern</Code><Description>general health concern</Description></AdmitReason><ActionCode>E</ActionCode></Encounter><Encounter><AccountNumber>95856584</AccountNumber><AdmitReason><Code>reegular checkup</Code><Description>general health ckeckup</Description></AdmitReason><ActionCode>D</ActionCode></Encounter></Encounters><UpdateECRDemographics>true</UpdateECRDemographics></Container>
在上一节中,我们探讨了 SDA 及其组成部分。 我们还学习了如何通过 Cache ObjectScript 生成 SDA。
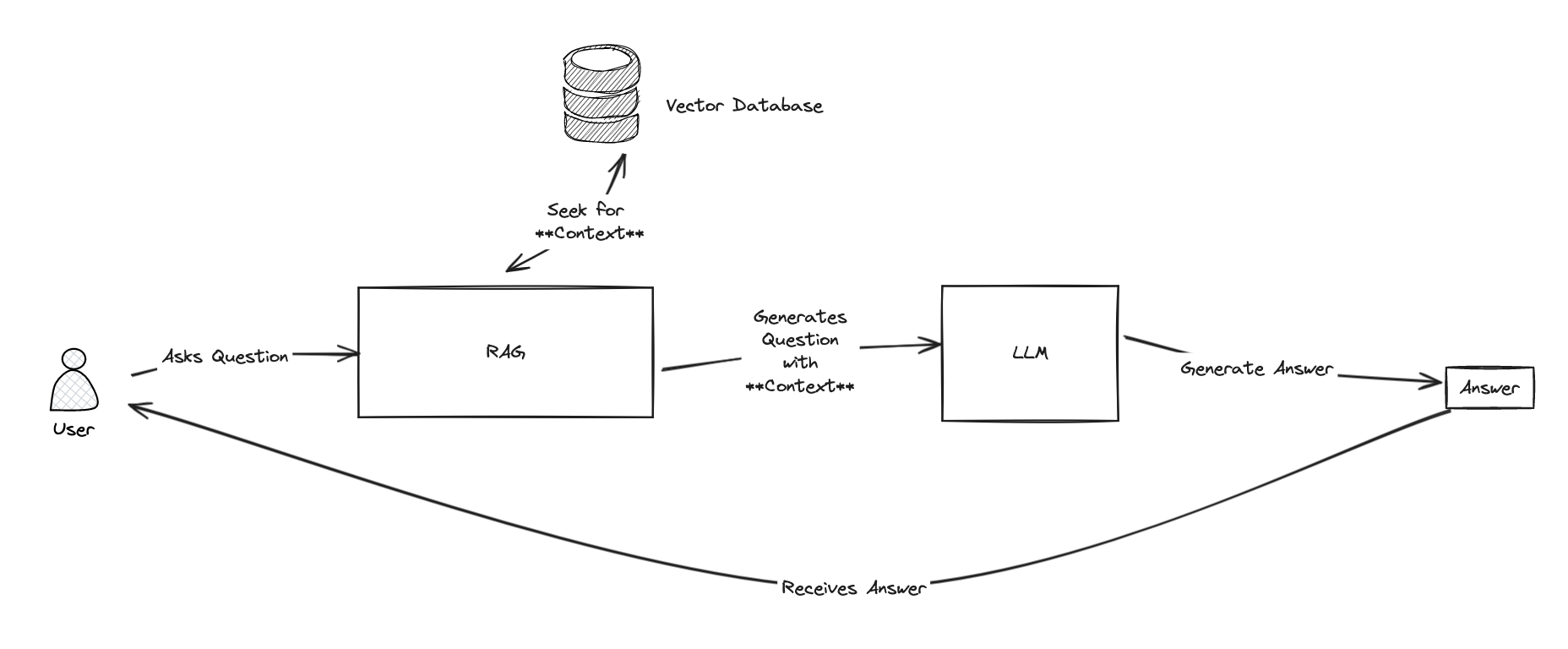
接下来,我们将使用互操作性生产(之前称为 Ensemble)生成 FHIR 资源或捆绑包。
在创建 FHIR 资源之前,我们来简单了解一下互操作性生产。
带 FHIR 适配器的互操作性生产
互操作性生产是一个集成框架,用于连接系统和开发应用程序,以轻松实现互操作性。 它通常分为 3 大组成部分:
- 业务服务 – 连接到外部系统,并接收外部系统发出的请求。
- 业务流程 – 接收其他业务主机发出的请求、根据您定义的业务逻辑处理请求,并转换相关数据。 会使用多个组件进行数据转换:
- BPL – 业务流程语言
- DTL – 数据转换语言
- BR – 业务规则
- 记录映射
- 业务操作 – 与外部系统相连,并向外部系统发送响应。

首先,我们来构建 FHIR 消息。
创建 FHIR 资源
存在两种类型的系统:FHIR 服务器和非 FHIR 服务器。 在我们的案例中,我们的目标是使用 FHIR Interoperability Adapter 生成 FHIR 资源,将非 FHIR 的InterSystems IRIS 数据库表示为符合 FHIR 标准的系统。
在本节中,我们将演示如何借助带 FHIR 适配器的 InterSystems IRIS for Health 互操作性工具包,通过存储在 IRIS 数据库中的自定义数据生成 FHIR 资源。
在此实现过程中,我们将创建以下类型的 FHIR 资源:
- 标准 FHIR 资源 – 使用内置的 FHIR 类,进行少量修改或不做修改。
- 自定义 FHIR 资源 – 涉及向 SDA 模型添加扩展,以及为 FHIR 资源创建自定义数据转换 (DTL)。
每个实现都将通过专用的业务主机启动。
业务服务
RESTful 业务主机负责接收外部系统发出的请求。 您可以根据特定集成要求(例如,HTTP、SOAP 或其他受支持的协议)配置合适的适配器。
接收到外部系统发送的请求后,工作流将立即使用自定义或旧版数据库中持久存储的数据生成相应的 FHIR 资源。
FHIR 业务流程
FHIR 消息生成流程主要包括两个步骤:
- 将自定义/专有数据转换为 SDA(将 HL7 版本 2.X 转换为 SDA,将 CCDA 转换为 SDA,等等)。
- 将数据元素添加到 SDA,如有需要,创建自定义 DTL。 以下步骤为可选步骤,是否执行取决于具体实现需求,例如自定义 FHIR 资源生成。
- 然后,借助 IRIS 内置流程将生成的 SDA 转换为 FHIR 资源。
结构化数据架构 (SDA) 格式充当中介,可以实现灵活的数据转换。 数据以 SDA 格式提供后,即可轻松映射到 FHIR 或其他医疗保健数据标准。
将自定义/专有数据转换为 SDA 格式
使用这种方式时,先创建持久或互操作性请求类,以便转换为 SDA 格式。 此过程涉及定义自定义患者类,用于将您的旧版或自定义数据库结构中的数据映射为符合 SDA 标准的对象。
利用自定义患者类可以提供极高的灵活性:
- 简化对象处理和操作流程。
- 以数据转换语言 (DTL) 实现清晰映射。
- 轻松重用其他转换或业务逻辑层中的对象。
请求外部层的类以转换 SDA:
Class Samples.FHIRAdapt.CustomStorage.Patient Extends (Ens.Request,%JSON.Adaptor)
{
Property Name As%StringProperty BirthDate As%StringProperty Citizenship As%StringProperty Religion As%StringProperty PrimaryLanguage As%StringProperty Married As%StringProperty MRN As%String
}
此请求类作为外部接口层,启动从您的数据库格式转换为 SDA 的流程。 SDA 对象创建完毕后,可以通过标准或自定义 DTL 映射无缝转换为所需 FHIR 资源:
- 添加 Samples.FHIRAdapt.CustomStorage.Patient(使用您的类定义)类作为转换的源类。
- 确定并选择适合映射的 SDA 目标类。 在本例中,HS.SDA3.Patient 是适合将自定义数据转换为 SDA 格式的类。
DTL 转换示例
Class Samples.FHIRAdapt.DTL.CustomDataToPatientSDA Extends Ens.DataTransformDTL [ DependsOn = (Samples.FHIRAdapt.CustomStorage.Patient, HS.SDA3.Patient) ]
{
Parameter IGNOREMISSINGSOURCE = 1Parameter REPORTERRORS = 1Parameter TREATEMPTYREPEATINGFIELDASNULL = 0
XData DTL [ XMLNamespace = "http://www.intersystems.com/dtl" ]
{
<transform sourceClass='Samples.FHIRAdapt.CustomStorage.Patient' targetClass='HS.SDA3.Patient' create='new' language='objectscript' >
<assign value='$Piece(source.Name,",")' property='target.Name.GivenName' action='set' />
<assign value='$Piece(source.Name,",")' property='target.Name.FamilyName' action='set' />
<assign value='$Piece($Piece(source.Name,",",2)," ",2)' property='target.Name.MiddleName' action='set' />
<assign value='source.Citizenship' property='target.Citizenship' action='set' />
<assign value='"fullname"' property='target.Name.Type' action='set' />
<assign value='$Select(source.Married=1:"married",1:"single")' property='target.MaritalStatus.Code' action='set' />
</transform>
}
}
在这一阶段,数据已成功转换为 SDA 文档,并准备好转换为 FHIR 资源。
在生成 FHIR 资源之前,应创建额外的支持 FHIR 资源作为此响应的组成部分。 此外,还需要在 FHIR 输出中包含自定义字段。 要支持这些自定义元素,必须将相应的属性纳入 SDA 结构。
此操作可以借助 SDA 扩展完成,SDA 扩展可以将准确、完整地生成 FHIR 资源所需的自定义数据元素包含在 SDA 结构中。
SDA 扩展
FHIR 遵循 80/20 法则,即核心 FHIR 规范负责处理约 80% 的常见医疗保健用例,而剩余的 20% 则通过自定义约束和扩展来解决。
为说明这一点,我们将使用自定义扩展创建一个 AllergyIntolerance 资源。
在 InterSystems IRIS 中正确实现扩展数据元素需要执行两个关键步骤:
- 类 HS.SDA3.*******Extension 用于将额外的数据元素添加到各个 SDA 部分。 例如,类 HS.Local.SDA3.AllergyExtension 通过定义所需自定义属性对 HS.SDA3.Allergy 进行扩展。
- 由于预构建的 DTL 映射不包含这些自定义扩展,必须创建自定义 DTL 来相应地转换处理。
Allergy 扩展类
要在用于创建所需过敏症资源的 HS.Local.SDA3.AllergyExtension 类中构建所需字段,请使用以下代码行:
Class HS.Local.SDA3.AllergyExtension Extends HS.SDA3.DataType
{
Parameter STREAMLETCLASS = "HS.SDA3.Streamlet.Allergy"Property Criticality As%StringProperty Type As%String(MAXLEN = "")
Storage Default
{
<Data name="AllergyExtensionState">
<Subscript>"AllergyExtension"</Subscript>
<Value name="1">
<Value>Criticality</Value>
</Value>
<Value name="2">
<Value>Type</Value>
</Value>
</Data>
<State>AllergyExtensionState</State>
<Type>%Storage.Serial</Type>
}
}
创建扩展只是完成了整个流程的一半,因为标准 DTL 未提供扩展字段的映射。 现在,我们需要构建自定义 DTL,以正确转换 FHIR 响应。
自定义 DTL 创建
在自定义 DTL 类之前,您需要为所有自定义 DTL 实现定义专用软件包。 为此,InterSystems 建议使用名为 HS.Local.FHIR.DTL 的软件包。
要为 Allergy 构建自定义 DTL,请先从现有的数据转换类
HS.FHIR.DTL.SDA3.vR4.Allergy.AllergyIntolerance 开始,该类用于处理从 SDA 到 FHIR 资源的转换。
首先,将此类复制到自定义包中,将其命名为
HS.Local.FHIR.DTL.SDA3.vR4.Allergy.AllergyIntolerance. 然后,将自定义扩展映射到 FHIR 资源生成流程中,以对其进行扩展。
例如,示例类 HS.Local.FHIR.DTL.FromSDA.Allergy 说明了如何便捷地映射 Allergy 扩展字段,同时从基类 HS.FHIR.DTL.SDA3.vR4.Allergy.AllergyIntolerance 继承所有其他映射。
示例自定义 DTL 映射如下图所示:
Class HS.Local.FHIR.DTL.SDA3.vR4.Allergy.AllergyIntolerance Extends Ens.DataTransformDTL [ DependsOn = (HS.SDA3.Allergy, HS.FHIR.DTL.vR4.Model.Resource.AllergyIntolerance), ProcedureBlock ]
{
XData DTL [ XMLNamespace = "http://www.intersystems.com/dtl" ]
{
<transform sourceClass='HS.SDA3.Allergy' targetClass='HS.FHIR.DTL.vR4.Model.Resource.AllergyIntolerance' create='existing' language='objectscript' >
<assign value='source.Extension.Criticality' property='target.criticality' action='set' />
<assign value='source.Extension.Type' property='target.type' action='set' >
<annotation>11/07/2023
</assign>
</transform>
}
}
为自定义 DTL 创建类软件包后(在自定义 DTL 软件包不存在的情况下),必须进行注册,以获得今后的 FHIR 数据转换结果。
set status = ##class(HS.FHIR.DTL.Util.API.ExecDefinition).SetCustomDTLPackage("HS.Local.FHIR.DTL")
此外,您还可以通过调用类方法获取自定义 DTL 软件包详细信息(如果已定义)。
Write ##class(HS.FHIR.DTL.Util.API.ExecDefinition).GetCustomDTLPackage()
请求消息的流容器类
SDA 及其可选 SDA 扩展的设置,以及构建 SDA 的可选自定义 DTL 创建过程现已完成。 不过,现在必须将 SDA 对象转换为标准化的 Ens.StreamContainer,该容器专门用于 SDA 到 FHIR 的转换业务流程。
下面的简单步骤可以将 SDA 对象转换为 Ens.StreamContainer。
ClassMethod CreateEnsStreamContainer()
{
set ensStreamCntr=""try {
##dim SDAContainer As HS.SDA3.Container = ..CreateSDAContainer()
do SDAContainer.XMLExportToStream(.stream)
#Set ensStreamCntr = ##class(Ens.StreamContainer).%New(stream)
}
catch ex {
Write ex.DisplayString()
set ensStreamCntr=""
}
return ensStreamCntr
}
创建 SDA 的第一阶段已完成。 第二阶段(即生成 FHIR 资源)已由 InterSystems IRIS 处理。
下文介绍如何将 SDA 文档转换为 FHIR 资源。
SDA 转换为 FHIR
针对 FHIR 创建配置互操作性业务主机
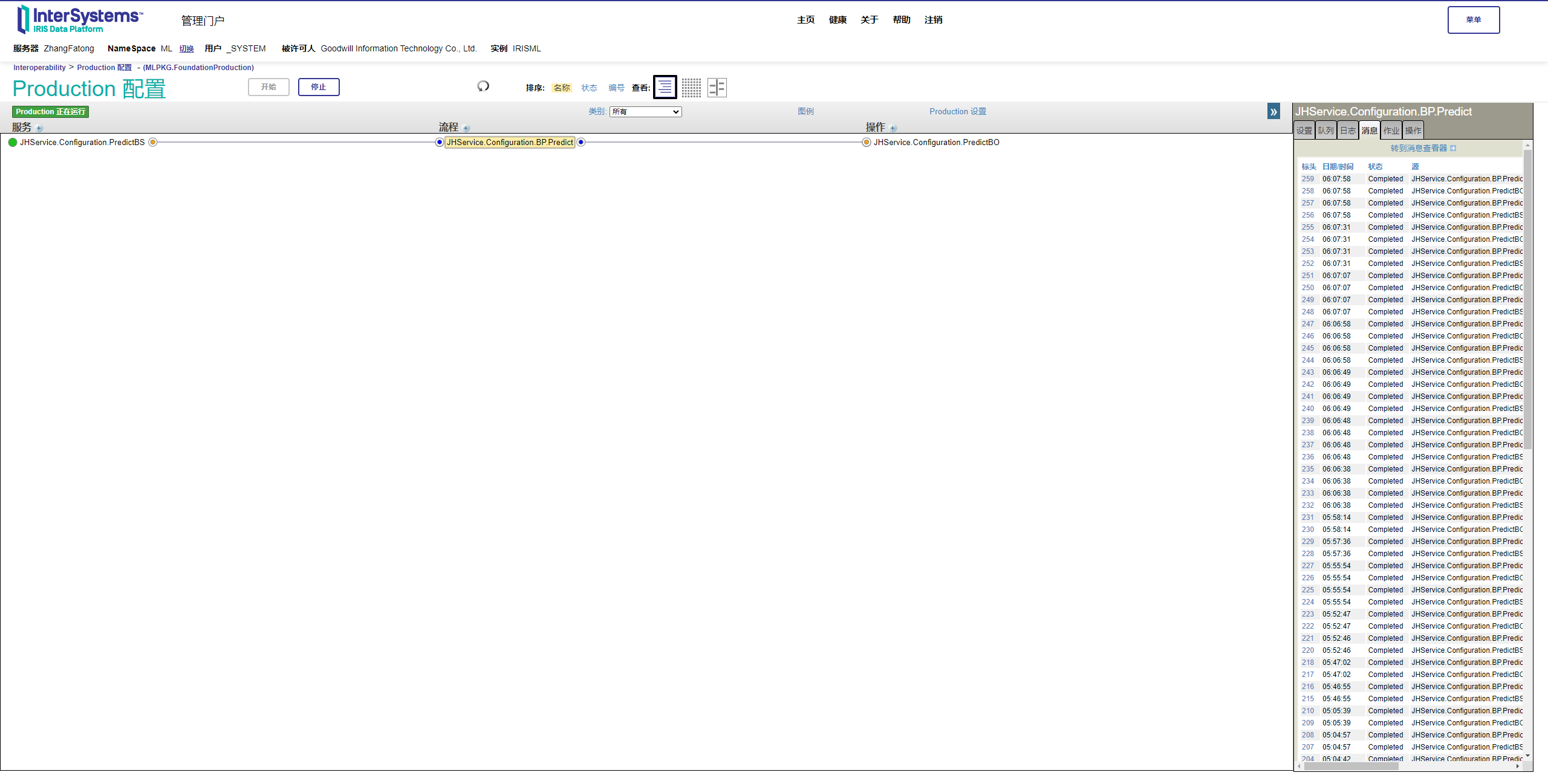
生成 FHIR 的业务逻辑已完成。 现在,我们来配置互操作性生产设置:
- 设置入站服务,以接收外部系统发出的请求。
- 业务流程 – 这是创建 FHIR 资源的关键步骤。
业务流程实现
此业务流程侧重于 SDA 到 FHIR 的转换。 InterSystems IRIS 包含一套全面的内置业务流程,即 S.FHIR.DTL.Util.HC.SDA3.FHIR.Process,该流程可以促进 SDA 与 FHIR 消息的转换。 通过将生成的 SDA 文档发送到此业务流程,您可以接收以 JSON 响应形式发送的 FHIR 资源。
此流程支持两种类型的 FHIR 响应,具体取决于 SDA 输入。
- 捆绑包 – 如果整个 SDA 容器对象以 Ens.StreamConainter 形式发送,该流程会返回包含所有资源的 FHIR 捆绑包。
- 资源 – 如果个别 SDA 部分(例如,患者、诊疗、过敏症)以 Ens.StreamConainter 的形式发送,它会以捆绑包的形式发送对应的单个 FHIR 资源。
业务操作
FHIR 捆绑包现已准备就绪,可被返回给请求方或发送到外部系统。
生产设置:
.png)
业务服务类
该业务服务类负责处理外部系统发出的请求,以生成 FHIR。
- 一旦接收到请求,它就会使用现有逻辑创建 SDA。
- 该 SDA 随后会被转换为流对象。
- 此流会被转换为标准业务流程预期使用的格式。
- 最后,处理好的输入会被发送到业务流程。
Class Samples.Interop.BS.GenerateFHIRService Extends Ens.BusinessService
{
Parameter ADAPTER = "Ens.InboundAdapter"Property TargetConfigName As Ens.DataType.ConfigName [ InitialExpression = "HS.FHIR.DTL.Util.HC.FHIR.SDA3.Process" ]
Method OnProcessInput(pInput As%RegisteredObject, Output pOutput As%RegisteredObject) As%Status
{
#do..CreateSDAContainer().XMLExportToStream(.sdaStream)
#<span class="hljs-comment">; convert to the standard Ens.StreamContainer message format</span>
<span class="hljs-keyword">set</span> ensStreamCtnr = <span class="hljs-keyword">##class</span>(Ens.StreamContainer).<span class="hljs-built_in">%New</span>(sdaStream)
#<span class="hljs-comment">; send to the Business process</span>
<span class="hljs-keyword">do</span> <span class="hljs-built_in">..SendRequestSync</span>(<span class="hljs-built_in">..TargetConfigName</span>,ensStreamCtnr,.pOutput)
<span class="hljs-keyword">Quit</span> <span class="hljs-built_in">$$$OK</span>
}
ClassMethod CreateSDAContainer() As HS.SDA3.Container
{
<span class="hljs-keyword">set</span> SDAContainer = <span class="hljs-keyword">##class</span>(HS.SDA3.Container).<span class="hljs-built_in">%New</span>()
#<span class="hljs-comment">; create patient object</span>
<span class="hljs-keyword">set</span> patientSDA = <span class="hljs-keyword">##class</span>(HS.SDA3.Patient).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> patientSDA.Name.FamilyName = <span class="hljs-string">"stood"</span>
<span class="hljs-keyword">set</span> patientSDA.Name.GivenName = <span class="hljs-string">"test"</span>
<span class="hljs-keyword">set</span> patientSDA.Gender.Code=<span class="hljs-string">"male"</span>
<span class="hljs-keyword">set</span> patientSDA.Gender.Description=<span class="hljs-string">"birth gender"</span>
#<span class="hljs-comment">; create Encounter 1</span>
<span class="hljs-keyword">set</span> encounterSDA = <span class="hljs-keyword">##class</span>(HS.SDA3.Encounter).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> encounterSDA.AccountNumber = <span class="hljs-number">12109979</span>
<span class="hljs-keyword">set</span> encounterSDA.ActionCode =<span class="hljs-string">"E"</span>
<span class="hljs-keyword">set</span> encounterSDA.AdmitReason.Code =<span class="hljs-string">"Health Concern"</span>
<span class="hljs-keyword">set</span> encounterSDA.AdmitReason.Description = <span class="hljs-string">"general health concern"</span>
#<span class="hljs-comment">; set the patientSDA into the container.</span>
<span class="hljs-keyword">set</span> SDAContainer.Patient = patientSDA
#<span class="hljs-comment">; set encounters into the container SDA</span>
<span class="hljs-keyword">do</span> SDAContainer.Encounters.Insert(encounterSDA)
<span class="hljs-keyword">return</span> SDAContainer
}
}
使用 ObjectScript 创建 SDA 到 FHIR 的转换
在上一个示例中,FHIR 资源是借助互操作性框架通过 SDA 生成的。 在本节中,我们将直接使用 ObjectScript 构建 FHIR 捆绑包。
通过 SDA 容器创建 FHIR 捆绑包
CreateSDAContainer 方法会返回 HS.SDA3.Container 类型的对象(我们在上文中提到过)。 在将此 SDA 容器传递给 TransformStream 方法之前,必须先将其转换为流。 TransformStream 方法随后会处理该流,并在 tTransformObj.bundle 中以 %DynamicObject 形式返回 FHIR 捆绑包。
ClassMethod CreateBundle(fhirVersion As%String = "R4") As%DynamicObject
{
try {
Set SDAContainer = ..CreateSDAContainer()
Do SDAContainer.XMLExportToStream(.stream)
#Set tTransformObj = ##class(HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR).TransformStream( stream, "HS.SDA3.Container", fhirVersion)
return tTransformObj.bundle
}
catch ex {
write ex.DisplayString()
}
return""
}
使用 SDA 部分创建 FHIR 捆绑包
使用此方式时,会直接在 ObjectScript 中声明 patientSDA。 此 SDA 对象随后会被传递到 TransformObject 方法,这个方法负责处理此 SDA 对象,并以 %DynamicObject 形式返回 FHIR 捆绑包。
ClassMethod CreatePatientResourceDirectSet()
{
try {
#set patientSDA = ##class(HS.SDA3.Patient).%New()
set patientSDA.Name.FamilyName = "stood"set patientSDA.Name.GivenName = "test"set patientSDA.Gender.Code="male"set patientSDA.Gender.Description="birth gender"#dim tTransformObj As HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR = ##class(HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR).TransformObject(patientSDA,"R4")
set patinetBundle = tTransformObj.bundle
}
catch ex {
write ex.DisplayString()
}
return patinetBundle
}
使用自定义 FHIR DTL 和 Allergy 扩展创建过敏症资源
- 直接在 SDA 对象中填充所有必需字段,包括自定义扩展字段。
- 您应当在 TransformObject 方法中将 FHIR 版本类型作为第二个参数提及(“R4”代表 Resource4 FHIR 消息)。
- 将完成的 SDA 对象传递给 FHIR 转换类,以生成 AllergyIntolerance FHIR 捆绑包。
注:过敏症资源的自定义扩展已定义,自定义 DTL 映射已注册。
ClassMethod CreateAllergyWithDTL()
{
#
#set allerySDA = ##class(HS.SDA3.Allergy).%New()
set allerySDA.Extension.Criticality = "critial"set allerySDA.Extension.Type = "t1"set allerySDA.Comments = "testing allergies"set allerySDA.AllergyCategory.Code="food"set allerySDA.AllergyCategory.Description="sea food"
#
##dim tTransformObj As HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR = ##class(HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR).TransformObject(allerySDA,"R4")
Set patinetBundle = tTransformObj.bundle
}
FHIR 转换为 SDA
自定义数据、HL7 v2.x 或 CCDA 消息之前已被转换为 FHIR。 接下来的实现涉及将 FHIR 捆绑包或资源转换为 SDA 格式,随后可以存储在数据库中或转换为 CCDA 或 HL7 v2.x 格式。
JSON 或 XML 格式的 FHIR 资源接收自外部系统。 收到后,必须将资源转换为内部数据结构并存储在 IRIS 数据库中。
业务服务
可以根据要求通过 HTTP/REST 或其他任何入站适配器接收请求。
业务流程 – FHIR 转换为 SDA
InterSystems IRIS 接收到 FHIR 请求消息后,会提供全面的内置业务流程 (HS.FHIR.DTL.Util.HC.FHIR.SDA3.Process)。 此业务流程会将 FHIR 资源或捆绑包作为输入。 FHIR 输入只能是配置的 FHIR 版本。 此业务流程会将 FHIR 数据转换为 SDA3、将 SDA3 流转发给指定的业务主机、接收业务主机发送的响应,并返回 FHIR 响应。
请注意,您无法将收到的请求直接发送至业务流程。
请求输入应为以下类型:
- HS.FHIRServer.Interop.Request – 用于互操作性生产。
- HS.Message.FHIR.Request – FHIR 仓库服务器。
这意味着在发送请求之前,必须将请求转换为上述格式之一。
Creating Interop.Request
ClassMethod CreateReqObjForFHIRToSDA(pFHIRResource As%DynamicObject) As HS.FHIRServer.Interop.Request
{
#set pFHIRResource = {"resourceType":"Patient","name":[{"use":"official","family":"ashok te","given":["Sidharth"]}],"gender":"male","birthDate":"1997-09-08","telecom":[{"system":"phone","value":"1234566890","use":"mobile"},{"system":"email","value":"tornado1212@gmail.com"}],"address":[{"line":["Some street"],"city":"Manipal1","state":"Karnataka1","postalCode":"1234561"}]}
<span class="hljs-keyword">set</span> stream = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%Stream.GlobalCharacter</span>).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">do</span> stream.<span class="hljs-keyword">Write</span>(pFHIRResource.<span class="hljs-built_in">%ToJSON</span>())
#<span class="hljs-comment">; create Quick stream </span>
<span class="hljs-keyword">set</span> inputQuickStream = <span class="hljs-keyword">##class</span>(HS.SDA3.QuickStream).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> inputQuickStreamId = inputQuickStream.<span class="hljs-built_in">%Id</span>()
<span class="hljs-built_in">$$$ThrowOnError</span>( inputQuickStream.CopyFrom(stream) )
<span class="hljs-keyword">#dim</span> ensRequest <span class="hljs-keyword">as</span> HS.FHIRServer.Interop.Request = <span class="hljs-keyword">##class</span>(HS.FHIRServer.Interop.Request).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> ensRequest.QuickStreamId = inputQuickStreamId
<span class="hljs-keyword">return</span> ensRequest
在 HS.FHIRServer.Interop.Request 消息创建完毕后,立即将其发送至业务流程,以将 FHIR 资源转换为 SDA 捆绑包。
生产设置:
.png)
业务服务类
该类通过 HTTP 请求接收 FHIR 资源流,将此流输入转换为标准流程预期使用的格式,即 HS.FHIRServer.Interop.Request,最后调用 FHIR 适配器流程类以生成 SDA。
Class Samples.Interop.BS.FHIRReceiver Extends Ens.BusinessService
{
Parameter ADAPTER = "EnsLib.HTTP.InboundAdapter"Property TargetConfigName As Ens.DataType.ConfigName [ InitialExpression = "HS.FHIR.DTL.Util.HC.FHIR.SDA3.Process" ]
Method OnProcessInput(pInput As%Stream.Object, Output pOutput As%Stream.Object) As%Status
{
set inputQuickStream = ##class(HS.SDA3.QuickStream).%New()
set inputQuickStreamId = inputQuickStream.%Id()
$$$ThrowOnError( inputQuickStream.CopyFrom(pInput) )
<span class="hljs-keyword">#dim</span> ensRequest <span class="hljs-keyword">as</span> HS.FHIRServer.Interop.Request = <span class="hljs-keyword">##class</span>(HS.FHIRServer.Interop.Request).<span class="hljs-built_in">%New</span>()
<span class="hljs-keyword">set</span> ensRequest.QuickStreamId = inputQuickStreamId
<span class="hljs-keyword">Do</span> <span class="hljs-built_in">..SendRequestSync</span>(<span class="hljs-built_in">..TargetConfigName</span>, ensRequest, .pOutput)
<span class="hljs-keyword">Quit</span> <span class="hljs-built_in">$$$OK</span>
}
}
使用 ObjectScript 通过 FHIR 资源创建 SDA
在上一个示例中,SDA 文档是借助互操作性框架通过 FHIR 生成的。 在本节中,我们将直接使用 ObjectScript 实现从 FHIR 到 SDA 的转换。
在您收到以请求形式发送到 IRIS 中的 FHIR 资源/捆绑包后,立即将 FHIR JSON 转换为 SDA 容器:
- 将 InterSystems %DynamicObject AKA JSON 转换为 %Stream 对象。
- 通过 HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3 类执行 TransformStream 方法,这会以响应形式返回 SDA 容器对象。
ClassMethod CreateSDAFromFHIRJSON()
{
try {
set patientStream = ##Class(%Stream.GlobalCharacter).%New()
do patientStream.Write({"resourceType":"Patient","name":[{"use":"official","family":"ashok te","given":["Sidharth"]}],"gender":"male","birthDate":"1997-09-08","telecom":[{"system":"phone","value":"1234566890","use":"mobile"},{"system":"email","value":"tornado1212@gmail.com"}],"address":[{"line":["Some street"],"city":"Manipal1","state":"Karnataka1","postalCode":"1234561"}]}.%ToJSON())
#dim SDAObj As HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3 = ##class(HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3).TransformStream(patientStream,"R4","JSON")
set SDAContainer = SDAObj.container
<span class="hljs-comment">; XML-based SDA output</span>
<span class="hljs-keyword">write</span> SDAContainer.XMLExport()
}
<span class="hljs-keyword">catch</span> ex {
<span class="hljs-keyword">write</span> ex.DisplayString()
}
}
FHIR XML 转换为 SDA 容器。
- 将 XML 转换为 %Stream 对象。
- 通过 HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3 类执行 TransformStream 方法,这会以响应形式返回 SDA 容器对象。
ClassMethod CreateSDAFromFHIRXML()
{
try {
set patientXML = "<Patient xmlns=""http://hl7.org/fhir""><id value=""example""/><text><status value=""generated""/><div xmlns=""http://www.w3.org/1999/xhtml""><p>John Doe</p></div></text><identifier><use value=""usual""/><type><coding><system value=""http://terminology.hl7.org/CodeSystem/v2-0203""/><code value=""MR""/></coding></type><system value=""http://hospital.smarthealth.org""/><value value=""123456""/></identifier><name><use value=""official""/><family value=""Doe""/><given value=""John""/></name><gender value=""male""/><birthDate value=""1980-01-01""/></Patient>"set patientStream = ##Class(%Stream.GlobalCharacter).%New()
do patientStream.Write(patientXML)
#dim SDAObj As HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3 = ##class(HS.FHIR.DTL.Util.API.Transform.FHIRToSDA3).TransformStream(patientStream,"R4","XML")
set SDAContainer = SDAObj.container
<span class="hljs-comment">; XML-based SDA output</span>
<span class="hljs-keyword">write</span> SDAContainer.XMLExport()
}
<span class="hljs-keyword">catch</span> ex {
<span class="hljs-keyword">write</span> ex.DisplayString()
}
}
按照上文详细介绍的步骤,您可以在数据与 FHIR 资源之间进行无缝转换。
其他内置的 FHIR 仓库和 FHIR 装饰选项是公开符合 FHIR 标准的系统、高效处理和存储 FHIR 资源的重要工具。





.jpg)
.png)